

How to Return Multiple Values from a Function in Python
How to Return Multiple Values from a Function in Python
Learn different methods to return multiple values from Python functions with practical examples and best practices
Table of Contents
Why Return Multiple Values from a Function?
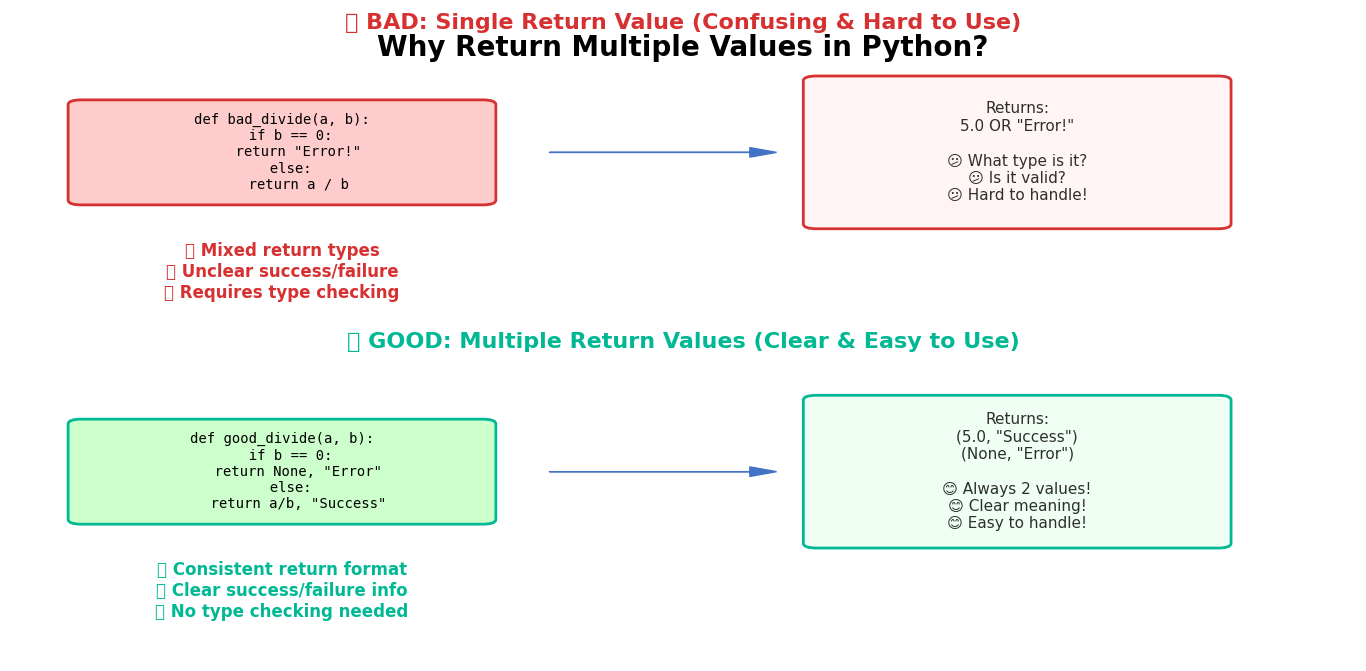
Python programming frequently requires functions that return multiple values simultaneously. This powerful feature allows developers to create efficient functions that provide comprehensive results in a single operation. Instead of calling separate functions for related data, Python multiple return values enable streamlined code execution and improved program performance. Understanding when and how to implement multiple return values becomes essential for writing professional Python applications.
The ability to return multiple values from Python functions addresses common programming challenges where related data needs to be processed together. This functionality proves invaluable across various development scenarios, from basic mathematical calculations to complex data analysis workflows. Here are practical situations where Python multiple return values significantly enhance code efficiency:
- Mathematical Operations and Statistical Analysis: Division functions frequently require both quotient and remainder calculations. Statistical analysis functions need to compute mean, median, mode, and standard deviation simultaneously. Multiple return values eliminate redundant calculations and improve computational efficiency for mathematical applications.
- Data Analysis and Processing Workflows: Data science applications often require comprehensive analysis results including minimum values, maximum values, averages, counts, and summary statistics. Python functions returning multiple values streamline data processing pipelines and reduce function call overhead.
- File System Operations and Content Management: File processing functions benefit from returning both file content and metadata including file size, creation timestamps, modification dates, and access permissions. This approach provides complete file information in single function calls.
- Web Development and API Integration: Flask web applications and API endpoints require functions that return response data alongside HTTP status codes, error messages, and execution metadata for comprehensive request handling.
- User Input Validation and Form Processing: Multiple input processing functions need to return validated data, error messages, success indicators, and formatted output simultaneously for robust user interface development.
- Database Query Operations: Database functions often return query results along with execution time, affected row counts, connection status, and error information for comprehensive database interaction monitoring.
Real-world Division Calculator Example
Consider building a calculator application that performs integer division operations. Traditional approaches require separate function calls for quotient and remainder calculations, leading to inefficient code execution. Python multiple return values solve this problem by providing both mathematical results simultaneously.
For instance, when calculating how to distribute 20 items among 3 groups, you need both the items per group (quotient: 6) and remaining items (remainder: 2). A single function returning multiple values provides this complete mathematical solution efficiently.
