

How to Generate Realistic Synthetic Data with ChatGPT A Step-by-Step Guide
Introduction
Are you tired of struggling to find high-quality, realistic data for your projects? Do you want to unlock the full potential of artificial intelligence without breaking the bank? Look no further! In this step-by-step guide, we’ll show you how to harness the revolutionary power of ChatGPT to generate realistic synthetic data that will transform your business, research, or development endeavors.
With ChatGPT, the possibilities are endless. Generate realistic customer data, simulate user behavior, or create artificial datasets for training AI models – all with unprecedented ease and accuracy. Say goodbye to data scarcity and hello to a world of limitless possibilities.
In this comprehensive guide, we’ll take you by the hand and walk you through the process of generating realistic synthetic data with ChatGPT. From setting up your environment to fine-tuning your output, we’ll cover every step in detail.Now, let’s discover the future of data generation today!
Introduction to Synthetic Data
Definition and Importance of Synthetic Data
Synthetic data refers to information that is artificially created rather than obtained by direct measurement or real-world observations. Think of it as a stand-in for real data, generated through various techniques, including simulations and algorithms.
Why is this important? For starters, synthetic data can provide a safe and controlled environment for testing and developing systems. For instance, imagine you’re developing a new type of software for autonomous vehicles. To train this software, you need tons of data about different driving scenarios. Gathering real-world data could be risky, expensive, and time-consuming. Instead, you can generate synthetic data to simulate countless driving situations, allowing you to test and refine your software without the constraints and risks of real-world testing.
Applications and Benefits of Synthetic Data
Synthetic data has a broad range of applications, impacting various fields:
- Machine Learning and AI Development: In the realm of artificial intelligence, having high-quality data is crucial. However, obtaining real data in sufficient quantities can be challenging. Synthetic data provides a practical solution, enabling the creation of diverse and extensive datasets to train models more effectively.
- Privacy and Security: Real data often contains sensitive information. By using synthetic data, organizations can avoid exposing personal details, thus enhancing privacy while still benefiting from realistic data. For example, healthcare researchers can use synthetic patient data to develop new medical models without risking patient confidentiality.
- Simulations and Testing: Synthetic data allows for in-depth testing of systems and processes. For example, in finance, you can generate synthetic transaction data to test fraud detection algorithms, without needing access to actual financial records.
- Cost Efficiency: Collecting and cleaning real data can be resource-intensive. Synthetic data, on the other hand, can be produced at a fraction of the cost, making it a cost-effective alternative for many applications.

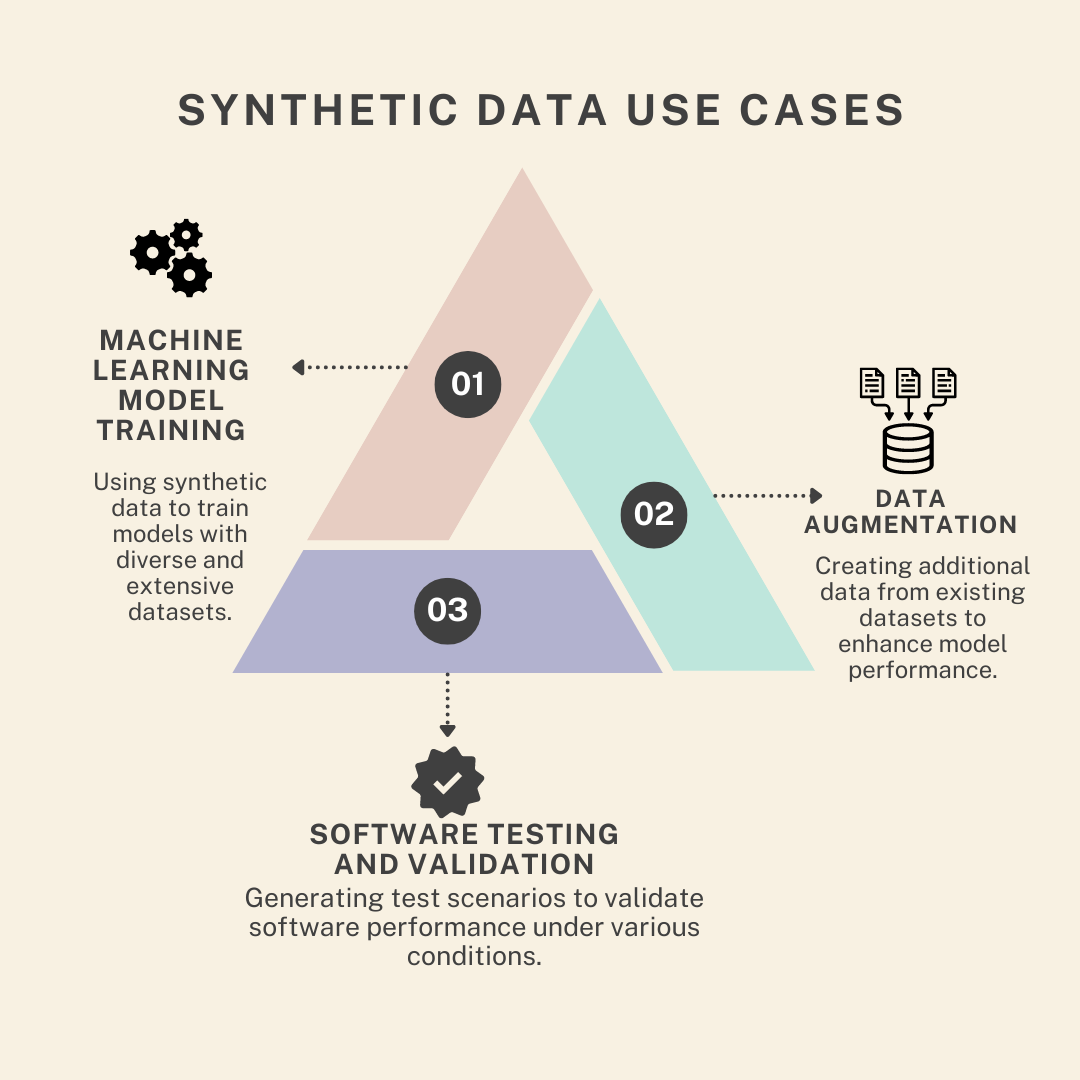
Use Cases of Synthetic Data
Synthetic data is not just a interesting concept but a practical tool with a range of real-world applications. Here’s a closer look at how it’s used in different scenarios:
