

Creating a Powerful AI Fraud Detection Model with Random Forest and XGBoost
Introduction
Fraud in financial transactions is a growing problem, costing companies and individuals billions every year. Fortunately, AI fraud detection has become one of the most effective tools to tackle this issue. Allowing businesses to catch suspicious activities early and prevent financial damage. But how exactly does AI make fraud detection smarter and more efficient?
In this blog post, we’ll walk you through building your own AI-powered fraud detection model. For this, we are going to use two popular machine-learning algorithms: Random Forest and XGBoost. These advanced algorithms not only help in identifying fraudulent transactions with high accuracy, but they also work in real-time. We are making them perfect for banks and financial institutions.
We’ll provide you with the complete source code (along with output) that showcases how these models work and highlights how you can apply them to any financial dataset to detect unusual behavior.
By the end of this post, you’ll have a working fraud detection model that you can implement in real-world scenarios, improving security and reducing fraud risks. Whether you’re new to AI or looking to enhance your existing systems, this guide is designed to give you everything you need to get started.
Ready to protect your financial systems using AI? Let’s dive in!
What is AI Fraud Detection and Why is it Important?
AI fraud detection refers to the use of artificial intelligence to automatically identify fraudulent activities, especially in sectors like finance. In today’s digital world, where transactions are happening at lightning speed, financial fraud has become more sophisticated, making it harder to catch through traditional methods. AI for financial fraud detection steps in to monitor patterns, detect anomalies, and stop potential fraud before it escalates.
But why is this important? Because fraud doesn’t just cost money—it erodes trust. Businesses lose their credibility, and customers start questioning the safety of their own financial data. The ability of AI to detect fraud in real-time is changing the game, offering businesses a way to stay ahead of cybercriminals.
How AI is Revolutionizing Fraud Detection
AI is revolutionizing fraud detection by analyzing vast amounts of data far quicker than humans ever could. In the past, fraud detection often relied on manual processes. Human analysts would go through transactions, trying to spot irregularities—something that was time-consuming and prone to errors. Now, with AI models, machine learning algorithms automatically scan millions of transactions, flagging anything suspicious in real time.
For example, a convolutional neural network (CNN) could be used to analyze patterns in financial transactions. By recognizing patterns in historical data, the algorithm can identify outliers that might suggest fraud. Here’s a simple Python code example that uses a basic machine learning model to predict fraudulent activity:
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score
import pandas as pd
# Load dataset (replace with your dataset path)
data = pd.read_csv("financial_data.csv")
# Check if 'is_fraud' column exists
if 'is_fraud' not in data.columns:
print("Error: 'is_fraud' column not found in the dataset. Available columns are:")
print(data.columns)
else:
# Assume 'is_fraud' is the target variable (0 = No Fraud, 1 = Fraud)
X = data.drop('is_fraud', axis=1)
y = data['is_fraud']
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Train a Random Forest Classifier
model = RandomForestClassifier()
model.fit(X_train, y_train)
# Predict and calculate accuracy
predictions = model.predict(X_test)
print(f"Accuracy: {accuracy_score(y_test, predictions) * 100:.2f}%")
In this code, the machine learning model identifies fraud by learning from previous transaction data. AI can easily process thousands of such transactions at once, allowing companies to catch fraud faster than a human would.
The Growing Threat of Financial Fraud
The threat of financial fraud is growing, and it’s a battle everyone is fighting. As more businesses move online, and people conduct their financial transactions digitally, the opportunities for fraud increase. Whether it’s credit card fraud, identity theft, or phishing attacks, criminals are getting more creative.
For instance, in 2020 alone, the Federal Trade Commission reported losses amounting to $3.3 billion due to fraud. This figure keeps rising each year as fraudsters adopt more advanced techniques to bypass security measures. That’s where AI comes in as a crucial defense. Without AI-powered fraud detection, businesses would struggle to keep up with the pace of these ever-evolving threats.
Benefits of Using AI in Fraud Detection
Using AI for financial fraud detection comes with many benefits. Here’s why more and more companies are relying on AI security solutions to fight fraud:
- Speed and Efficiency: AI can analyze large amounts of data in seconds. Traditional methods might take hours or days. With real-time monitoring, fraud can be flagged and prevented almost instantly.
- Accuracy: Human error is inevitable, but AI reduces false positives by learning from historical data. This means fewer innocent transactions get flagged as fraud, and actual fraud is detected more accurately.
- Adaptability: Fraud patterns constantly evolve, but AI models can learn and adapt over time. Using machine learning techniques, AI improves its fraud-detection capabilities as it gathers more data.
- Cost-Effectiveness: Stopping fraud early saves businesses millions of dollars in potential losses. By investing in AI security solutions, companies can lower their costs related to manual fraud detection processes.
- Better Customer Experience: With AI reducing false positives, customers aren’t frustrated by unnecessary transaction blocks. It ensures a smoother experience, building trust in the business.
Setting Up Your AI Fraud Detection Model
Setting up an AI fraud detection model might seem Vast, but with the right tools and steps, it can become an easy process. In this section, we’ll walk through how to get started with two popular algorithms for detecting fraud: Random Forest and XGBoost. These are powerful tools used in AI fraud detection because they can process large amounts of data quickly and with great accuracy.
By following this guide, you’ll learn how to build a fraud detection model from scratch, including how to set up your Python environment and install the necessary libraries. Don’t worry if you’re new to this! We’ll explain everything step-by-step.

Getting Started with Random Forest and XGBoost for Fraud Detection
Random Forest and XGBoost are widely used algorithms for AI fraud detection because they can handle complex data with ease. Random Forest works by creating multiple decision trees and then averaging their predictions. XGBoost, on the other hand, is a more advanced algorithm that focuses on improving the accuracy of each prediction by learning from the mistakes of previous models.
These algorithms are great for detecting fraud because they can handle a large number of variables and can easily spot unusual patterns that might indicate fraudulent activity. For instance, if a credit card is being used in two different countries at the same time, these models can flag it as suspicious.
Required Tools and Libraries
Before diving into the technical details, it’s essential to have the right tools and libraries for AI fraud detection. Here’s a list of what you’ll need:
- Python: Python is the most popular programming language for AI projects due to its simplicity and the wide range of libraries available.
- Scikit-Learn: This is a powerful library for machine learning, including the Random Forest algorithm.