# Inefficient approach: separate functions for related operations
def get_quotient(a, b):
# Floor division operator (//) returns integer division result
return a // b
def get_remainder(a, b):
# Modulo operator (%) returns division remainder
return a % b
# Efficient approach: single function returning multiple values
def divide_with_remainder(a, b):
# Calculate both quotient and remainder in one function
quotient = a // b # Integer division result
remainder = a % b # Division remainder
# Return both values as a tuple (Python automatically creates tuple)
return quotient, remainder
# Example usage demonstrating efficiency improvement
result_quotient, result_remainder = divide_with_remainder(20, 3)
print(f"20 ÷ 3 = {result_quotient} remainder {result_remainder}")Method 1: Using Tuples (Most Common)
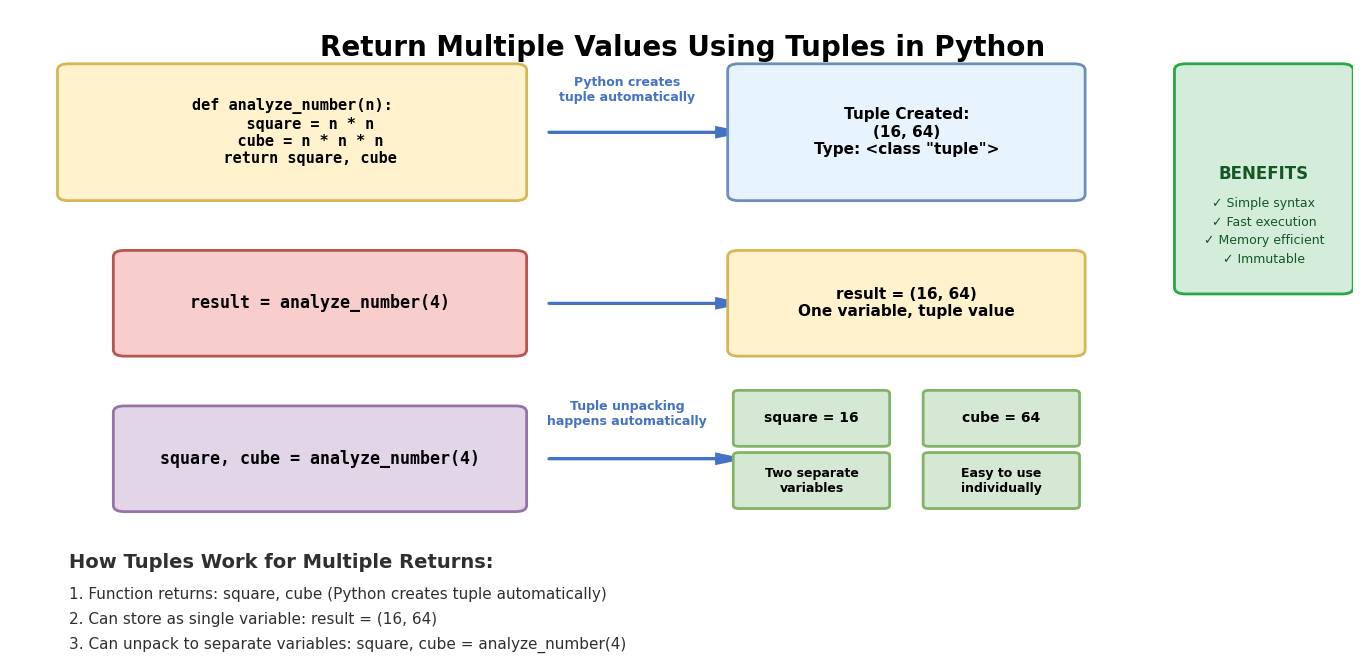
Python tuples represent the most widely adopted method for returning multiple values from functions. Tuples function as ordered collections that maintain element sequence and provide memory-efficient storage for related data. When developers separate values with commas in return statements, Python automatically constructs tuple objects without requiring explicit tuple constructor calls.
The immutable nature of tuples provides significant advantages for multiple return value scenarios. Once created, tuple contents cannot be modified, ensuring data integrity throughout program execution. This immutability characteristic makes tuples ideal for returning computed results that should remain unchanged after function completion. Understanding tuple mechanics becomes essential for implementing robust Python applications with multiple return value patterns. The Python official documentation on defining functions provides comprehensive information about return value handling and tuple usage patterns.
Basic Tuple Return Implementation
This example demonstrates fundamental tuple return syntax and automatic tuple creation in Python functions. The function returns two different data types (string and integer) as a single tuple object.
def get_name_age():
# Define variables with different data types
name = "Alice" # String data type
age = 25 # Integer data type
# Return multiple values separated by comma (creates tuple automatically)
return name, age # Python automatically creates tuple object
# Function call assigns returned tuple to single variable
result = get_name_age()
# Display the complete tuple object
print("Complete result:", result) # Shows: ('Alice', 25)
# Verify the data type of returned object
print("Data type:", type(result)) # Shows: <class 'tuple'>
# Access individual tuple elements using index notation
print("Name:", result[0]) # Shows: Alice
print("Age:", result[1]) # Shows: 25Tuple Unpacking and Variable Assignment
Tuple unpacking represents one of Python’s most powerful features for handling multiple return values efficiently. This process allows developers to assign individual tuple elements to separate variables in a single operation, eliminating the need for index-based access. Tuple unpacking significantly improves code readability and reduces the likelihood of indexing errors in complex applications.
Python’s tuple unpacking mechanism automatically matches the number of variables on the left side with tuple elements on the right side. This feature becomes particularly valuable when working with functions that return multiple related values, such as coordinate calculations, statistical computations, or data validation results. The Python documentation on tuples and sequences provides detailed information about advanced unpacking techniques and sequence manipulation methods.