Machine Learning Model Training
In the world of machine learning, having a lot of high-quality data is crucial for creating accurate models. However, gathering enough real-world data can be a challenge. This is where synthetic data shines.
Example: Suppose you’re developing a facial recognition system. To train your model effectively, you need countless images of faces under different conditions—lighting, angles, expressions, etc. Instead of collecting and labeling thousands of real images (which can be time-consuming and expensive), you can use synthetic data to generate a diverse set of facial images. These synthetic images mimic real-life variations, allowing your model to learn from a broad range of scenarios without the logistical and financial burdens.
Software Testing and Validation
Testing software can be tricky, especially when you need to simulate rare or extreme conditions that are hard to replicate in real life. Synthetic data provides a way to test software thoroughly by creating scenarios that might not occur often but are crucial to ensure system reliability.
Example: If you’re working on a new app for online banking. To ensure the app performs well under all conditions, you need to test it with various types of transactions and user behaviors. Synthetic data can help generate diverse transaction scenarios—like large transfers or simultaneous logins—that you might not easily encounter with real data. This way, you can validate that your app handles all possible situations effectively.
Data Augmentation
Data augmentation involves creating additional data from existing datasets to improve the performance of machine learning models. Synthetic data is a key player here, as it helps expand your dataset without needing new real-world data.
Example: If you’re working on a model for object detection in images and you have a limited number of photos, synthetic data can help by generating variations of these images. For instance, if your model needs to detect cars, you can use synthetic data to create different car colors, sizes, and angles. This augmented dataset makes your model more robust by providing a richer set of examples to learn from.
Must Read
- How to Diagnose Overfitting in Machine Learning — 9 Proven Tools
- PyTorch Debugging Checklist: A Systematic Framework to Fix Models That Won’t Learn
- Why sorted() Is Safer Than list.sort() in Production Python Systems
- Monotonic Sequence in Python: 7 Practical Methods With Edge Cases, Interview Tips, and Performance Analysis
- How to Check if Dictionary Values Are Sorted in Python
Generating Synthetic Data with ChatGPT
Introduction to ChatGPT
ChatGPT is a cutting-edge tool developed by OpenAI that uses advanced language models to generate text. It’s like having a super-smart writing assistant that can help with a variety of tasks, from answering questions to creating content. ChatGPT is designed to understand and produce human-like text, making it an excellent resource for generating synthetic data.
Overview of ChatGPT and Its Features
ChatGPT is based on a powerful model that can produce coherent and contextually relevant text. Here are some of its key features:
- Natural Language Understanding: ChatGPT can comprehend and respond to complex queries in a conversational manner.