- XGBoost: A high-performance library specifically designed for boosting algorithms.
- Pandas: Useful for handling and processing data.
- NumPy: Required for numerical computations.
These libraries will help you build and train your model without much hassle. They’re also well-documented, making them perfect for beginners.
Installing Scikit-Learn and XGBoost
Now that we know what tools are needed, the next step is to install the necessary libraries.
Here’s how you can install Scikit-Learn and XGBoost on your system:
# Install Scikit-Learn
pip install scikit-learn
# Install XGBoost
pip install xgboost
If you haven’t already installed Pandas or NumPy, you can do so with the following commands:
pip install pandas numpy
Once you have these libraries installed, you’re ready to start building your fraud detection model.
Setting Up Your Python Environment for AI Projects
When starting any AI project, it’s important to set up your Python environment correctly. This ensures that your project will run smoothly and that all the necessary fraud detection algorithms in Python will work as expected.
First, I recommend creating a virtual environment. This helps keep your dependencies isolated, avoiding any conflicts between libraries. To create a virtual environment, run:
# Create a virtual environment
python -m venv fraud_detection_env
# Activate the environment
# On Windows:
fraud_detection_env\Scripts\activate
# On macOS/Linux:
source fraud_detection_env/bin/activate
Once your environment is activated, install the required libraries mentioned earlier. By using a virtual environment, you ensure that your Python for AI projects run consistently, regardless of other projects you may be working on.
Must Read
- ML Model Monitoring: How to Detect Data Drift and Model Decay in Production
- Retrain vs Fine-Tune vs Train from Scratch: A Decision Framework for ML Engineers
- Continual Learning in PyTorch: A Practical Guide for ML Engineers
- Online Learning Machine Learning: Building Real-Time Streaming Systems in Python
- How to Prevent Catastrophic Forgetting in PyTorch (Complete Guide)
Understanding the Financial Dataset
Preparing a Financial Dataset for Fraud Detection
When you’re building a fraud detection model, the preparation of your financial dataset is one of the most important steps. In fraud detection, your model’s success relies heavily on how well you handle the data. This involves cleaning the dataset, preprocessing data for fraud detection models, handling imbalances, and selecting the right features.
Let’s break this down step-by-step, so you can see exactly why each part of the process is essential and how to do it correctly.
The Importance of Data Preprocessing
Before training any AI model, preprocessing data for fraud detection models is essential. Real-world data is often messy, containing missing values, outliers, or inconsistent formats. If your data isn’t cleaned and preprocessed, your model might make incorrect predictions or completely fail to understand the data patterns.
For example, in financial transactions, some columns might contain null values (perhaps a merchant’s name or transaction description). In this case, it’s crucial to either fill those missing values or drop the columns that are not needed.
Here’s a simple code snippet to show how missing values are handled:
import pandas as pd
# Load your dataset
data = pd.read_csv("financial_data.csv")
# Check for missing values
print(data.isnull().sum())
# Select only numeric columns
numeric_cols = data.select_dtypes(include=['float64', 'int64']).columns
# Fill missing values in numeric columns with their median
data[numeric_cols] = data[numeric_cols].fillna(data[numeric_cols].median())
# Check again for missing values
print(data.isnull().sum())
This small step can make a huge difference in improving your model’s accuracy. Preprocessing data helps your model understand the data correctly and spot fraudulent activity more effectively.
Handling Imbalanced Datasets in Fraud Detection
One of the biggest challenges in fraud detection is handling imbalanced datasets. In most cases, the number of fraudulent transactions is much smaller compared to legitimate ones. This imbalance can lead to a model that performs poorly because it learns to favor the majority class (legitimate transactions), ignoring the minority class (fraudulent transactions).
To address this, there are several techniques you can use:
- Resampling: This involves either oversampling the minority class or undersampling the majority class. Libraries like
imbalanced-learnprovide easy methods for this. - Class Weights: Another approach is to assign higher weights to the minority class during model training, forcing the model to pay more attention to fraudulent transactions.
Here’s how you can handle imbalanced datasets using oversampling:
import pandas as pd
from imblearn.over_sampling import SMOTE
from sklearn.model_selection import train_test_split
# Load your dataset (update the file path as necessary)
data = pd.read_csv('financial_data.csv')
# Check if 'is_fraud' column exists
if 'is_fraud' in data.columns:
# Split data into features and target
X = data.drop('is_fraud', axis=1)
y = data['is_fraud']
# Apply SMOTE for oversampling
sm = SMOTE(random_state=42)
X_res, y_res = sm.fit_resample(X, y)
# Split the resampled data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X_res, y_res, test_size=0.3, random_state=42)
print("Data splitting and SMOTE completed successfully!")
else:
print("The 'is_fraud' column does not exist in the dataset.")
This helps balance the dataset, ensuring that your model can learn from both the fraudulent and legitimate transactions effectively.
Feature Selection and Feature Engineering for Fraud Detection
Choosing the right features is critical when preparing data for any fraud detection model. Feature selection involves identifying which variables (features) are the most important for predicting fraud. This helps simplify the model and reduces noise in the data.
Feature engineering, on the other hand, is the process of creating new features from existing ones to improve your model’s performance. In fraud detection, features like transaction amount, time of day, and location are often crucial indicators of fraudulent behavior.
Here’s a code example for feature selection using RandomForest:
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
# Train a RandomForest model to rank feature importance
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Get feature importances
importances = model.feature_importances_
# Create a DataFrame for visualization
feature_importances = pd.DataFrame({'Feature': X_train.columns, 'Importance': importances})
feature_importances.sort_values(by='Importance', ascending=False, inplace=True)
# Display the most important features
print(feature_importances.head())
In this example, you can identify which features have the most impact on predicting fraud. You might discover that transaction amount, time, or location are the most important indicators.
Example Financial Transaction Dataset Overview
When working with fraud detection datasets, you’ll typically see datasets that contain information such as transaction ID, amount, date, time, and whether or not the transaction was flagged as fraudulent. Here’s a simple overview of what such a dataset might look like:
| Transaction ID | Amount | Date | Time | Location | Is Fraud |
|---|---|---|---|---|---|
| 123456 | $250 | 2023-01-01 | 12:00 | New York | 0 |
| 123457 | $5000 | 2023-01-02 | 14:15 | London | 1 |
| 123458 | $30 | 2023-01-02 | 09:45 | Tokyo | 0 |
| 123459 | $1200 | 2023-01-03 | 16:30 | Sydney | 1 |
In this financial transaction dataset, each row represents a transaction, and the Is Fraud column indicates whether it was fraudulent (1) or not (0).