def calculate_stats(numbers):
# Calculate total using built-in sum() function
total = sum(numbers) # Adds all numbers in the list
# Count elements using len() function
count = len(numbers) # Returns number of items in list
# Calculate average by dividing total by count
average = total / count # Mathematical average calculation
# Return all three values as tuple (automatic tuple creation)
return total, count, average # Creates tuple: (total, count, average)
# Create sample dataset for statistical analysis
data = [10, 20, 30, 40, 50] # List of integers
# Unpack returned tuple into separate variables (tuple unpacking)
total_sum, item_count, mean = calculate_stats(data)
# Display each calculated statistic with descriptive labels
print(f"Total sum of all values: {total_sum}")
print(f"Number of data points: {item_count}")
print(f"Statistical average: {mean}")Advanced Tuple Examples
def process_coordinates(x, y):
# Calculate distance from origin
distance = (x**2 + y**2)**0.5
# Determine quadrant
if x > 0 and y > 0:
quadrant = "I"
elif x < 0 and y > 0:
quadrant = "II"
elif x < 0 and y < 0:
quadrant = "III"
else:
quadrant = "IV"
return distance, quadrant, (x, y)
# Example usage
dist, quad, original_coords = process_coordinates(3, 4)
print(f"Distance: {dist}")
print(f"Quadrant: {quad}")
print(f"Original coordinates: {original_coords}")Advantages of Using Tuples for Multiple Returns
- Simple and intuitive syntax
- Memory efficient
- Immutable (values can’t be changed)
- Supports unpacking
- Built into Python core
Limitations of Using Tuples for Multiple Returns
- No named access to elements
- Order matters for unpacking
- Less readable for many values
- Type hints can be complex
Method 2: Using Lists
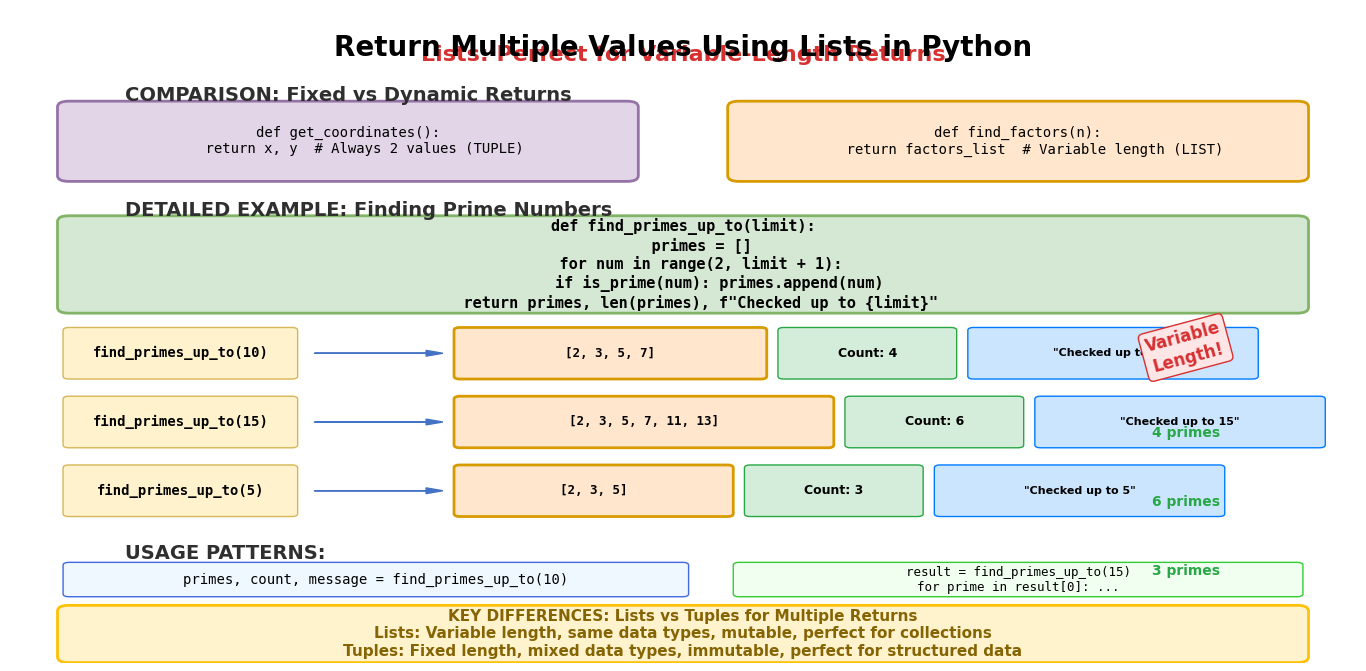
Lists are mutable sequences that can also be used to return multiple values. Think of lists as flexible containers where you can add, remove, or change items after they’re created – like a shopping cart that you can modify while shopping. They’re particularly useful when you need to modify the returned values or when the number of returned items might vary. Unlike tuples, lists allow you to change their contents after creation, which can be both powerful and potentially risky depending on your needs.
Lists work especially well when you’re dealing with collections of similar items or when the exact number of items you’ll return isn’t known beforehand. For example, when processing user data or building chatbot applications that need to return varying amounts of response data.
Basic List Return
def get_fibonacci_sequence(n):
if n <= 0:
return []
elif n == 1:
return [0]
sequence = [0, 1]
for i in range(2, n):
sequence.append(sequence[i-1] + sequence[i-2])
return sequence
# Get fibonacci numbers
fib_numbers = get_fibonacci_sequence(8)
print(f"Fibonacci sequence: {fib_numbers}")
# You can modify the returned list
fib_numbers.append(21)
print(f"Modified sequence: {fib_numbers}")Practical List Example: File Processing
def analyze_text(text):
words = text.split()
word_count = len(words)
char_count = len(text)
char_count_no_spaces = len(text.replace(" ", ""))
# Return as a list for easy modification
return [word_count, char_count, char_count_no_spaces, words]
# Analyze sample text
sample_text = "Python is an amazing programming language"
results = analyze_text(sample_text)
print(f"Word count: {results[0]}")
print(f"Character count: {results[1]}")
print(f"Characters (no spaces): {results[2]}")
print(f"Words: {results[3]}")List Unpacking
def get_min_max_avg(numbers):
if not numbers:
return [None, None, None]
minimum = min(numbers)
maximum = max(numbers)
average = sum(numbers) / len(numbers)
return [minimum, maximum, average]
# Unpack the list
data = [15, 23, 8, 42, 16, 4]
min_val, max_val, avg_val = get_min_max_avg(data)
print(f"Minimum: {min_val}")
print(f"Maximum: {max_val}")
print(f"Average: {avg_val:.2f}")💡 When to Use Lists for Multiple Returns
Use lists when:
- You need to modify the returned values
- The number of returned items varies
- You’re returning a collection of similar items
- You want to use list methods like append, extend, etc.