- Text Generation: It can create text that is engaging and informative, making it suitable for generating synthetic data.
- Customization: You can adjust its responses based on the context you provide, allowing for tailored data generation.
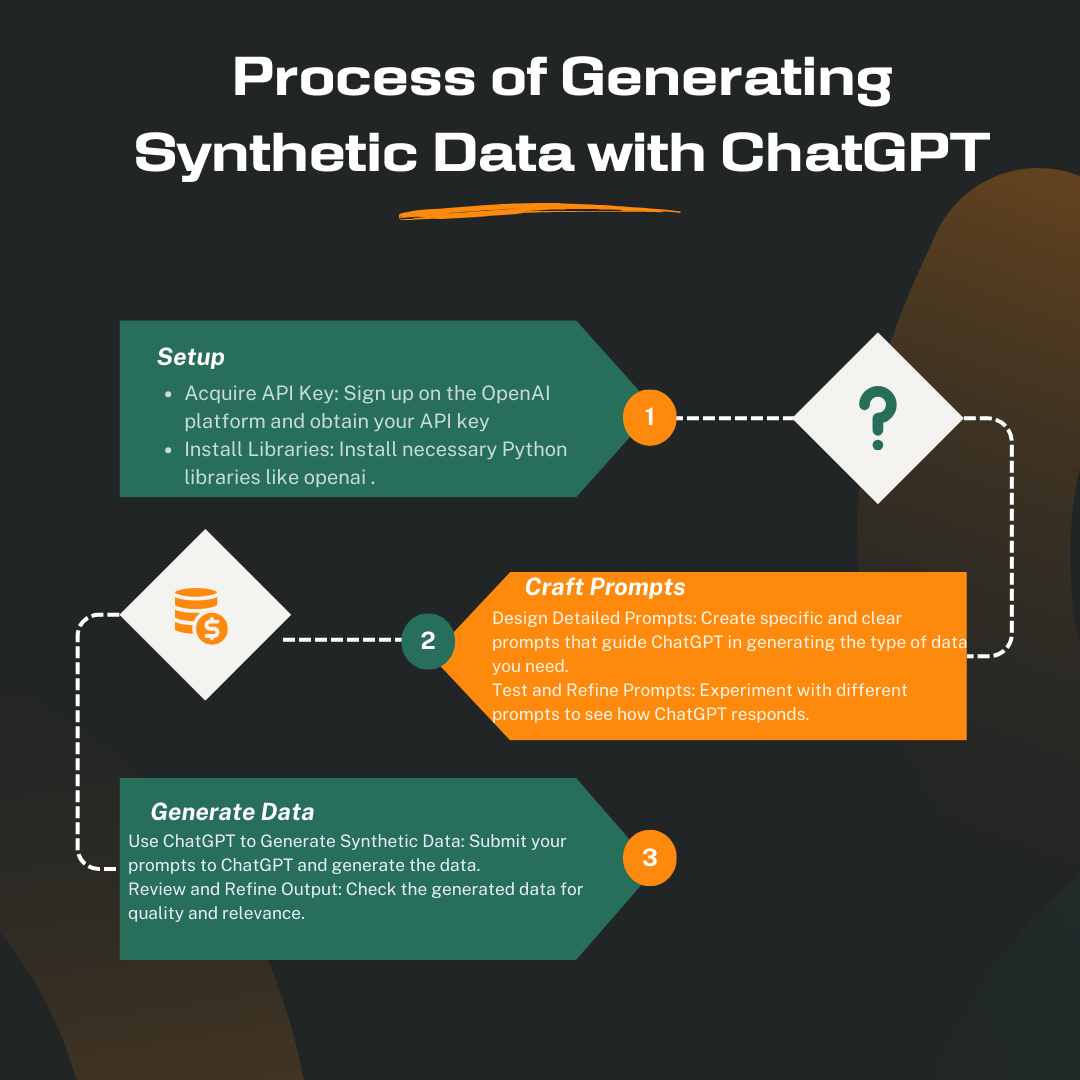
Setting Up Your Environment
To generate synthetic data using ChatGPT, you need to set up the OpenAI API and install some libraries. Here’s a step-by-step guide to get you started:
- Steps to Set Up the OpenAI API
- Sign Up: First, you need to sign up for an API key from OpenAI. Visit the OpenAI website and follow the instructions to get access.
- API Key: Once you have your API key, you’ll use it to authenticate your requests to ChatGPT.