When preparing your AI dataset for fraud detection, it’s important to clean and preprocess these columns effectively. For example, you might convert the Date and Time columns into more useful features like the time of day (morning, afternoon, evening) or day of the week (weekday, weekend).
A simple code snippet to preprocess these columns might look like this:
# Convert Date and Time into more useful features
data['Date'] = pd.to_datetime(data['Date'])
data['DayOfWeek'] = data['Date'].dt.dayofweek
data['HourOfDay'] = pd.to_datetime(data['Time'], format='%H:%M').dt.hour
# Drop unnecessary columns
data.drop(['Transaction ID', 'Date', 'Time'], axis=1, inplace=True)
This helps create meaningful features for your model, making it easier for the algorithm to detect patterns related to fraudulent activity.
Building a Fraud Detection Model Using Random Forest
How to Build a Fraud Detection Model with Random Forest
In this section, we’ll build a fraud detection model using Random Forest and walk through every step—from understanding the algorithm to analyzing its performance. Fraud detection often deals with imbalanced data, and Random Forest is one of the most effective algorithms for handling such datasets.
What is Random Forest and How It Works?
A Random Forest is an ensemble learning method that combines multiple decision trees to make predictions. In fraud detection, this approach is highly effective because it aggregates the results from many trees to make a final decision, reducing the risk of overfitting and improving accuracy.
Here’s a simple analogy: think of Random Forest as a group of experts (trees) voting on a decision. Each expert provides an opinion, and the final decision is based on the majority vote.
In fraud detection, Random Forest works by creating many decision trees during training. Each tree makes predictions based on different subsets of the data. The combined result from all the trees is then used to classify whether a transaction is fraudulent or not.
Here’s a basic explanation of the process:
- Bootstrap Sampling: Randomly sample data with replacement to create multiple subsets of the original dataset.
- Decision Trees: Build a decision tree for each subset. Each tree uses different features for making decisions.
- Voting: Combine the results from all decision trees to make the final prediction. The majority vote determines the classification.
Understanding how Random Forest works in fraud detection can help you appreciate its effectiveness in handling complex datasets with many features.
Implementing Random Forest in Python
Now that you have a grasp of how Random Forest works, let’s see how to implement it using Python. We will use the scikit-learn library, which provides an easy-to-use interface for building Random Forest models.
Here’s a complete walkthrough of the implementation:
1. Import Libraries and Load Data
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix
# Load your dataset
data = pd.read_csv("financial_data.csv")
# Prepare features and target variable
X = data.drop('is_fraud', axis=1)
y = data['is_fraud']
This code snippet prepares the data for machine learning:
- Imports necessary libraries: These libraries will be used for data handling, model training, and evaluation.
- Loads the dataset: Reads the data from a CSV file into a DataFrame.
- Prepares the data: Splits the DataFrame into features (
X) and the target variable (y), which will be used for model training and prediction.
This setup is essential for training a machine learning model, such as a RandomForestClassifier, to predict whether a financial transaction is fraudulent based on the features in the dataset.
2. Split the Data
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
This line of code splits the dataset into training and testing sets. X_train and y_train are used for training the model, while X_test and y_test are used to evaluate its performance. test_size=0.3 indicates that 30% of the data is reserved for testing, and random_state=42 ensures the split is reproducible.
3. Train the Random Forest Model
# Create and train the Random Forest model
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
This code creates a RandomForestClassifier model with 100 trees (n_estimators=100) and a fixed random seed (random_state=42) to ensure consistent results. It then trains the model using the training data (X_train and y_train).
4. Make Predictions
# Predict on the test set
y_pred = model.predict(X_test)
This line uses the trained Random Forest model to make predictions on the test set (X_test). The predicted values are stored in y_pred, which represents the model’s output for the test data.
5. Evaluate Model Performance
# Evaluate the model
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
print(f"Precision: {precision:.2f}")
print(f"Recall: {recall:.2f}")
print("Confusion Matrix:")
print(conf_matrix)
This code evaluates the performance of the Random Forest model using several metrics:
- Accuracy: Measures the proportion of correct predictions among all predictions.
- Precision: Indicates the proportion of true positives among all positive predictions made by the model.
- Recall: Shows the proportion of true positives identified out of all actual positives.
- Confusion Matrix: Displays a table showing the counts of true positives, false positives, true negatives, and false negatives.
The print statements display these metrics, providing insights into how well the model performed.