Advantages of Using Lists for Multiple Returns
- Mutable – can be modified after return
- Dynamic size
- Rich set of built-in methods
- Supports all sequence operations
Limitations of Using Lists for Multiple Returns
- More memory overhead than tuples
- Mutable (can be accidentally modified)
- No named access to elements
- Less conventional for multiple returns
Method 3: Using Dictionaries
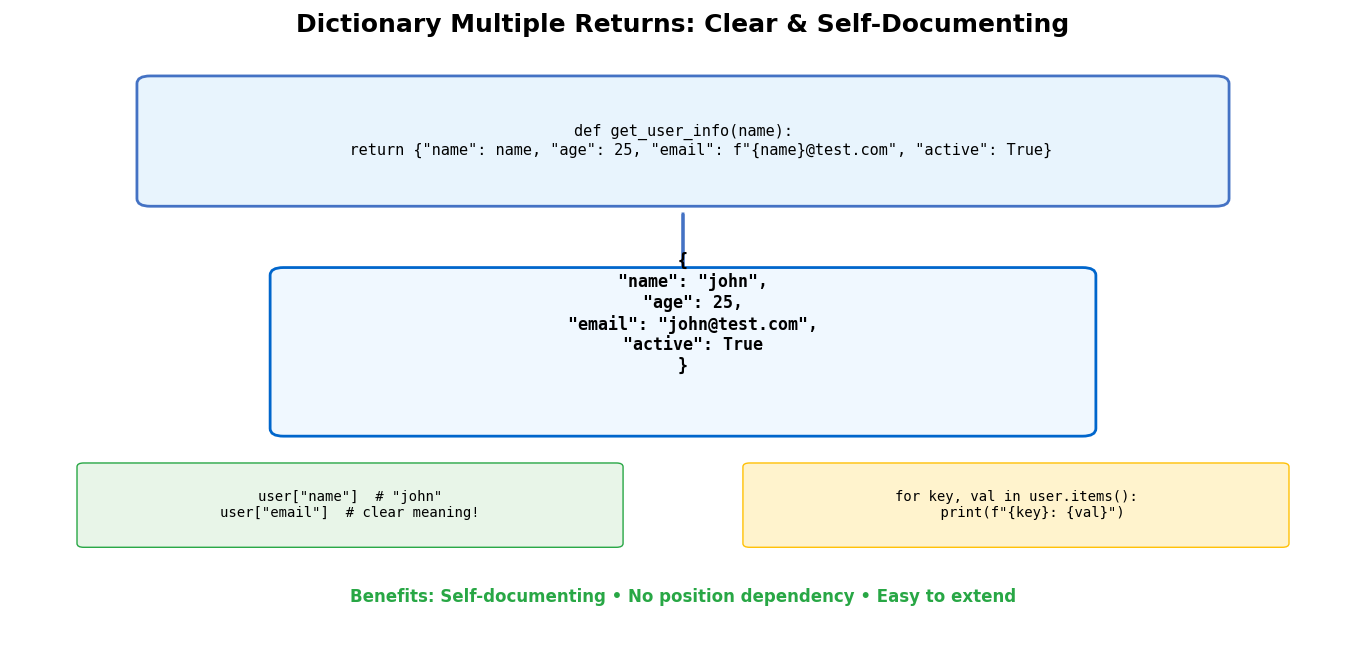
Dictionaries provide named access to returned values, making your code more readable and self-documenting. Think of dictionaries as labeled storage boxes where each item has a clear name tag, so you always know exactly what you’re getting. This approach eliminates confusion about which value represents what, especially when returning many values or when the meaning of each value isn’t obvious from context.
This method shines when building complex applications, such as Flask web applications where functions need to return multiple pieces of structured data that other parts of your program will use.
Basic Dictionary Return
def get_person_info():
return {
'name': 'John Doe',
'age': 30,
'city': 'New York',
'profession': 'Software Engineer'
}
# Access values by name
person = get_person_info()
print(f"Name: {person['name']}")
print(f"Age: {person['age']}")
print(f"City: {person['city']}")
print(f"Profession: {person['profession']}")Advanced Dictionary Example: Data Analysis
def analyze_sales_data(sales):
if not sales:
return {
'total_sales': 0,
'average_sale': 0,
'max_sale': 0,
'min_sale': 0,
'num_transactions': 0
}
total = sum(sales)
count = len(sales)
return {
'total_sales': total,
'average_sale': total / count,
'max_sale': max(sales),
'min_sale': min(sales),
'num_transactions': count,
'sales_data': sales.copy() # Include original data
}
# Example usage
daily_sales = [250, 180, 320, 150, 275, 200]
analysis = analyze_sales_data(daily_sales)
print("=== Sales Analysis Report ===")
print(f"Total Sales: ${analysis['total_sales']}")
print(f"Average Sale: ${analysis['average_sale']:.2f}")
print(f"Highest Sale: ${analysis['max_sale']}")
print(f"Lowest Sale: ${analysis['min_sale']}")
print(f"Number of Transactions: {analysis['num_transactions']}")Dictionary with Nested Data
def process_student_grades(grades):
total_points = sum(grades)
average = total_points / len(grades)
# Determine letter grade
if average >= 90:
letter_grade = 'A'
elif average >= 80:
letter_grade = 'B'
elif average >= 70:
letter_grade = 'C'
elif average >= 60:
letter_grade = 'D'
else:
letter_grade = 'F'
return {
'grades': {
'individual_scores': grades,
'total_points': total_points,
'average': average,
'letter_grade': letter_grade
},
'statistics': {
'highest_score': max(grades),
'lowest_score': min(grades),
'score_range': max(grades) - min(grades)
},
'passing': average >= 60
}
# Example usage
student_scores = [85, 92, 78, 88, 91]
result = process_student_grades(student_scores)
print(f"Average: {result['grades']['average']:.1f}")
print(f"Letter Grade: {result['grades']['letter_grade']}")
print(f"Highest Score: {result['statistics']['highest_score']}")
print(f"Passing: {result['passing']}")Advantages of Using Dictionaries for Multiple Returns
- Named access to values
- Self-documenting code
- Can return complex nested data
- Easy to extend with new fields
- No need to remember order
Limitations of Using Dictionaries for Multiple Returns
- More memory overhead
- Slightly slower access
- More verbose syntax
- Key names must be strings/hashable
Method 4: Using Data Classes (Python 3.7+)
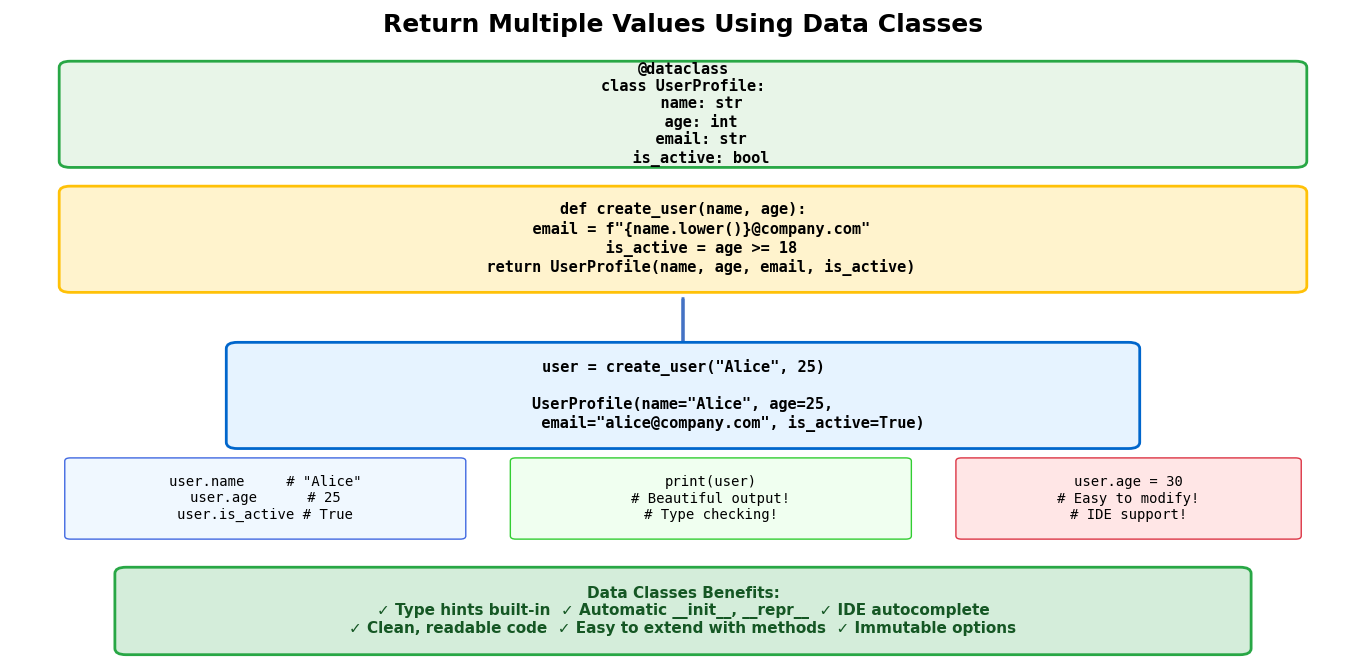
Data classes provide a clean, type-safe way to return multiple values. Think of data classes as custom-designed containers that are specifically built for your exact needs – like having a toolbox where each compartment is perfectly sized for a specific tool. They offer the benefits of named access like dictionaries but with better performance and type checking support, which means your code editor can help catch errors before you even run your program.
Data classes are particularly valuable in professional software development because they make your code more maintainable and less prone to bugs. Learn more about data classes in Python’s official dataclasses documentation. They work exceptionally well when working with function parameters and return values in complex applications.
