
A Guide To Web Scraping in Python Using Beautiful Soup
In the digital age, data is gold. Whether you’re a data scientist, an analyst, or a developer, the ability to extract and analyze data from the web is a powerful skill. This is where web scraping comes in. Web scraping allows you to collect data from websites that don’t offer an API or structured data. Through this way, you can collect insights and make data-driven decisions.
In this guide, I’ll show you how to build a Web Scraping in Python Using Beautiful Soup. We’ll start with setting up your environment, then move on to extracting data, and finally, saving it into a document. Let’s get started!
Before we begin, let’s observe our web scraper in action. By the end, you’ll have your own webpage scraper ready to use.
Introduction to Web Scraping in Python
Web scraping is the automated process of extracting information from websites. It is widely used in data analysis, SEO, market research, and more. By automating data extraction, web scraping saves time and helps you collect large amounts of data quickly and efficiently. With Python and BeautifulSoup, you can build powerful web scrapers that sift through HTML content and grab the information you need.
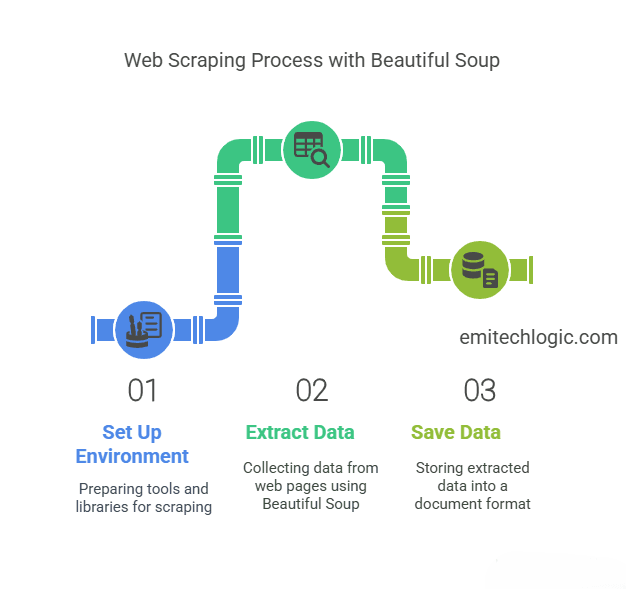
Why Use Python and BeautifulSoup for Web Scraping?
Python is known for its simplicity. This language is a favorite for both beginners and experienced developers. It has a wide range of libraries and frameworks that make web scraping easier. BeautifulSoup is a Python library made for parsing HTML and XML documents. It offers easy-to-use methods for navigating, searching, and modifying the parse tree, making it a perfect tool for web scraping.
Setting Up Your Environment
Before we start building our web scraper, we need to set up our environment. Follow these steps to get ready:
- Install Python: Go to the official Python website, download Python, and install it on your computer.
- Install Required Libraries: We need some libraries for our scraper. Open your terminal and use pip to install BeautifulSoup, requests, and python-docx. Run these commands:
pip install beautifulsoup4
pip install requests
pip install python-docx
Understanding HTML and the DOM

To scrape a website effectively, you need to understand some basics about HTML and the Document Object Model (DOM).
HTML is the standard language for creating web pages. It organizes the content using elements like headings, paragraphs, links, and images.
The DOM is like a map of the HTML. It’s a programming interface that represents the page, allowing programs to change the structure, style, and content of the document. This helps us navigate and manipulate the web page easily when we scrape it.
Building Your First Web Scraper
Let’s build a simple web scraper together. We’ll do it step by step.
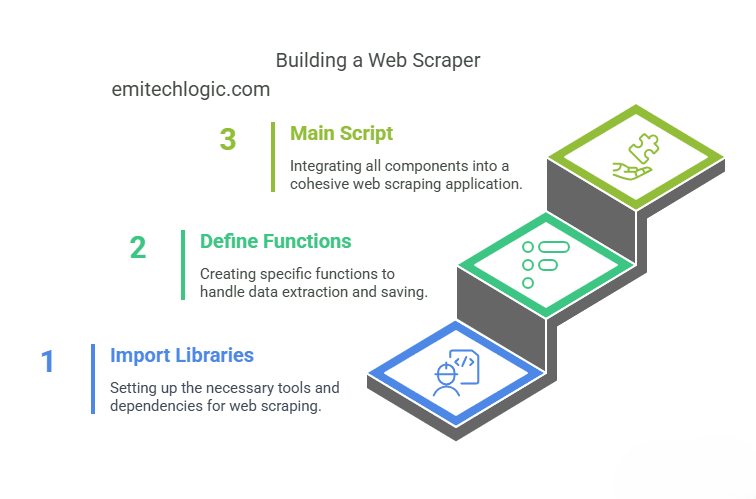
1: Import Libraries
First, we need to import some libraries. Libraries are like tools that help us with different tasks.
- requests: This helps us fetch the web page we want to scrape.
- BeautifulSoup: This helps us parse the HTML and extract the data we need.
- Document from
docx: This helps us save the scraped data into a Word document.
Here’s how to import these libraries:
import requests
from bs4 import BeautifulSoup
from docx import Document
In the next steps, we’ll use these libraries to create our web scraper.
2: Define the Functions
Now, we’ll create functions to extract content from a webpage and save it into a document.
- extract_content(soup): This function will extract the title, paragraphs, headings, and metadata from the webpage.
- save_to_doc(content, filename): This function will save the extracted content into a Word document.
Here’s how we define these functions:
Function 1: extract_content(soup)
This function takes a soup object (a BeautifulSoup object representing the webpage) and extracts the content we want.
def extract_content(soup):
content = {}
# Extract title
title_tag = soup.find('title')
content['title'] = title_tag.get_text() if title_tag else 'No Title'
# Extract all paragraphs
paragraphs = soup.find_all('p')
content['paragraphs'] = [p.get_text() for p in paragraphs]
# Extract all headings (h1 to h6)
headings = {}
for i in range(1, 7):
tag = f'h{i}'
headings[tag] = [h.get_text() for h in soup.find_all(tag)]
content['headings'] = headings
# Extract metadata
meta_tags = soup.find_all('meta')
meta_data = {}
for tag in meta_tags:
if 'name' in tag.attrs:
meta_data[tag.attrs['name']] = tag.attrs['content']
elif 'property' in tag.attrs:
meta_data[tag.attrs['property']] = tag.attrs['content']
content['meta'] = meta_data
return content
Here’s how it works:
- Title Extraction: Look for the title tag and retrieve its text. If there’s no title found, default to ‘No Title’.
- Paragraph Extraction: Locate all paragraph tags (<p>) and capture their text content.
- Heading Extraction: Capture text from headings across all levels (h1 to h6) found in the document.
- Metadata Extraction: Identify all meta tags and extract their name or property along with the content attributes