Complete Source Code for Random Forest Model
Here’s the complete code snippet for building and evaluating a Random Forest model:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix
# Load dataset
data = pd.read_csv("financial_data.csv")
# Quick overview of the data
print(data.head())
print(data.info())
# Features and target
X = data.drop('isFraud', axis=1)
y = data['isFraud']
# Visualizing target variable distribution
plt.figure(figsize=(6, 4))
sns.countplot(x='isFraud', data=data)
plt.title('Distribution of Fraud vs Non-Fraud Cases')
plt.show()
# Exclude non-numeric columns for correlation matrix
numeric_data = data.select_dtypes(include=['float64', 'int64'])
# Correlation matrix to understand feature relationships
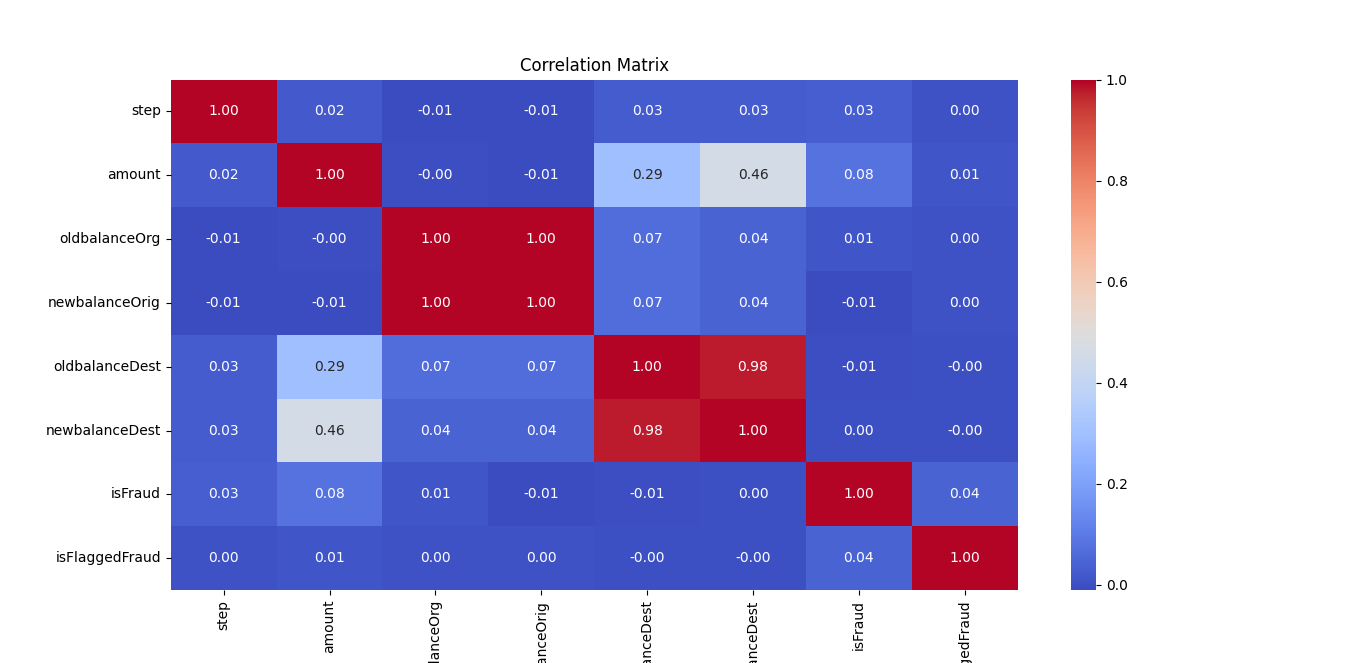
plt.figure(figsize=(10, 8))
corr_matrix = numeric_data.corr()
sns.heatmap(corr_matrix, annot=True, cmap='coolwarm', fmt=".2f")
plt.title('Correlation Matrix')
plt.show()
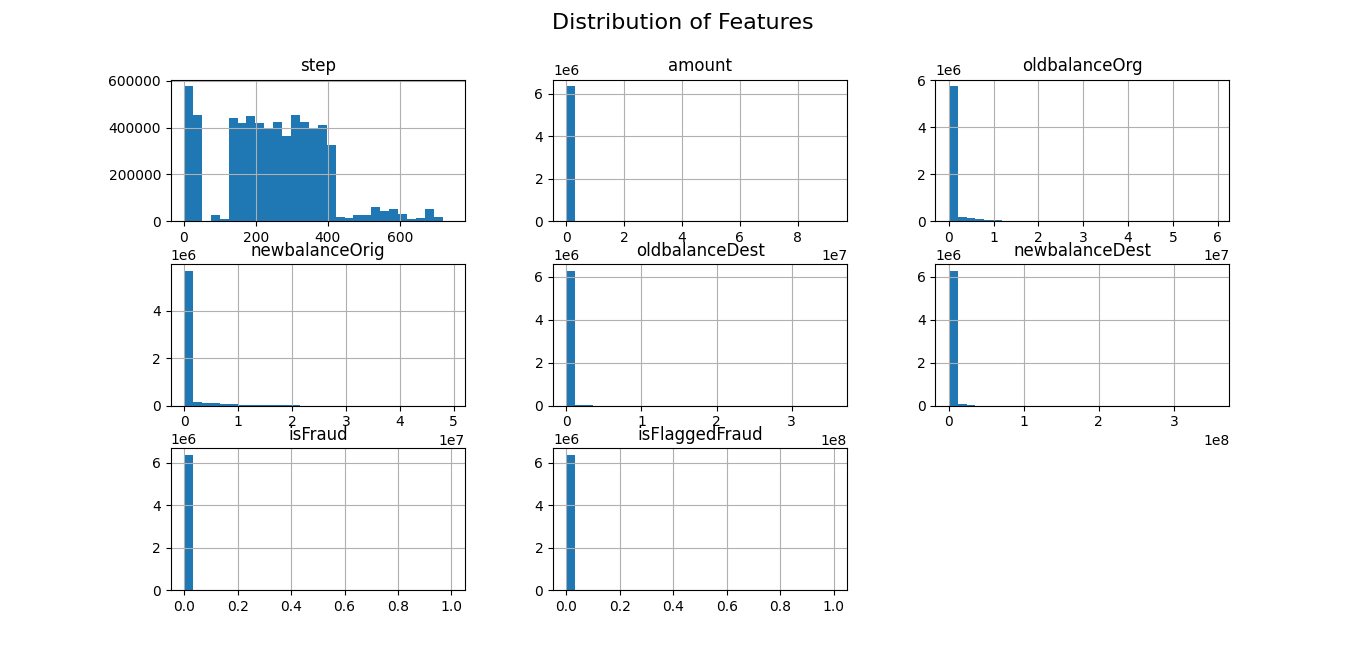
# Visualizing feature distributions
data.hist(bins=30, figsize=(20, 15))
plt.suptitle('Distribution of Features', fontsize=16)
plt.show()
# Train-test split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# Initialize and train Random Forest model
model = RandomForestClassifier(n_estimators=100, random_state=42)
model.fit(X_train, y_train)
# Make predictions
y_pred = model.predict(X_test)
# Evaluation
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
# Print the evaluation results
print(f"Accuracy: {accuracy:.2f}")
print(f"Precision: {precision:.2f}")
print(f"Recall: {recall:.2f}")
# Visualizing confusion matrix
plt.figure(figsize=(6, 4))
sns.heatmap(conf_matrix, annot=True, fmt='d', cmap='Blues', cbar=False)
plt.title('Confusion Matrix')
plt.xlabel('Predicted')
plt.ylabel('Actual')
plt.show()
Output:

Evaluating Model Performance: Accuracy, Precision, Recall
When assessing your Random Forest model, you’ll want to look at several metrics:
- Accuracy measures how many predictions were correct out of all predictions.