Basic Data Class Example
from dataclasses import dataclass
@dataclass
class PersonInfo:
name: str
age: int
email: str
salary: float
def get_employee_data(employee_id):
# Simulate database lookup
return PersonInfo(
name="Sarah Johnson",
age=28,
email="sarah.johnson@company.com",
salary=75000.0
)
# Usage
employee = get_employee_data(12345)
print(f"Name: {employee.name}")
print(f"Age: {employee.age}")
print(f"Email: {employee.email}")
print(f"Salary: ${employee.salary:,.2f}")Advanced Data Class with Methods
from dataclasses import dataclass
from typing import List
@dataclass
class StatisticsResult:
values: List[float]
mean: float
median: float
mode: float
std_dev: float
def summary(self):
return f"Mean: {self.mean:.2f}, Median: {self.median:.2f}, Std Dev: {self.std_dev:.2f}"
def is_normal_distribution(self):
# Simple check: mean and median should be close
return abs(self.mean - self.median) < self.std_dev * 0.1
def calculate_statistics(data):
import statistics
mean_val = statistics.mean(data)
median_val = statistics.median(data)
try:
mode_val = statistics.mode(data)
except statistics.StatisticsError:
mode_val = mean_val # No unique mode
std_dev_val = statistics.stdev(data) if len(data) > 1 else 0
return StatisticsResult(
values=data.copy(),
mean=mean_val,
median=median_val,
mode=mode_val,
std_dev=std_dev_val
)
# Example usage
sample_data = [23, 25, 28, 22, 26, 24, 27, 25, 29, 23]
stats = calculate_statistics(sample_data)
print(stats.summary())
print(f"Appears normal distribution: {stats.is_normal_distribution()}")
print(f"Mode: {stats.mode}")Data Class with Default Values and Post-Init
from dataclasses import dataclass, field
from typing import List, Optional
from datetime import datetime
@dataclass
class ProcessingResult:
success: bool
message: str
data: Optional[dict] = None
errors: List[str] = field(default_factory=list)
timestamp: datetime = field(default_factory=datetime.now)
processing_time: float = 0.0
def __post_init__(self):
if not self.success and not self.errors:
self.errors.append("Unknown error occurred")
def process_user_data(user_input):
import time
start_time = time.time()
try:
# Simulate processing
if not user_input:
return ProcessingResult(
success=False,
message="Empty input provided",
errors=["Input cannot be empty"],
processing_time=time.time() - start_time
)
processed_data = {
'input_length': len(user_input),
'word_count': len(user_input.split()),
'uppercase': user_input.upper()
}
return ProcessingResult(
success=True,
message="Data processed successfully",
data=processed_data,
processing_time=time.time() - start_time
)
except Exception as e:
return ProcessingResult(
success=False,
message=f"Processing failed: {str(e)}",
errors=[str(e)],
processing_time=time.time() - start_time
)
# Example usage
result = process_user_data("Hello Python Programming")
print(f"Success: {result.success}")
print(f"Message: {result.message}")
print(f"Processing time: {result.processing_time:.4f} seconds")
if result.data:
print(f"Word count: {result.data['word_count']}")Advantages of Using Data Classes for Multiple Returns
- Type hints for better IDE support
- Automatic __init__, __repr__, __eq__ methods
- Better performance than dictionaries
- Can include methods and properties
- Immutable option with frozen=True
Limitations of Using Data Classes for Multiple Returns
- Requires Python 3.7+
- More setup code required
- Less flexible than dictionaries
- Need to define class structure beforehand
Method 5: Using Named Tuples
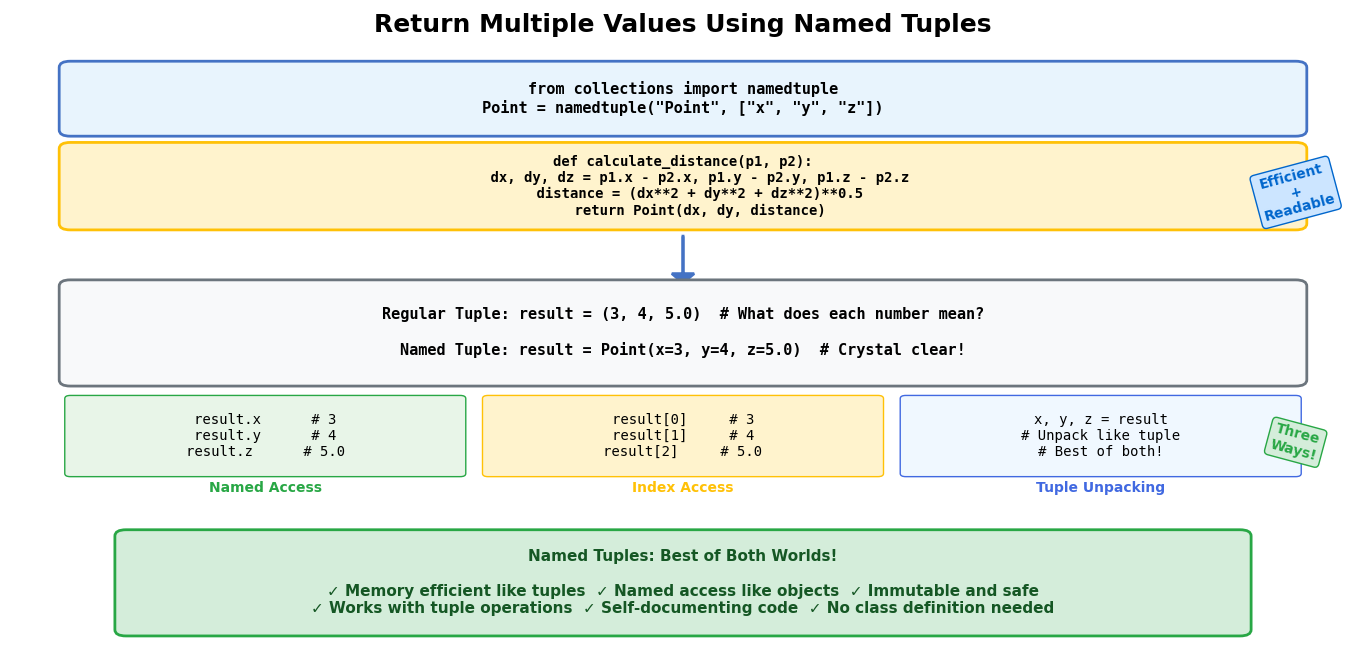
Named tuples combine the memory efficiency of tuples with the readability of dictionaries. Think of named tuples as the best of both worlds – they’re like regular tuples but with labels on each position, making your code much easier to read and understand. They’re immutable (can’t be changed after creation), lightweight (use less memory than dictionaries), and provide named access to fields.
Named tuples are particularly useful when you want the performance benefits of tuples but need the clarity that comes with named fields. They work well with the Python ID function for object identification and are excellent for creating structured data that won’t change throughout your program’s execution.
Basic Named Tuple Example
from collections import namedtuple
# Define the named tuple structure
Point = namedtuple('Point', ['x', 'y'])