Function 2: save_to_doc(content, filename)
This function takes the content dictionary and a filename to save the extracted content into a Word document.
def save_to_doc(content, filename):
doc = Document()
# Add title
doc.add_heading(content['title'], level=1)
# Add metadata
doc.add_heading('Metadata', level=2)
for key, value in content['meta'].items():
doc.add_paragraph(f"{key}: {value}")
# Add headings and paragraphs
for level, texts in content['headings'].items():
if texts:
doc.add_heading(level, level=int(level[1]))
for text in texts:
doc.add_paragraph(text)
# Add paragraphs
doc.add_heading('Content', level=2)
for para in content['paragraphs']:
doc.add_paragraph(para)
# Save the document
doc.save(filename)
Here’s how it all comes together:
- Add Title: Start with the title as a main heading.
- Incorporate Metadata: Create a subheading called ‘Metadata’ and list all the key details.
- Integrate Headings and Text: For each heading level, add the heading and corresponding text as paragraphs.
- Add Paragraphs: Add all extracted paragraphs under a level 2 heading ‘Content’.
- Save the document: Save the document with the given filename.
These functions help us systematically extract and organize the content from a webpage and save it neatly into a Word document.
3: Main Script
Now, let’s put everything together into a main script. This script will fetch content from a webpage, parse it using BeautifulSoup, and then save the extracted content into a document.
# Main script
url = "http://example.com" # Replace with the target URL
response = requests.get(url)
if response.status_code == 200:
html_content = response.text
soup = BeautifulSoup(html_content, 'html.parser')
# Extract content
content = extract_content(soup)
# Save to document
save_to_doc(content, 'web_content.docx')
else:
print(f"Failed to retrieve the webpage. Status code: {response.status_code}")
Explanation
- Define the URL: Choose the webpage you want to scrape and set it as the url variable.
- Send HTTP request: Use requests.get(url) to fetch the webpage’s HTML content.
- Check response status: Confirm if the request was successful (response.status_code == 200).
- Parse HTML: If successful, parse the HTML content using BeautifulSoup (BeautifulSoup(html_content, ‘html.parser’)).
- Extract content: Use the extract_content(soup) function to collect the title, paragraphs, headings, and metadata from the parsed HTML.
- Save to document: Save the extracted content into a Word document named ‘web_content.docx’ using save_to_doc(content, ‘web_content.docx’).
- Error handling: If the request fails (status code other than 200), display an error message with the status code.
This script combines all the functions (extract_content and save_to_doc) to automate the process of fetching webpage content, extracting useful data, and saving it neatly into a document.

Best Practices for Web Scraping
- Respect Robots.txt: Always check the website’s robots.txt file to ensure that you are allowed to scrape the site. This file provides guidelines on which parts of the site can be scraped.
- Rate Limiting: Implement rate limiting to avoid overloading the server with requests. This helps in preventing your IP from being blocked.
- User-Agent String: Set a user-agent string to mimic a real browser and avoid being blocked. This string provides information about your browser and operating system to the server.
Advanced Web Scraping Techniques
As you become more comfortable with basic web scraping, you can explore advanced techniques to handle more complex scenarios.