- Precision tells you how many of the predicted frauds were actually frauds.
- Recall indicates how many of the actual frauds were correctly identified by the model.
These metrics help you understand how well your model is performing and where it might need improvement.
Understanding the Confusion Matrix for Fraud Detection
The confusion matrix provides a detailed breakdown of your model’s performance. It shows:
- True Positives (TP): Correctly predicted frauds.
- False Positives (FP): Transactions incorrectly predicted as frauds.
- True Negatives (TN): Correctly predicted non-frauds.
- False Negatives (FN): Transactions that were frauds but were predicted as non-frauds.
Here’s an example of how to interpret a confusion matrix:
Confusion Matrix:
[[TN, FP],
[FN, TP]]
Understanding this matrix helps you assess where your model might be making errors and how you might improve it.
Random Forest Output Analysis
In my experience, analyzing the output from a Random Forest model can reveal a lot about how well the model is performing. For instance, if you see high precision but low recall, your model might be good at identifying frauds but missing many cases. On the other hand, high recall with low precision might indicate that the model is too lenient and is flagging too many transactions as fraudulent.
It’s important to balance these metrics based on your specific needs. For fraud detection, you might prioritize recall to ensure that as many fraudulent transactions as possible are caught, even if it means accepting some false positives.
In summary, building a fraud detection model with Random Forest involves understanding how the algorithm works, implementing it in Python, and thoroughly evaluating its performance. With these steps, you’ll be well on your way to developing an effective model to combat fraud.
Using XGBoost for Enhanced Accuracy
Boosting AI Fraud Detection Accuracy with XGBoost
When it comes to enhancing the accuracy of fraud detection models, XGBoost is a powerful tool. It stands out for its efficiency and effectiveness in handling complex datasets and delivering high performance. In this section, we’ll explore why XGBoost is a great choice for AI Fraud Detection and guide you through building an XGBoost model step by step.
Why XGBoost is Great for Fraud Detection
XGBoost (Extreme Gradient Boosting) is a machine learning technique that has gained popularity for its remarkable performance in predictive modeling. Here’s why it’s particularly well-suited for financial fraud detection and AI models for fraud prevention:
- Performance: XGBoost often outperforms other algorithms in terms of accuracy and speed. It uses gradient boosting to combine multiple weak models (decision trees) into a strong one. This method helps in making accurate predictions by focusing on the errors of previous models.
- Handling Imbalanced Data: AI Fraud Detection datasets are often imbalanced, meaning there are many more non-fraudulent transactions than fraudulent ones. XGBoost has features that help manage this imbalance, such as weighting the importance of different classes.
- Feature Importance: XGBoost provides insights into which features are most important for predicting fraud. This can help in understanding what factors contribute most to fraud, allowing for better decision-making and model refinement.
Step-by-Step Guide to Building an XGBoost Model
Let’s walk through the process of creating an XGBoost model for AI Fraud Detection. We’ll cover the entire workflow from setting up your environment to evaluating the model’s performance.
1. Import Libraries and Load Data
Start by importing the necessary libraries and loading your dataset:
import pandas as pd
import xgboost as xgb
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, precision_score, recall_score, confusion_matrix
# Load dataset
data = pd.read_csv("financial_data.csv")
# Prepare features and target variable
X = data.drop('is_fraud', axis=1)
y = data['is_fraud']
Here’s a brief explanation of the code:
- Import Libraries: Essential libraries are imported:
pandasfor data manipulation,xgboostfor the XGBoost model,train_test_splitfromsklearnfor splitting data,accuracy_score,precision_score,recall_score, andconfusion_matrixfromsklearnfor model evaluation.
- Load Dataset: The dataset
financial_data.csvis loaded into a DataFrame calleddata. - Prepare Features and Target:
Xcontains the feature columns by dropping theis_fraudcolumn.yis the target variable, which is theis_fraudcolumn.
This sets up the data for training and evaluating a machine learning model.
2. Split the Data
Divide the data into training and testing sets:
# Split data into training and testing sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
This code splits the dataset into training and testing sets. train_test_split randomly divides the features (X) and target (y) into training data (70%) and testing data (30%). The random_state=42 ensures reproducibility by controlling the random splitting process.
3. Train the XGBoost Model
Create and train the XGBoost model:
# Initialize and train the XGBoost model
model = xgb.XGBClassifier(use_label_encoder=False, eval_metric='mlogloss')
model.fit(X_train, y_train)
This code initializes an XGBoost classifier with default settings, while disabling the deprecation warning (use_label_encoder=False) and setting the evaluation metric to mlogloss. It then trains the model using the training data (X_train and y_train).
4. Make Predictions
Use the model to make predictions on the test set:
# Predict on the test set
y_pred = model.predict(X_test)
This line uses the trained XGBoost model to make predictions on the test data (X_test). The predicted values are stored in y_pred, which will be used for evaluating the model’s performance.
5. Evaluate Model Performance
Assess the performance of your model:
# Evaluate the model
accuracy = accuracy_score(y_test, y_pred)
precision = precision_score(y_test, y_pred)
recall = recall_score(y_test, y_pred)
conf_matrix = confusion_matrix(y_test, y_pred)
print(f"Accuracy: {accuracy:.2f}")
print(f"Precision: {precision:.2f}")
print(f"Recall: {recall:.2f}")
print("Confusion Matrix:")
print(conf_matrix)
This block of code evaluates the performance of the XGBoost model:
accuracy_score(y_test, y_pred): Calculates the proportion of correct predictions out of the total predictions.precision_score(y_test, y_pred): Measures the proportion of true positive predictions among all positive predictions made by the model.recall_score(y_test, y_pred): Measures the proportion of true positive predictions among all actual positives.confusion_matrix(y_test, y_pred): Computes a matrix showing the counts of true positives, false positives, true negatives, and false negatives.
The results are printed to give an overview of the model’s performance.
Evaluating XGBoost Model Performance
Evaluating the performance of your XGBoost model involves looking at several key metrics:
- Accuracy: Measures the proportion of correctly classified instances.
- Precision: Indicates how many of the predicted frauds were actually frauds.
- Recall: Shows how many of the actual frauds were detected by the model.
These metrics help in understanding how effectively your model identifies fraudulent transactions. For fraud detection, you might prioritize recall to ensure that as many frauds as possible are caught, even if it means accepting a few false positives.