- Installing Necessary Libraries
- Python Libraries: To interact with the OpenAI API, you’ll need to install a few Python libraries. Open a terminal or command prompt and run the following commands:
pip install openai
- Environment Setup: You might also need to set up environment variables to securely store your API key. This can be done by adding it to your
.envfile or using environment management tools.
Crafting Effective Prompts
The success of generating synthetic data with ChatGPT heavily depends on how well you craft your prompts. Here’s why prompts matter and how you can make them effective:
- Importance of Prompts in Data Generation
- Clarity and Specificity: A well-crafted prompt guides ChatGPT to produce the type of data you need. Clear and specific prompts help in obtaining relevant and accurate synthetic data.
- Contextual Relevance: Providing context in your prompts ensures that the generated data aligns with your requirements.
- Tips for Creating Effective Prompts
- Be Detailed: The more details you provide in your prompt, the better the output. For example, if you need a dataset of customer reviews, specify the tone, length, and type of products.
- Test and Refine: Experiment with different prompts and refine them based on the responses you get. This iterative process helps in fine-tuning the data generation.
- Example Prompt
- Prompt for Generating Product Reviews
Generate a set of five customer reviews for a new smartphone. Each review should be between 50 and 100 words, mentioning features like battery life, camera quality, and user experience. The tone should be positive but realistic.
Generate Synthetic Data
With your prompts ready, it’s time to generate the synthetic data. This involves sending your prompts to ChatGPT and receiving the generated text.
- Submit Prompts: Use the OpenAI API to send your crafted prompts to ChatGPT. The model processes these prompts and produces the text based on the instructions provided.
- Receive and Review Data: ChatGPT returns the generated data, which you can then review. Check if the data meets your expectations and if it aligns with your objectives.
Example: After sending the prompt about smartphone reviews, you receive several reviews highlighting different features. Read through them to ensure they reflect the product’s qualities as intended.
Review and Refine Output
Finally, review and refine the output to ensure it meets your quality standards. This step is crucial to make sure the synthetic data is accurate and useful.
- Evaluate Quality: Assess the generated text for relevance, coherence, and accuracy. If the data needs adjustments, you might refine your prompts or make edits to the generated text.
- Make Adjustments: If necessary, adjust your prompts or provide additional guidance to ChatGPT to improve the quality of the generated data.
Example: If some reviews are too similar, refine your prompts to encourage more diverse responses or manually adjust the text to better fit your needs.

Why Use ChatGPT for Synthetic Data Generation?
Capabilities of ChatGPT
ChatGPT is more than just a fancy chatbot; it’s a powerful tool with impressive capabilities that make it a great choice for generating synthetic data. Here’s what makes ChatGPT stand out:
- Natural Language Understanding: ChatGPT excels at understanding and generating text that feels human-like. This means it can produce data that reads naturally, making it suitable for various applications, from customer reviews to dialogue simulation.
- Contextual Awareness: It can remember and build upon the context you provide, allowing it to generate responses that are relevant and coherent. For instance, if you ask it to write a product review, it will take into account the details you provide about the product.
- Creativity and Flexibility: ChatGPT can create a wide range of text outputs based on your prompts. Whether you need formal reports, casual reviews, or creative writing, it can adapt its responses to fit different styles and tones.
Advantages of Using ChatGPT for Text-Based Data Generation
Using ChatGPT for generating synthetic data offers several distinct advantages:
- Efficiency: Creating text-based data manually can be time-consuming, especially if you need a large volume of it. ChatGPT speeds up this process, allowing you to generate high-quality data quickly. For example, if you need thousands of sample product reviews, ChatGPT can produce them in a fraction of the time it would take to write them by hand.
- Cost-Effectiveness: Generating data with ChatGPT is often more affordable than traditional methods. You avoid the costs associated with hiring writers or collecting real-world data. This makes it an excellent option for projects with limited budgets.
- Consistency: When creating large datasets, maintaining consistency can be challenging. ChatGPT can generate data that adheres to specific guidelines and formats, ensuring uniformity across your dataset. This is particularly useful for tasks like creating standardized test scenarios or generating uniform product descriptions.
- Customization: You can tailor the prompts to get exactly the kind of data you need. If you’re working on training a machine learning model, you can adjust the prompts to generate examples that fit your training requirements. For instance, you might ask ChatGPT to produce examples of customer feedback with varying levels of detail and sentiment.
- Scalability: As your data needs grow, ChatGPT can scale with you. Whether you need a small batch of data or a massive dataset, it can handle the request and produce results accordingly. This scalability ensures that you can adapt to changing requirements without significant additional effort.