Handling AJAX Requests
Some websites load content dynamically using JavaScript. In such cases, you might need to use tools like Selenium to scrape the website. Selenium automates browser actions, allowing you to interact with dynamic content.
Scraping Multiple Pages
To scrape multiple pages, identify the pattern in the URLs and loop through them. Here’s an example:
base_url = "http://example.com/page="
for i in range(1, 6):
url = base_url + str(i)
response = requests.get(url)
if response.status_code == 200:
html_content = response.text
soup = BeautifulSoup(html_content, 'html.parser')
content = extract_content(soup)
save_to_doc(content, f'web_content_page_{i}.docx')
Handling Captchas
Some websites use CAPTCHAs to prevent automated access. You can use services like 2Captcha to solve CAPTCHAs programmatically, but always consider the ethical implications and legal guidelines.
Real-World Applications of Web Scraping

- Price Monitoring: E-commerce companies use web scraping to monitor competitors’ prices and adjust their pricing strategies accordingly.
- Market Research: Companies gather data on consumer reviews, trends, and feedback to make informed business decisions.
- SEO Optimization: SEO professionals scrape search engine results to analyze keyword performance and optimize website content.
- Academic Research: Researchers gather data from various sources for analysis and studies.
Legal and Ethical Considerations
While web scraping is a powerful tool, it’s important to consider the legal and ethical implications. Always respect the website’s terms of service and privacy policies. Scraping data without permission can lead to legal issues. Additionally, ensure that your scraping activities do not harm the website’s performance or user experience.
Conclusion
Building a web scraper with Python and BeautifulSoup is a valuable skill that can open up numerous opportunities in data analysis, market research, SEO, and more. This comprehensive guide provided a step-by-step approach to setting up your environment, understanding HTML and the DOM, and creating a functional web scraper. By following best practices and exploring advanced techniques, you can enhance your scraping capabilities and tackle more complex projects.
Remember to respect the ethical and legal considerations while scraping data.
External Resources
- Official Documentation:
- BeautifulSoup: BeautifulSoup Documentation
- Python Requests: Requests Documentation
- Tutorials and Guides:
- Real Python: Web Scraping with BeautifulSoup
- DataCamp: Web Scraping with Python Tutorial
- Towards Data Science: Python Web Scraping Tutorial using BeautifulSoup
- Books:
- “Web Scraping with Python: Collecting More Data from the Modern Web” by Ryan Mitchell
- “Python Web Scraping Cookbook: Over 90 Proven Recipes to Get You Scraping with Python, Microservices, Docker, and AWS” by Michael Heydt
Source Code
app.py
from flask import Flask, request, render_template, send_file
import requests
from bs4 import BeautifulSoup
from docx import Document
import os
app = Flask(__name__)
def extract_content(soup):
content = {}
# Extract title
title_tag = soup.find('title')
content['title'] = title_tag.get_text() if title_tag else 'No Title'
# Extract all paragraphs
paragraphs = soup.find_all('p')
content['paragraphs'] = [p.get_text() for p in paragraphs]
# Extract all headings (h1 to h6)
headings = {}
for i in range(1, 7):
tag = f'h{i}'
headings[tag] = [h.get_text() for h in soup.find_all(tag)]
content['headings'] = headings
# Extract metadata
meta_tags = soup.find_all('meta')
meta_data = {}
for tag in meta_tags:
if 'name' in tag.attrs:
meta_data[tag.attrs['name']] = tag.attrs['content']
elif 'property' in tag.attrs:
meta_data[tag.attrs['property']] = tag.attrs['content']
content['meta'] = meta_data
return content
def save_to_doc(content, filename):
doc = Document()
# Add title
doc.add_heading(content['title'], level=1)
# Add metadata
doc.add_heading('Metadata', level=2)
for key, value in content['meta'].items():
doc.add_paragraph(f"{key}: {value}")
# Add headings and paragraphs
for level, texts in content['headings'].items():
if texts:
doc.add_heading(level, level=int(level[1]))
for text in texts:
doc.add_paragraph(text)
# Add paragraphs
doc.add_heading('Content', level=2)
for para in content['paragraphs']:
doc.add_paragraph(para)
# Save the document
doc.save(filename)
@app.route('/', methods=['GET', 'POST'])
def index():
if request.method == 'POST':
url = request.form['url']
response = requests.get(url)
if response.status_code == 200:
html_content = response.text
soup = BeautifulSoup(html_content, 'html.parser')
# Extract content
content = extract_content(soup)
# Save to document
filename = 'web_content.docx'
save_to_doc(content, filename)
return send_file(filename, as_attachment=True)
else:
return f"Failed to retrieve the webpage. Status code: {response.status_code}"
return render_template('index.html')
if __name__ == '__main__':
app.run(debug=True)




 Function Explained: How Memory Addressing Works")
) – 5 Efficient Methods")
[…] A Guide To Web Scraping in Python Using Beautiful Soup […]
[…] A Guide To Web Scraping in Python Using Beautiful Soup […]