Comparing XGBoost and Random Forest in AI Fraud Detection
Both XGBoost and Random Forest are excellent for fraud detection, but they have different strengths:
- XGBoost is generally more accurate and faster, especially with large datasets. It handles imbalances better and provides more detailed feature importance.
- Random Forest is easier to implement and understand but might not always match XGBoost’s performance on complex datasets.
Choosing between them often depends on the specific needs of your project. For instance, if you need high accuracy and can handle more complexity, XGBoost might be the better choice.
XGBoost Output Analysis
Analyzing the output of your XGBoost model involves interpreting the performance metrics and confusion matrix. Here’s what to look for:
- High Accuracy: Indicates that the model is generally performing well.
- High Precision: Shows that most predicted frauds are indeed frauds.
- High Recall: Means the model is catching most of the actual frauds.
In summary, using XGBoost for financial AI Fraud Detection can significantly enhance your model’s performance. By following the steps outlined above, you can build a powerful fraud detection model, evaluate its effectiveness, and compare it to other methods like Random Forest.
Advanced Techniques for Improving AI Fraud Detection
Latest Advancements in AI Fraud Detection
In the world of AI fraud detection, technology is evolving rapidly. New methods and techniques are making it possible to catch fraudulent activities more accurately and in real-time. This section explores some of the latest advancements, including deep learning, real-time fraud detection, and anomaly detection techniques.
Exploring Deep Learning for AI Fraud Detection
Deep learning is revolutionizing how we detect fraud. It uses advanced neural networks to analyze data in ways that traditional methods cannot. Here’s a closer look at how neural networks contribute to fraud prevention:
1. Neural Networks and Their Role in Fraud Prevention
Neural networks are a key component of deep learning. They consist of layers of interconnected nodes (or neurons) that process data. Each layer extracts different features, allowing the network to learn complex patterns.
For AI Fraud Detection, neural networks can handle large volumes of data and identify subtle patterns that may indicate fraudulent behavior. They are particularly useful when dealing with unstructured data, like text from transaction descriptions.
Example: AI Fraud Detection with Neural Networks
Here’s a simple example of how you might use a neural network for AI Fraud Detection in Python using TensorFlow:
import tensorflow as tf
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
import pandas as pd
# Load and prepare the data
data = pd.read_csv("financial_data.csv")
X = data.drop('is_fraud', axis=1)
y = data['is_fraud']
# Standardize the data
scaler = StandardScaler()
X_scaled = scaler.fit_transform(X)
# Split data
X_train, X_test, y_train, y_test = train_test_split(X_scaled, y, test_size=0.3, random_state=42)
# Build the neural network
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(X_train.shape[1],)),
tf.keras.layers.Dense(32, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])
model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['accuracy'])
# Train the model
model.fit(X_train, y_train, epochs=10, batch_size=32)
# Evaluate the model
y_pred = (model.predict(X_test) > 0.5).astype("int32")
accuracy = accuracy_score(y_test, y_pred)
print(f"Neural Network Accuracy: {accuracy:.2f}")
This code sets up a basic neural network for fraud detection, trains it on your data, and evaluates its performance.
2. Hybrid AI Models Combining Random Forest and XGBoost
Combining multiple AI models can enhance fraud detection accuracy. Hybrid models use the strengths of different algorithms to create a more powerful system. For instance, Random Forest and XGBoost can be combined to leverage their individual strengths.
Example: Combining Random Forest and XGBoost
Here’s a high-level approach to combining Random Forest and XGBoost:
from sklearn.ensemble import RandomForestClassifier
from sklearn.ensemble import VotingClassifier
# Initialize the models
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
xgb_model = xgb.XGBClassifier(use_label_encoder=False, eval_metric='mlogloss')
# Create a voting classifier
voting_model = VotingClassifier(estimators=[
('rf', rf_model),
('xgb', xgb_model)
], voting='soft')
# Train the combined model
voting_model.fit(X_train, y_train)
# Evaluate
y_pred = voting_model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
print(f"Combined Model Accuracy: {accuracy:.2f}")
This example uses a voting classifier to combine Random Forest and XGBoost. The combined model can often provide better performance than any single model.
Real-Time Fraud Detection Using AI and Machine Learning
Real-time fraud detection is crucial for preventing financial losses as they occur. Modern AI solutions are designed to analyze transactions and detect fraud instantly.
1. How Financial Institutions are Using AI to Prevent Fraud in Real Time
Financial institutions are increasingly using AI in banking fraud prevention to monitor transactions in real-time. AI systems analyze transaction patterns and flag suspicious activity as it happens. For example, if a transaction deviates from a user’s typical behavior, the system can instantly alert the user or block the transaction.
Example: Real-Time Fraud Detection Workflow
A real-time fraud detection system might work as follows:
- Data Collection: Collect transaction data from various sources.
- Data Processing: Preprocess and analyze the data using AI models.
- Anomaly Detection: Apply models to detect deviations from normal behavior.
- Alerting: Trigger alerts or block transactions when suspicious activity is detected.
Using Anomaly Detection Techniques for Identifying Rare Fraud Cases
Anomaly detection is a technique used to find rare fraud cases that deviate from normal patterns. It’s particularly useful for identifying new or unusual types of fraud that don’t fit established patterns.
1. AI Anomaly Detection for Fraud Cases
AI anomaly detection techniques analyze transaction data to spot unusual behavior. They use statistical methods and machine learning to identify patterns that are different from what is considered normal.
Example: Anomaly Detection in Python
Here’s a simple example using the Isolation Forest algorithm for anomaly detection:
from sklearn.ensemble import IsolationForest
# Initialize and train the Isolation Forest model
iso_forest = IsolationForest(contamination=0.01, random_state=42)
iso_forest.fit(X_train)
# Predict anomalies
y_pred = iso_forest.predict(X_test)
# Convert prediction to binary format
y_pred = [1 if x == -1 else 0 for x in y_pred]
# Evaluate
accuracy = accuracy_score(y_test, y_pred)
print(f"Anomaly Detection Accuracy: {accuracy:.2f}")
This code sets up an Isolation Forest model to detect anomalies in the dataset. Anomalies are flagged and can be further investigated for potential fraud.