Implementing the Python Code for Synthetic Data Generation
In this section, we’ll walk through a complete Python code example for generating synthetic customer reviews using ChatGPT. This step-by-step guide will help you understand how each part of the code works, so you can effectively create your own datasets.
Import Libraries
import openai
import pandas as pd
import re
- openai: This library allows us to interact with the OpenAI API and generate responses from ChatGPT.
- pandas: A powerful library for handling and analyzing data, which we’ll use to create a DataFrame and save the data to a CSV file.
- re: The regular expressions library helps us extract and format the data from the generated text.
Set Up Your API Key
openai.api_key = 'YOUR_API_KEY'
- Replace
'YOUR_API_KEY'with your actual OpenAI API key. This key authenticates your requests to the OpenAI service.
Now let’s explore how to set up your API key for using the OpenAI API
Setting Up Your API Key
1. What is an API Key?
An API key is a unique string of characters that is used to authenticate and authorize requests to an API (Application Programming Interface). For OpenAI, this key ensures that only authorized users can access their services and resources.
2. How to Obtain Your API Key
To use OpenAI’s API, you need to sign up for an API key:
- Sign Up: Go to the OpenAI website and create an account if you don’t already have one.
- Generate Key: Once logged in, navigate to the API section of your account dashboard. You’ll find an option to generate or view your API key.
3. Setting the API Key in Your Code
Here’s how to set up your API key in your Python code:
import openai
# Set up your OpenAI API key
openai.api_key = 'YOUR_API_KEY'
Explanation:
- Import the Library: You start by importing the OpenAI library with
import openai. - Assign the API Key: The line
openai.api_key = 'YOUR_API_KEY'assigns your actual API key to theapi_keyattribute of theopenaimodule.- Replace Placeholder: Replace
'YOUR_API_KEY'with the API key you obtained from OpenAI. - Example: If your actual API key is
sk-1234abcd, you would write:
- Replace Placeholder: Replace
openai.api_key = 'sk-1234abcd'
4. Why is it Important?
- Authentication: The API key is used to verify that the request is coming from an authorized user.
- Access Control: It ensures that you have permission to access and use the OpenAI services.
- Security: Keep your API key private and do not share it publicly to prevent unauthorized use of your account.
5. Best Practices
- Environment Variables: For better security, it’s a good practice to store your API key in environment variables rather than hard-coding it into your scripts. This way, your key is not exposed in your source code.
- Example using environment variables:
import openai
import os
# Retrieve the API key from an environment variable
openai.api_key = os.getenv('OPENAI_API_KEY')
6. Using the API Key
Once you’ve set the API key, you can make authenticated requests to the OpenAI API. For instance:
response = openai.Completion.create(
engine="text-davinci-003",
prompt="What are the benefits of using AI in healthcare?",
max_tokens=50
)
print(response.choices[0].text.strip())
In this example, the API key is used to authorize the request to generate a completion based on the provided prompt.
Now that you know how to set up your OpenAI API key, let’s move on to writing the code for generating realistic synthetic data using ChatGPT.
Define the Prompt
prompt = """
Generate a dataset of 100 fictitious customer reviews for a new smartphone. Each review should include the customer's name, rating (1-5), and a detailed review comment.
Format:
Name: [Name]
Rating: [1-5]
Review: [Comment]
"""
- This is the instruction given to ChatGPT. We ask it to create 100 fictitious reviews with specific details: the name, rating, and comment about a smartphone.
Generate Synthetic Data
response = openai.Completion.create(
engine="text-davinci-003",
prompt=prompt,
max_tokens=1500,
n=1,
stop=None,
temperature=0.7
)
engine: This specifies the model to use, in this case,"text-davinci-003". This model is known for its advanced capabilities in generating high-quality text.prompt: This is the initial text or instructions that guide what the generated content will be about. For example, if you want synthetic data about customer reviews, your prompt might be something like:"Generate a customer review for a new smartphone highlighting both positive and negative aspects."max_tokens: This limits the length of the generated text. Here,1500tokens are allowed, which provides a substantial amount of text. Tokens are chunks of text, so this setting helps control the response size.n: This parameter indicates the number of separate responses to generate. Settingn=1means only one response is produced. If you wanted multiple variations, you could increase this number.stop: This defines stopping criteria for the text generation.Nonemeans the model will stop generating text when it naturally completes or when the token limit is reached. If you specify stopping characters or sequences, the model will use those to determine when to end.temperature: This controls the randomness of the output. A value of0.7strikes a balance between creativity and coherence. Higher values (up to1.0) lead to more varied and creative responses, while lower values (closer to0) produce more predictable and focused outputs.