def calculate_distance_and_midpoint(p1, p2):
# Calculate distance between two points
distance = ((p2.x - p1.x)**2 + (p2.y - p1.y)**2)**0.5
# Calculate midpoint
midpoint = Point((p1.x + p2.x) / 2, (p1.y + p2.y) / 2)
return distance, midpoint
# Example usage
point1 = Point(0, 0)
point2 = Point(3, 4)
dist, mid = calculate_distance_and_midpoint(point1, point2)
print(f"Distance: {dist}")
print(f"Midpoint: ({mid.x}, {mid.y})")
print(f"Midpoint as tuple: {mid}")Advanced Named Tuple Example
from collections import namedtuple
from typing import List
# Define multiple named tuple types
GradeInfo = namedtuple('GradeInfo', ['letter', 'points', 'percentage'])
StudentStats = namedtuple('StudentStats', ['total_points', 'average', 'grade_info', 'passed'])
def evaluate_student_performance(scores: List[int], max_score: int = 100):
total = sum(scores)
average = total / len(scores)
percentage = (average / max_score) * 100
# Determine letter grade
if percentage >= 90:
letter = 'A'
points = 4.0
elif percentage >= 80:
letter = 'B'
points = 3.0
elif percentage >= 70:
letter = 'C'
points = 2.0
elif percentage >= 60:
letter = 'D'
points = 1.0
else:
letter = 'F'
points = 0.0
grade_info = GradeInfo(letter, points, percentage)
passed = percentage >= 60
return StudentStats(total, average, grade_info, passed)
# Example usage
test_scores = [88, 92, 85, 90, 87]
results = evaluate_student_performance(test_scores)
print(f"Total Points: {results.total_points}")
print(f"Average Score: {results.average:.1f}")
print(f"Letter Grade: {results.grade_info.letter}")
print(f"GPA Points: {results.grade_info.points}")
print(f"Percentage: {results.grade_info.percentage:.1f}%")
print(f"Passed: {results.passed}")Named Tuple with Methods (Using _make and _asdict)
from collections import namedtuple
# Define a named tuple for RGB colors
Color = namedtuple('Color', ['red', 'green', 'blue'])
def analyze_color(rgb_values):
# Create color using _make
color = Color._make(rgb_values)
# Calculate brightness
brightness = (color.red * 0.299 + color.green * 0.587 + color.blue * 0.114)
# Determine if color is light or dark
is_light = brightness > 128
# Create complementary color
complement = Color(255 - color.red, 255 - color.green, 255 - color.blue)
# Return analysis results
Analysis = namedtuple('Analysis', ['original', 'brightness', 'is_light', 'complement'])
return Analysis(color, brightness, is_light, complement)
# Example usage
rgb = [100, 150, 200]
analysis = analyze_color(rgb)
print(f"Original color: RGB{analysis.original}")
print(f"Brightness: {analysis.brightness:.1f}")
print(f"Is light color: {analysis.is_light}")
print(f"Complement: RGB{analysis.complement}")
# Convert to dictionary for JSON serialization
color_dict = analysis.original._asdict()
print(f"As dictionary: {color_dict}")Advantages of Using Named Tuples for Multiple Returns
- Memory efficient like regular tuples
- Named access to fields
- Immutable and hashable
- Compatible with tuple operations
- Built-in methods like _asdict(), _make()
Limitations of Using Named Tuples for Multiple Returns
- Immutable (can’t change values)
- No default values
- Limited to simple data structures
- Less feature-rich than data classes
Comparison of Methods
Here’s a comprehensive comparison of all methods for returning multiple values. Understanding these differences will help you choose the right approach for your specific situation, whether you’re building a simple calculator or a complex data analysis system:
| Feature | Tuples | Lists | Dictionaries | Data Classes | Named Tuples |
|---|---|---|---|---|---|
| Memory Usage | Lowest | Medium | Highest | Low-Medium | Lowest |
| Named Access | No | No | Yes | Yes | Yes |
| Mutability | Immutable | Mutable | Mutable | Configurable | Immutable |
| Type Hints | Complex | Simple | Complex | Excellent | Good |
| Performance | Fastest | Fast | Slower | Fast | Fastest |
| Setup Required | None | None | None | Class Definition | Type Definition |
| Best Use Case | Simple, temporary | Variable length | Complex, nested | Structured, typed | Fixed structure |
When to Use Each Method
Decision Guide for Python Multiple Return Methods
- Use Tuples when: You need simple, temporary multiple returns and order is logical. Perfect for mathematical operations, coordinate calculations, or statistical computations where the meaning is clear from context.