Advancements in AI fraud detection are making it easier to catch fraudulent activities quickly and accurately. Deep learning and hybrid AI models are enhancing our ability to detect fraud, while real-time detection systems and anomaly detection techniques are helping to identify and prevent fraud as it happens.
Tuning and Optimizing Your AI Fraud Detection Model
How to Tune Your AI AI Fraud Detection for Better Performance
In the world of AI, tuning your model can make a significant difference in performance. It’s all about adjusting your model to get the best possible results. This section will walk you through key techniques for tuning your AI models, focusing on hyperparameter tuning, cross-validation, and feature importance.
Hyperparameter Tuning for Random Forest and XGBoost
Hyperparameter tuning is a crucial step in optimizing AI Fraud Detection models. Hyperparameters are settings that you can adjust to improve your model’s performance. They are not learned from the data but are set before the training process begins.
1. Hyperparameter Optimization for Fraud Detection Models
For Random Forest and XGBoost, there are several important hyperparameters to consider:
- Random Forest:
n_estimators: Number of trees in the forest.max_depth: Maximum depth of each tree.min_samples_split: Minimum number of samples required to split an internal node.
- XGBoost:
n_estimators: Number of boosting rounds.learning_rate: Step size for each boosting round.max_depth: Maximum depth of each tree.subsample: Fraction of samples used for fitting the trees.
Example: Hyperparameter Tuning with GridSearchCV
Here’s how you can use GridSearchCV to tune hyperparameters for a Random Forest model:
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
# Initialize the Random Forest model
rf_model = RandomForestClassifier()
# Define the parameter grid
param_grid = {
'n_estimators': [100, 200],
'max_depth': [10, 20],
'min_samples_split': [2, 5]
}
# Setup GridSearchCV
grid_search = GridSearchCV(estimator=rf_model, param_grid=param_grid, cv=3, scoring='accuracy')
# Fit GridSearchCV
grid_search.fit(X_train, y_train)
# Best parameters and score
print("Best Parameters:", grid_search.best_params_)
print("Best Score:", grid_search.best_score_)
This code will help you find the best combination of hyperparameters for your Random Forest model by testing different options and evaluating their performance.
Using Cross-Validation to Improve Accuracy
Cross-validation is a technique used to assess how well your model generalizes to new data. It helps ensure that your model performs well not just on the training data but also on unseen data.
1. How Cross-Validation Works
Cross-validation involves splitting your data into multiple subsets. The model is trained on some subsets and tested on others. This process is repeated several times, and the results are averaged to get a more reliable estimate of model performance.
Example: Cross-Validation with Scikit-Learn
Here’s an example of using cross-validation to evaluate a Random Forest model:
from sklearn.model_selection import cross_val_score
# Initialize the model
rf_model = RandomForestClassifier(n_estimators=100, max_depth=20, min_samples_split=2)
# Perform cross-validation
scores = cross_val_score(rf_model, X, y, cv=5, scoring='accuracy')
print("Cross-Validation Scores:", scores)
print("Mean Accuracy:", scores.mean())
In this example, the model is evaluated using 5-fold cross-validation. The mean accuracy gives you an overall idea of how well your model is likely to perform on new data.
Feature Importance and How It Impacts Model Accuracy
Feature importance measures how valuable each feature (or variable) is in making predictions. Understanding which features are most important can help you focus on the right variables and improve your model’s accuracy.
1. Assessing Feature Importance
For models like Random Forest and XGBoost, feature importance can be directly obtained and visualized. This helps in identifying which features have the most impact on the model’s predictions.
Example: Feature Importance with Random Forest
Here’s how to get feature importance using a Random Forest model:
import matplotlib.pyplot as plt
import pandas as pd
# Fit the model
rf_model.fit(X_train, y_train)
# Get feature importances
importances = rf_model.feature_importances_
# Create a DataFrame
features = pd.DataFrame({
'Feature': X.columns,
'Importance': importances
})
# Sort by importance
features = features.sort_values(by='Importance', ascending=False)
# Plot feature importances
plt.figure(figsize=(10, 6))
plt.barh(features['Feature'], features['Importance'])
plt.xlabel('Importance')
plt.title('Feature Importances')
plt.show()
This code will plot a bar chart showing the importance of each feature. Features with higher importance have a greater impact on the model’s predictions.
Tuning your AI Fraud Detection model is essential for achieving the best performance. Hyperparameter tuning helps optimize model settings, cross-validation ensures your model generalizes well, and understanding feature importance guides you in refining your features. By applying these techniques, you can enhance your model’s accuracy and effectiveness in detecting fraud.
Evaluating and Deploying Your AI Fraud Detection Model
Testing and Deploying Your AI Fraud Detection Model
Once you’ve built and tuned your AI fraud detection model, the next crucial steps are testing and deploying it. These phases ensure your model performs well in real-world scenarios and integrates smoothly into financial systems. Let’s explore how to handle these steps effectively.
How to Test Your Model for Real-World Application
Testing your AI Fraud Detection model is essential to verify its performance and reliability before deployment. It helps ensure that the model can handle real-world data and scenarios effectively.
1. Testing Your Model’s Performance
Start by evaluating your model using a test dataset that was not seen during training. This gives you an idea of how well your model can generalize to new data.
Example: Testing with a Test Dataset
Here’s how to evaluate your model’s performance using a test dataset:
from sklearn.metrics import classification_report, confusion_matrix
# Make predictions
y_pred = model.predict(X_test)
# Print classification report
print("Classification Report:")
print(classification_report(y_test, y_pred))
# Print confusion matrix
print("Confusion Matrix:")
print(confusion_matrix(y_test, y_pred))
The classification report provides metrics like precision, recall, and F1-score. The confusion matrix shows how many fraud cases were correctly or incorrectly classified. These metrics help you understand the model’s strengths and areas for improvement.
2. Simulating Real-World Scenarios
To ensure your model performs well under real-world conditions, simulate scenarios that reflect actual usage. For example, test the model’s response to new types of fraud or changes in transaction patterns.
Integrating Your AI Model into Financial Systems
Deploying your AI model into a financial system involves integrating it with existing processes and technology. This step ensures that your model can function effectively in a production environment.
1. AI Deployment in Financial Fraud Detection
Integrating an AI model into a financial system requires careful planning and execution. The model should be able to handle live data, interact with other components, and provide actionable insights.
