

LLaSA-3B: The Next Evolution in Text-to-Speech Technology
Introduction
Artificial intelligence is growing fast, and text-to-speech (TTS) technology has come a long way. It started with robotic voices that sounded flat and monotone. Now, TTS voices sound much more natural. This change has been truly impressive. Now, there’s LLaSA-3B—a new TTS model that takes things to the next level. It’s built on Llama 3.2B, a powerful AI system. But LLaSA-3B isn’t just another TTS model. It brings ultra-realistic audio that sounds almost human. It can express emotions more naturally and supports many languages.
In this post, we’ll talk about why LLaSA-3B is so special. It’s more than just a tool—it could change how we use voice technology in the future.
What is LLaSA-3B?
LLaSA-3B is an advanced text-to-speech (TTS) model. It is based on Llama 3.2B, a very powerful open-source system that works with language.
This model can create voices that sound incredibly real—almost like a human speaking. It’s not just about making sound; it can add emotions to the voice, like excitement or sadness, so it feels more natural. It also works in different languages, making it useful for many people.
If you’re a developer, someone creating content, or a business owner, you can use LLaSA-3B for tasks that need realistic and expressive voices. It’s a tool that fits many needs and helps make technology feel more human.
Key Features of LLaSA-3B

Ultra-Realistic Audio
LLaSA-3B is known for creating speech that sounds incredibly human. Older TTS systems often produced voices that were robotic and lifeless, lacking the natural flow of real speech. LLaSA-3B changes this by using advanced neural networks. These networks add natural intonation (the rise and fall of voice), smooth rhythm (how the words are spaced), and clear pronunciation.
This ultra-realistic audio makes LLaSA-3B perfect for many uses. Audiobooks become more engaging because the voice feels real. Virtual assistants like smart speakers or chatbots sound more friendly and approachable. Even voiceovers for ads, presentations, or videos feel professional and polished, thanks to this natural-sounding technology.
Emotional Expressiveness
What makes LLaSA-3B truly unique is its ability to express emotions. It doesn’t just speak words; it adds feelings to them. Whether the tone needs to be excited, calm, sad, or even angry, LLaSA-3B adjusts its voice to match the mood of the text.
This emotional flexibility creates many exciting opportunities. In storytelling, it can make characters and plots feel more alive. For customer service bots, it allows them to sound more empathetic and understanding, improving the customer experience. Even in therapeutic applications, such as apps that provide emotional support, this feature helps create a sense of care and connection.
Multilingual Support
In today’s globalized world, speaking multiple languages is important. LLaSA-3B offers support for many languages, making it an excellent tool for reaching global audiences. From English and Spanish to Mandarin and Hindi, it provides high-quality, natural-sounding speech in different languages.
Fine-Tuned on Llama 3.2B
The backbone of LLaSA-3B is the Llama 3.2B model, known for its efficiency and scalability. By fine-tuning this architecture specifically for TTS, LLaSA-3B achieves a perfect balance between performance and resource efficiency. This makes it accessible for both large-scale enterprises and individual developers.
How Does LLaSA-3B Work?
LLaSA-3B uses a mix of deep learning and neural text-to-speech (TTS) technology to turn written text into speech. Here’s a clearer look at how it works:
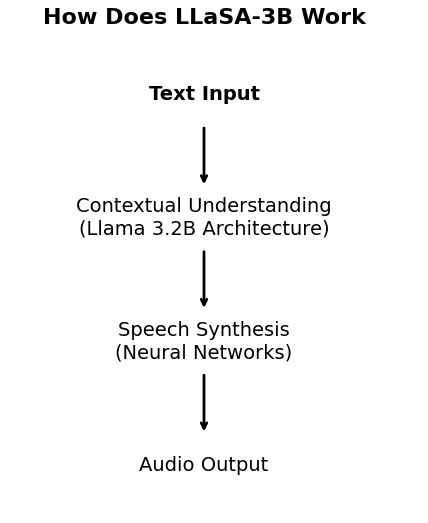
1. Text Input
First, you give LLaSA-3B some text. This can be anything from a single sentence to a whole document. The text could be a story, a question, a set of instructions, or even just a few words. The model starts by receiving this text as input, and this is the very first step of the process.
2. Contextual Understanding
Once the model has the text, it needs to understand it. This step is like when we read a book and try to understand the meaning of the words and sentences.
LLaSA-3B uses a special system, called the Llama 3.2B architecture, to help with this. The architecture is like the brain of the model. It looks at the text and tries to figure out what the words mean in relation to each other.
For example, if the sentence is a question, like “How are you today?”, the model understands that a question needs to sound different from a statement. It also looks for emotional clues in the text. If the sentence talks about something sad, it will know the voice should sound sad.
3. Speech Synthesis
After the model understands the text and what emotions are involved, it moves on to speech synthesis. This is the part where the text is turned into spoken words.
LLaSA-3B uses neural networks (a kind of technology that helps the model learn and improve) to do this. These networks know how to turn the words into speech that sounds real. It doesn’t just read the words one by one in a flat, robotic voice.
Instead, the model makes the speech sound like it’s coming from a human. It adds things like intonation (how the pitch of the voice goes up and down), rhythm (the speed of the speech), and pauses (moments where the speaker stops to breathe or think). These things are what make human speech feel natural.
Also, if the text is emotional—let’s say the text talks about excitement or sadness—the model can adjust the tone of the voice. For excitement, it might make the voice faster and higher-pitched. For sadness, it might slow down and make the voice sound softer.
4. Audio Output
Once LLaSA-3B has created the speech, it turns it into an audio file. This audio file is what you hear when the model speaks. The voice sounds clear, natural, and lifelike. It’s not like the old computer voices that were hard to understand.
The final audio is human-like. Whether you want to use it in a voice assistant, an audiobook, or a customer service bot, the audio is ready to go. It will sound like a person speaking, with all the right emotions and the correct rhythm and flow.
Step-by-Step Guide: How to Use LLaSA-3B for Your Own Projects