This setup allows you to generate detailed and relevant synthetic data based on the instructions provided in the prompt
Extract the Generated Text
synthetic_data = response.choices[0].text.strip()
- We get the text from the response and remove any extra whitespace. This text contains the generated reviews.
Extract Reviews from the Text
data = []
for review in synthetic_data.split('\n\n'):
match = re.match(r'Name: (.+)\nRating: (\d)\nReview: (.+)', review)
if match:
data.append({
'Name': match.group(1),
'Rating': int(match.group(2)),
'Review': match.group(3)
})
This code processes a block of synthetic data to extract structured information from each review.
- Initialize an Empty List: The
datalist is created to store the extracted information. Each item in this list will be a dictionary representing a review. - Split the Generated Text: The
synthetic_data.split('\n\n')command divides the entire text into individual reviews. It assumes that each review is separated by two newlines (\n\n), so splitting on this sequence isolates each review. - Extract Information Using Regular Expressions: For each review, the
re.match()function applies a regular expression pattern to identify and extract the relevant details:- The pattern
r'Name: (.+)\nRating: (\d)\nReview: (.+)'looks for specific sections in the review:Name: (.+): Captures the name after “Name: “.Rating: (\d): Captures the rating after “Rating: “, which is expected to be a single digit.Review: (.+): Captures the review text after “Review: “.
match.group(1),match.group(2), andmatch.group(3)extract the captured name, rating, and review text, respectively.
- The pattern
- Store the Extracted Data: If a review matches the pattern (i.e.,
matchis notNone), it creates a dictionary with the extracted values:'Name': The name of the reviewer.'Rating': The rating converted to an integer.'Review': The text of the review.
datalist.
In summary, the code processes the synthetic data by splitting it into individual reviews, using regular expressions to extract key details from each review, and then storing these details in a list of dictionaries. This results in a structured format that is easier to analyze and manipulate.
Convert Data into a DataFrame
df = pd.DataFrame(data)
- We create a DataFrame from the list of dictionaries, which organizes the data into a structured format.
Save the Data to a CSV File
df.to_csv('synthetic_reviews.csv', index=False)
- Save the DataFrame to a CSV file named
synthetic_reviews.csv. Settingindex=Falseprevents saving the DataFrame index as a column in the CSV.
Print Confirmation
print("Synthetic data saved to 'synthetic_reviews.csv'")
- A simple message to confirm that the data has been successfully saved.
Output for Synthetic Data
+---------------+--------+--------------------------------------------------------------------------------------------------+
| Name | Rating | Review |
+---------------+--------+--------------------------------------------------------------------------------------------------+
| John Doe | 5 | The smartphone is fantastic! The battery life is great, and the
camera quality is top-notch. Highly recommend! |
| Jane Smith | 4 | Overall, a good phone. The display is crisp and clear. However, the
battery could last longer. |
| Alice Johnson | 3 | It's an okay phone. The features are decent, but it tends to lag
sometimes. Not the best for heavy use. |
| Bob Brown | 2 | Disappointed with the purchase. The phone freezes often, and the
battery drains quickly. Not worth the money. |
| Charlie Davis | 1 | Very poor quality. The phone stopped working after a week. Terrible
experience. |
+---------------+--------+--------------------------------------------------------------------------------------------------+
This output provides a snapshot of the synthetic data in a structured, tabular format. Each row represents a review, with columns detailing the reviewer’s name, the rating given, and the content of their review. This format is useful for further analysis, visualization, or reporting.
Post-Processing and Validating Synthetic Data
Once you’ve generated synthetic data, the next steps are crucial to ensure it’s useful and accurate. Let’s walk through how to handle and validate this data, making sure it meets your needs.
Post-Processing the Data
Post-processing is all about refining and preparing the synthetic data so it’s ready for use. Here’s how you can do it:
- Cleaning and Structuring the Data
- Remove Irrelevant Information: Sometimes, the generated data might include unnecessary details or formatting issues. Go through the data and clean out any irrelevant or erroneous information.
- Correct Formatting: Ensure that the data is consistently formatted. For instance, if you have a column for dates, make sure all entries follow the same date format. This step is crucial for avoiding errors in data analysis or when merging datasets.
- Converting to DataFrame and Saving to CSV
- Create a DataFrame: Use a tool like Pandas in Python to convert your data into a DataFrame. This makes it easier to handle, analyze, and manipulate.