Steps for Deployment:
- API Integration: Deploy your model as a web service or API. This allows other systems to send data to the model and receive predictions.
- Data Flow Management: Ensure that the model receives data in the correct format and that predictions are processed efficiently.
- User Interface: If applicable, create a user interface that allows users to interact with the model and view results.
Example: Deploying a Model with Flask
Here’s a simple example of deploying a model using Flask, a popular Python web framework:
from flask import Flask, request, jsonify
import pickle
app = Flask(__name__)
# Load the trained model
model = pickle.load(open('fraud_model.pkl', 'rb'))
@app.route('/predict', methods=['POST'])
def predict():
data = request.get_json()
prediction = model.predict([data['features']])
return jsonify({'prediction': prediction.tolist()})
if __name__ == '__main__':
app.run(debug=True)
In this example, the model is loaded and used to make predictions based on input features. The Flask app provides an endpoint for making predictions, which can be integrated into financial systems.
Monitoring and Improving Your Model Over Time
Deploying your model is just the beginning. Ongoing monitoring and improvement are essential to maintain its effectiveness.
1. Monitoring Model Performance
Regularly track the model’s performance to ensure it continues to meet expectations. This involves:
- Performance Metrics: Continuously measure accuracy, precision, recall, and other relevant metrics.
- Error Analysis: Review any errors or incorrect predictions to identify potential issues.
Example: Monitoring with Logs
You can log predictions and outcomes to analyze model performance over time. Here’s a simple way to log predictions:
import logging
# Set up logging
logging.basicConfig(filename='model_logs.log', level=logging.INFO)
def log_prediction(features, prediction):
logging.info(f'Features: {features}, Prediction: {prediction}')
This logs each prediction along with the input features, helping you review and analyze model performance.
2. Updating the Model
As new data becomes available or fraud patterns change, update your model accordingly. Regular retraining with fresh data helps maintain accuracy and relevance.
Example: Retraining the Model
# Retrain the model with new data
model.fit(new_X_train, new_y_train)
# Save the updated model
pickle.dump(model, open('updated_fraud_model.pkl', 'wb'))
Retraining with new data and saving the updated model ensures that it adapts to new patterns and remains effective.
Testing and deploying your AI fraud detection model involves evaluating its performance, integrating it into financial systems, and monitoring it over time. By carefully handling these steps, you can ensure that your model performs well and continues to provide valuable insights in detecting and preventing fraud.
Conclusion – AI Fraud Detection
Building an effective AI fraud detection model is an exciting journey that blends cutting-edge technology with practical problem-solving. In this blog post, we’ve explored how to create a powerful fraud detection system using two of the most effective machine learning algorithms: Random Forest and XGBoost.
Understanding the Power of Random Forest and XGBoost
Random Forest and XGBoost are standout algorithms in the world of fraud detection. Random Forest excels at handling large datasets with numerous features, providing a robust method for identifying fraudulent patterns. On the other hand, XGBoost is renowned for its speed and accuracy, often outperforming other models by fine-tuning its parameters and improving performance.
By incorporating these algorithms into your fraud detection model, you gain the ability to handle complex data and uncover subtle patterns that might indicate fraudulent activity.
The Importance of Model Evaluation and Tuning
We also discussed the significance of evaluating your model’s performance. Metrics like accuracy, precision, and recall are crucial in understanding how well your model performs. For example, precision helps you gauge how many of the flagged fraud cases are true positives, while recall measures the model’s ability to identify all potential fraud cases.
Tuning your model’s hyperparameters can make a big difference. This involves adjusting settings like the number of trees in Random Forest or the learning rate in XGBoost to optimize performance. It’s like fine-tuning a musical instrument—small adjustments can lead to significant improvements in how well your model detects fraud.
Real-World Applications and Future Trends
The techniques and models we discussed are not just theoretical; they have real-world applications. Financial institutions use these algorithms to safeguard their transactions and protect against fraud. The adaptability of Random Forest and XGBoost makes them suitable for various types of data and fraud scenarios.
Looking ahead, the field of AI fraud detection is evolving rapidly. Advances in AI and machine learning will continue to enhance these models, making them even more effective at detecting and preventing fraud. As new techniques and tools emerge, staying updated and adapting your approach will be key to maintaining a strong defense against fraud.
Personal Insights and Final Thoughts
Creating a powerful AI fraud detection model is both challenging and rewarding. The journey involves not only understanding and implementing algorithms like Random Forest and XGBoost but also continuously learning and adapting to new developments in the field. The ability to protect your organization from fraudulent activities using advanced AI techniques is incredibly valuable.
As you embark on this journey, remember that every step—from choosing the right algorithms to fine-tuning and evaluating your models—contributes to building a more secure and trustworthy system. With persistence and the right tools, you can effectively combat fraud and safeguard your assets.
Thank you for joining me on this exploration of AI fraud detection. I hope this guide has provided you with valuable insights and practical steps to create a powerful fraud detection model. If you have any questions or need further guidance, feel free to reach out. Your journey into AI fraud detection is just beginning, and the possibilities are exciting!
External Resources
Here are some valuable external resources on creating AI fraud detection models with Random Forest and XGBoost:
“Introduction to Random Forest” – Towards Data Science
Provides a comprehensive overview of Random Forest, including its applications and advantages in various fields, including fraud detection.
“XGBoost: A Scalable Tree Boosting System” – Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining
This paper offers in-depth technical insights into XGBoost, its algorithmic improvements, and its effectiveness in predictive modeling tasks.
FAQs
Random Forest uses multiple decision trees to make predictions, providing robustness and handling large datasets well. XGBoost is a gradient boosting algorithm known for higher accuracy and faster performance through fine-tuning and regularization.
Choose Random Forest for handling large datasets and preventing overfitting. Opt for XGBoost if you need higher accuracy and are prepared to fine-tune hyperparameters for better performance.
Focus on adjusting the learning rate, number of estimators, max depth, subsample rate, and colsample_bytree. Techniques like grid search can help find the best settings.
Use metrics such as accuracy, precision, recall, and the F1 score. The confusion matrix also helps visualize true positives, false positives, true negatives, and false negatives.
Apply resampling methods like oversampling the minority class, use synthetic data generation techniques like SMOTE, or implement cost-sensitive learning to improve detection of rare fraud cases.






Leave a Reply