- Use Lists when: The number of returned items varies or you need to modify them after the function returns. Great for collecting search results, processing variable amounts of user input, or handling dynamic data sets.
- Use Dictionaries when: You have many values or need descriptive names for better code readability. Ideal for configuration settings, user profiles, API responses, or any complex data structure with named fields.
- Use Data Classes when: You want type safety and may add methods later. Perfect for professional applications where code maintainability, debugging, and team collaboration are crucial.
- Use Named Tuples when: You want named access but also immutability and memory efficiency. Excellent for coordinate systems, database records, or any fixed-structure data that won’t change during program execution.
Interactive Function Tester
Test Multiple Return Value Functions
Try out different functions that return multiple values. Enter your inputs and see the results!
Best Practices
1. Choose the Right Method
Consider the context and requirements of your specific situation. The choice of method can significantly impact code readability, performance, and maintainability:
- For 2-3 related values: Use tuples when the relationship between values is obvious and order makes sense
- For configuration/settings: Use dictionaries or data classes when you need named access to prevent confusion
- For mathematical coordinates: Use named tuples for clarity while maintaining performance
- For API responses: Use data classes with type hints for professional applications that need validation
- For chatbot responses: Consider dictionaries when building chatbot applications that return multiple pieces of contextual information
2. Use Descriptive Function Names
When your function returns multiple values, the name should clearly indicate this behavior. Think of function names as newspaper headlines – they should tell the full story at a glance. This becomes especially important when working with function parameters and return values in larger applications.
# Good: Function name indicates multiple returns
def calculate_min_max_avg(numbers):
return min(numbers), max(numbers), sum(numbers) / len(numbers)
# Better: Clear documentation
def analyze_dataset(data):
"""
Analyze a dataset and return summary statistics.
Args:
data: List of numbers to analyze
Returns:
tuple: (minimum, maximum, average) of the dataset
"""
return min(data), max(data), sum(data) / len(data)3. Use Type Hints for Clarity
Type hints act like road signs for your code – they tell other programmers (and your future self) exactly what to expect. This becomes critical when building larger applications or working in teams where clear communication about data types prevents errors and confusion.
from typing import Tuple, Dict, List
def process_scores(scores: List[int]) -> Tuple[float, str, bool]:
"""Process student scores and return average, grade, and pass status."""
avg = sum(scores) / len(scores)
grade = 'A' if avg >= 90 else 'B' if avg >= 80 else 'C'
passed = avg >= 60
return avg, grade, passed4. Handle Edge Cases
Edge cases are like potholes in a road – they’re unexpected situations that can break your program if you don’t plan for them. When returning multiple values, always consider what happens when inputs are invalid, empty, or unusual. This defensive programming approach prevents crashes and creates more reliable applications.
def safe_divide_with_remainder(a, b):
"""
Safely divide two numbers and return quotient, remainder, and success status.
Args:
a (int): The dividend
b (int): The divisor
Returns:
tuple: (quotient, remainder, success_flag)
Returns (0, 0, False) if division by zero
"""
if b == 0:
return 0, 0, False # quotient, remainder, success
quotient = a // b
remainder = a % b
return quotient, remainder, True5. Consider Performance
Performance optimization becomes critical as Python applications scale and process increasing data volumes. Different multiple return value methods exhibit varying performance characteristics depending on use case requirements. Understanding these performance implications enables developers to make informed decisions about which approach best suits their specific application needs.
Memory efficiency, execution speed, and maintainability form the primary considerations when selecting multiple return value strategies. High-frequency function calls benefit from lightweight tuple implementations, while complex applications requiring extensive data manipulation may justify the overhead of dictionaries or data classes for enhanced functionality.
Performance Optimization Guidelines for Multiple Return Values
- Tuple Performance Advantages: Tuples and named tuples provide optimal performance for multiple return values due to minimal memory overhead, faster creation times, and efficient memory allocation. These data structures excel in high-frequency function calls and memory-constrained environments.
- Dictionary Performance Trade-offs: Dictionaries introduce computational overhead through hash table operations and key-value pair management, but provide significant advantages for complex data structures requiring named field access and dynamic key manipulation.
- Data Class Performance Balance: Data classes offer moderate performance with enhanced functionality including type checking, method integration, and IDE support, making them suitable for professional development environments where maintainability outweighs minor performance costs.
- Large Data Structure Considerations: Frequent returns of large data structures impact application performance through increased memory allocation, garbage collection overhead, and data transfer costs. Consider implementing data streaming or pagination for large dataset operations.
- Memory Management Strategies: Long-running applications require careful memory usage monitoring when implementing multiple return value patterns. Implement proper cleanup procedures and consider using generators for memory-efficient data processing workflows.
Test Your Knowledge
Python Multiple Return Values Quiz
Question 1: Which method is most memory efficient for returning multiple values?
Question 2: Which method provides named access to returned values?
Question 3: What happens when you return multiple values separated by commas?
Question 4: Which is true about data classes for multiple returns?
Question 5: What’s the best choice for returning a variable number of items?