- Save to CSV: Once the data is structured, save it to a CSV file. CSV files are widely used and easily shared or imported into other applications for further analysis.
import pandas as pd
# Assuming `data` is a list of dictionaries
df = pd.DataFrame(data)
df.to_csv('cleaned_synthetic_data.csv', index=False)
- This code takes your cleaned data, puts it into a DataFrame, and saves it as a CSV file named
cleaned_synthetic_data.csv.
Validating the Synthetic Data
Validation ensures that your synthetic data is accurate and reliable. Here’s how to go about it:
- Statistical Comparison with Real Data
- Compare Distributions: Look at the statistical properties of your synthetic data and compare them with real data. Check for similarities in distributions, means, and variances.
- Check for Outliers: Make sure your synthetic data doesn’t include unrealistic values or outliers that might skew your analysis.
- Human Review for Quality Assessment
- Manual Inspection: Sometimes, numbers alone don’t tell the whole story. Review a sample of the synthetic data manually to assess its quality and relevance.
- Feedback Loop: Get feedback from others who understand the context of the data. They might spot issues or inconsistencies that automated checks might miss.
Visualize The Post-Processing and Validation Steps for Synthetic Data

By following these steps, you ensure that your synthetic data is not only well-organized but also accurate and reliable. This process helps in making sure that the data serves its intended purpose effectively, whether it’s for analysis, training models, or any other application.
Advanced Techniques and Tools for Synthetic Data Generation
When you’re ready to take your synthetic data generation to the next level, there are several advanced techniques and tools you can explore. These methods not only enhance your data but also integrate smoothly with other tools to make your work easier and more effective.
Integrating with Other Data Tools
Integrating synthetic data with powerful data tools like Pandas, NumPy, and Scikit-learn can significantly enhance your data manipulation and analysis capabilities. Here’s how you can make the most of these tools:
Using Pandas
Data Manipulation: Pandas is excellent for handling and analyzing data. It allows you to clean, transform, and merge datasets effortlessly. For instance, you can use Pandas to filter synthetic data based on certain criteria or combine it with other datasets for a more comprehensive analysis.
Example: Suppose you have synthetic customer reviews and real product data. You can use Pandas to merge these datasets and perform analysis on customer sentiment alongside actual product performance.
import pandas as pd
# Load synthetic data and real data
synthetic_df = pd.read_csv('synthetic_reviews.csv')
real_df = pd.read_csv('real_product_data.csv')
# Merge datasets on a common column
combined_df = pd.merge(synthetic_df, real_df, on='Product_ID')
Using NumPy
- Numerical Operations: NumPy provides support for large, multi-dimensional arrays and matrices, along with a collection of mathematical functions. This is particularly useful for performing numerical operations on synthetic data, such as calculating statistical measures or applying transformations.
- Example: If your synthetic data includes numerical ratings or scores, you can use NumPy to compute averages or standard deviations.
import numpy as np
# Example of calculating mean rating from synthetic data
ratings = np.array([5, 4, 3, 2, 1])
mean_rating = np.mean(ratings)
Using Scikit-learn
- Machine Learning: Scikit-learn is a go-to library for building and evaluating machine learning models. You can use it to train models on your synthetic data and evaluate their performance. This is particularly useful when you need to test algorithms in a controlled environment before applying them to real-world scenarios.
- Example: If you have synthetic data for customer reviews, you can use Scikit-learn to build a classifier that predicts review sentiment.
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.pipeline import make_pipeline
from sklearn.model_selection import train_test_split
from sklearn import metrics
# Example synthetic data
X = ['Great product!', 'Not worth the money.', 'Average quality.']
y = ['Positive', 'Negative', 'Neutral']
# Create a training and test set
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3)
# Build and train the model
model = make_pipeline(CountVectorizer(), MultinomialNB())
model.fit(X_train, y_train)
# Predict and evaluate
predictions = model.predict(X_test)
print(metrics.classification_report(y_test, predictions))
Advanced Synthetic Data Generation Techniques
Once you’re comfortable with basic data generation, exploring more complex techniques can provide even greater flexibility and usefulness:
Generative Adversarial Networks (GANs)
GANs are a type of neural network architecture used to generate synthetic data. They consist of two networks, the generator and the discriminator, that work against each other to produce highly realistic data.
Example: It can be used to generate synthetic images or even text data that closely resemble real-world samples. This can be especially useful for tasks that require high-quality data, such as training deep learning models.