Real World Examples
Example 1: Database Query Function
from dataclasses import dataclass
from typing import List, Optional
@dataclass
class QueryResult:
data: List[dict]
count: int
success: bool
error_message: Optional[str] = None
execution_time: float = 0.0
def execute_database_query(sql_query: str) -> QueryResult:
"""Execute a database query and return comprehensive results."""
import time
start_time = time.time()
try:
# Simulate database query
if "SELECT" in sql_query.upper():
# Mock data for demonstration
mock_data = [
{'id': 1, 'name': 'Alice', 'age': 28},
{'id': 2, 'name': 'Bob', 'age': 34}
]
execution_time = time.time() - start_time
return QueryResult(
data=mock_data,
count=len(mock_data),
success=True,
execution_time=execution_time
)
else:
raise ValueError("Only SELECT queries supported in demo")
except Exception as e:
return QueryResult(
data=[],
count=0,
success=False,
error_message=str(e),
execution_time=time.time() - start_time
)
# Usage example
result = execute_database_query("SELECT * FROM users")
if result.success:
print(f"Found {result.count} records in {result.execution_time:.4f} seconds")
for row in result.data:
print(f" {row['name']} (age {row['age']})")
else:
print(f"Query failed: {result.error_message}")Example 2: File Processing Function
from collections import namedtuple
from typing import List
FileStats = namedtuple('FileStats', [
'lines', 'words', 'characters', 'size_bytes'
])
ProcessingInfo = namedtuple('ProcessingInfo', [
'success', 'processing_time', 'errors'
])
def analyze_text_file(content: str) -> tuple[FileStats, ProcessingInfo]:
"""Analyze text content and return statistics and processing info."""
import time
start_time = time.time()
errors = []
try:
if not content:
errors.append("Empty content provided")
return (
FileStats(0, 0, 0, 0),
ProcessingInfo(False, time.time() - start_time, errors)
)
lines = len(content.split('\n'))
words = len(content.split())
characters = len(content)
size_bytes = len(content.encode('utf-8'))
stats = FileStats(lines, words, characters, size_bytes)
info = ProcessingInfo(True, time.time() - start_time, [])
return stats, info
except Exception as e:
errors.append(str(e))
return (
FileStats(0, 0, 0, 0),
ProcessingInfo(False, time.time() - start_time, errors)
)
# Usage example
sample_text = """Python is a powerful programming language.
It's great for beginners and experts alike.
This is a sample text for analysis."""
file_stats, proc_info = analyze_text_file(sample_text)
if proc_info.success:
print(f"Analysis completed in {proc_info.processing_time:.4f} seconds")
print(f"Lines: {file_stats.lines}")
print(f"Words: {file_stats.words}")
print(f"Characters: {file_stats.characters}")
print(f"Size: {file_stats.size_bytes} bytes")
else:
print(f"Analysis failed: {proc_info.errors}")Example 3: Web API Response Handler
This example shows how you might handle responses from web APIs when building Flask applications. APIs are like asking questions to other websites and getting structured answers back – but you need to handle both successful responses and potential errors.
def make_api_request(url: str) -> dict:
"""
Make an API request and return comprehensive response data.
This function demonstrates how to handle web API responses by returning
multiple pieces of information: success status, data, timing, and errors.
It's like making a phone call and getting back not just the answer,
but also info about call quality, duration, and any problems.
"""
import time
start_time = time.time()
# Simulate API call (in real code, you'd use requests library)
try:
if "invalid" in url.lower():
raise Exception("Invalid URL provided")
# Simulate successful API response
response_data = {
'users': [
{'id': 1, 'username': 'john_doe', 'active': True},
{'id': 2, 'username': 'jane_smith', 'active': True}
],
'total_count': 2,
'page': 1
}
return {
'success': True,
'status_code': 200,
'data': response_data,
'response_time': time.time() - start_time,
'headers': {'content-type': 'application/json'},
'error': None,
'cached': False
}
except Exception as e:
return {
'success': False,
'status_code': 500,
'data': None,
'response_time': time.time() - start_time,
'headers': {},
'error': str(e),
'cached': False
}
# Usage example
api_response = make_api_request("https://api.example.com/users")
if api_response['success']:
print(f"API call successful (Status: {api_response['status_code']})")
print(f"Response time: {api_response['response_time']:.3f} seconds")
print(f"Users found: {len(api_response['data']['users'])}")
print(f"Total in database: {api_response['data']['total_count']}")
else:
print(f"API call failed: {api_response['error']}")
print(f"Failed after {api_response['response_time']:.3f} seconds")Frequently Asked Questions
Absolutely! Python functions can return values of completely different types together. Think of it like a delivery package that contains a book, a toy, a snack, and a note – all different items but delivered together in one package. This flexibility makes Python incredibly powerful for real-world applications.
def mixed_return():
# Return text, number, list, and boolean together
return "Hello", 42, [1, 2, 3], True
# Each variable gets its appropriate type
text, number, list_data, boolean = mixed_return()
print(f"Text: {text}, Number: {number}, List: {list_data}, Boolean: {boolean}")This is particularly useful when building applications that need to return status information along with data, such as when working with Flask web applications.
Python doesn’t have a built-in limit on the number of values you can return – you could theoretically return dozens of values if needed. However, for practical purposes and code readability, consider using dictionaries or data classes when returning more than 4-5 values. Think of it like carrying groceries: you can carry many items in your hands, but it becomes much easier and safer to use a shopping cart when you have more than a few items.
For larger applications or when working with complex data structures, structured approaches like data classes provide better organization and prevent mistakes.
If you don’t unpack all values, Python will assign the entire tuple to a single variable:
def get_three_values():
return 1, 2, 3
result = get_three_values() # result is (1, 2, 3)
a, b = get_three_values() # ValueError: too many values to unpackYes! You can use Python’s destructuring assignment with tuples, lists, and even some other structures:
# Basic destructuring
a, b, c = get_tuple_values()
# With asterisk for remaining values
first, *rest, last = get_list_values()
# Nested destructuring
(x, y), z = get_nested_values()For API responses, dictionaries or data classes are usually best because they provide named access to fields and can easily be converted to JSON. Data classes are preferred when you want type safety and IDE support.
You can use None for optional values or employ data classes/dictionaries with default values:
def optional_return(include_extra=False):
base_value = 42
extra_value = "bonus" if include_extra else None
return base_value, extra_valueExternal Resources
Want to learn more? Check out these helpful resources:
- Python Documentation: Defining Functions – Official guide to Python functions
- Python Documentation: Tuples and Sequences – Learn about tuples and other sequence types
- Python Documentation: Data Classes – Complete guide to data classes





: A Step-by-Step Guide")
Leave a Reply