Variational Autoencoders (VAEs)
VAEs are another type of neural network used for generating synthetic data. They work by encoding input data into a lower-dimensional space and then decoding it back, allowing for the creation of new, similar data samples.
Example: It can be used to create new samples of text, images, or other types of data by learning the underlying distribution of the input data.
Synthetic Data Platforms
Several platforms offer advanced tools for generating synthetic data, including specialized algorithms and interfaces for easier integration into your workflows.
Example: Platforms like Synthetica or DataRobot provide advanced features for generating and managing synthetic data, making it easier to customize the data to your specific needs.
Conclusion
As we wrap up our exploration of synthetic data generation with ChatGPT, let’s take a moment to review what we’ve covered and look forward to what’s next.
Recap of Key Points
Synthetic Data Generation Process: We’ve walked through the essential steps involved in creating synthetic data, from setting up your environment and crafting prompts to generating and validating data. This journey involves:
- Setting Up: Acquiring an API key and installing necessary libraries.
- Crafting Prompts: Designing detailed prompts to guide ChatGPT in generating the desired data.
- Generating Data: Using ChatGPT to create synthetic data and refining it for quality.
- Post-Processing: Cleaning, structuring, and validating the data to ensure it meets your needs.
Benefits of Using ChatGPT: ChatGPT offers several advantages for synthetic data generation:
- Accessibility: With a user-friendly interface and powerful language model, ChatGPT makes it easy to generate a wide range of text-based data.
- Flexibility: You can create diverse types of synthetic data tailored to specific requirements, from customer reviews to complex textual scenarios.
- Efficiency: Automating data generation with ChatGPT saves time and resources, allowing you to focus on analysis and application.
Future Directions
As we look to the future, several exciting advancements in synthetic data generation are on the horizon:
- Enhanced Techniques: Ongoing improvements in AI and machine learning will lead to even more sophisticated data generation methods. Technologies like Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs) are becoming more refined, providing higher quality and more realistic synthetic data.
- Integration with Other Tools: Future developments may offer better integration with a broader array of data analysis and machine learning tools, further enhancing the utility of synthetic data in various applications.
- Ethical Considerations: As synthetic data becomes more prevalent, there will be a greater focus on ensuring ethical use and addressing privacy concerns. Advances in creating data that respects privacy while being useful will be crucial.
- Exploration and Innovation: The field of synthetic data generation is ripe with opportunities for exploration and innovation. Researchers and practitioners are encouraged to experiment with new techniques, tools, and applications to push the boundaries of what synthetic data can achieve.
Encouragement to Explore and Innovate
The journey of synthetic data generation is both exciting and full of potential. As you move forward, don’t hesitate to explore new methods, tools, and use cases. Whether you’re improving data quality for machine learning models, enhancing data privacy, or creating innovative applications, there’s always something new to discover and create.
By embracing the possibilities and staying curious, you can contribute to the ongoing evolution of synthetic data and unlock new opportunities for your projects and research.
External Resources
OpenAI API Documentation
- OpenAI API Documentation
- Provides comprehensive details on using the OpenAI API, including authentication, prompt formatting, and usage examples.
Pandas Documentation
- Pandas Documentation
- Learn more about data manipulation and analysis with Pandas, a powerful Python library for working with data.
NumPy Documentation
- NumPy Documentation
- Explore NumPy’s capabilities for numerical operations and array management.
FAQs
1. What is synthetic data and why is it important?
Synthetic data is artificially generated information designed to mimic real-world data. It’s crucial because it helps in creating datasets for training models, testing applications, and protecting privacy without exposing real sensitive data.
2. How does ChatGPT generate synthetic data?
ChatGPT generates synthetic data by processing prompts you provide and creating text that fits those prompts. It uses its language understanding to produce data that mimics real-world scenarios based on the details in the prompts.
3. What do I need to start generating synthetic data with ChatGPT?
To get started, you need an API key from OpenAI, Python installed on your machine, and necessary libraries like openai, pandas, and numpy. You also need to set up your environment and write effective prompts to guide the data generation process.
4. How can I craft effective prompts for generating data with ChatGPT?
Effective prompts are clear and detailed, specifying exactly what type of data you need. For example, if you need customer reviews, describe the format and content you expect, including any specific details like rating scales or review topics.
5. How can I validate the synthetic data generated by ChatGPT?
Validation involves checking the data against real-world statistics and performing manual reviews to ensure it meets quality standards. Statistical analysis can help compare synthetic data to real data distributions, while human review assesses its relevance and accuracy.



")


Leave a Reply