Step 1: Set Up Your Environment
Before you begin, ensure your system meets the following requirements:
- Python 3.8 or higher
- GPU (optional but recommended for faster processing)
- CUDA Toolkit (if using an NVIDIA GPU)
- Install Python: If you don’t have Python installed, download and install it from python.org.
- Set Up a Virtual Environment (optional but recommended):
python -m venv llasa_env
source llasa_env/bin/activate # On Windows: llasa_env\Scripts\activate3. Install Required Libraries:
pip install torch transformers soundfileStep 2: Download the LLaSA-3B Model
LLaSA-3B is likely hosted on platforms like Hugging Face Model Hub. You can load the model using the transformers library.
- Install the
transformerslibrary (if not already installed):
pip install transformers2. Load the LLaSA-3B Model:
from transformers import pipeline
# Load the LLaSA-3B model
tts_pipeline = pipeline("text-to-speech", model="LLaSA-3B")Step 3: Generate Speech from Text
Now that the model is loaded, you can start generating speech from text.
- Basic Text-to-Speech Conversion:
text = "Hello, welcome to the world of LLaSA-3B! This is an example of ultra-realistic text-to-speech."
# Generate speech
audio_output = tts_pipeline(text)
# Save the audio to a file
import soundfile as sf
sf.write("output.wav", audio_output["audio"], samplerate=audio_output["sampling_rate"])This will save the generated speech as output.wav in your working directory.
Step 4: Customize Emotional Tone
LLaSA-3B allows you to specify the emotional tone of the speech. For example, you can generate speech with a “happy” or “sad” tone.
- Generate Speech with Emotional Expressiveness:
emotional_text = "I can't believe this is happening! This is amazing!"
audio_output = tts_pipeline(emotional_text, emotion="excited")
# Save the audio
sf.write("excited_output.wav", audio_output["audio"], samplerate=audio_output["sampling_rate"])Step 5: Explore Multilingual Support
LLaSA-3B supports multiple languages. To generate speech in a different language, simply input text in the desired language.
- Generate Speech in Spanish:
spanish_text = "¡Hola! Esto es un ejemplo de texto a voz en español."
audio_output = tts_pipeline(spanish_text, language="es")
# Save the audio
sf.write("spanish_output.wav", audio_output["audio"], samplerate=audio_output["sampling_rate"])Step 6: Integrate LLaSA-3B into Your Application
You can integrate LLaSA-3B into various applications, such as web apps, virtual assistants, or content creation tools.
- Example: Integrate with a Flask Web App:
from flask import Flask, request, send_file
import soundfile as sf
app = Flask(__name__)
@app.route("/generate-speech", methods=["POST"])
def generate_speech():
text = request.json["text"]
audio_output = tts_pipeline(text)
sf.write("temp_output.wav", audio_output["audio"], samplerate=audio_output["sampling_rate"])
return send_file("temp_output.wav", as_attachment=True)
if __name__ == "__main__":
app.run(debug=True)Run the Flask app and send a POST request with JSON data containing the text to generate speech.
Step 7: Optimize for Performance
If you’re working with large-scale applications, consider the following optimizations:
- Batch Processing:
Process multiple text inputs simultaneously to save time.
texts = ["Hello, world!", "This is a batch processing example."]
audio_outputs = tts_pipeline(texts)Model Quantization:
Reduce the model size and improve inference speed using quantization techniques.
from transformers import TTSModel
quantized_model = TTSModel.from_pretrained("LLaSA-3B", torch_dtype=torch.float16)- Cloud Deployment:
Deploy LLaSA-3B on cloud platforms like AWS, Google Cloud, or Azure for scalability.
Step 8: Experiment and Iterate
LLaSA-3B is highly flexible. Experiment with different:
- Emotional tones: Test how different emotions impact the output.
- Languages: Explore the model’s multilingual capabilities.
- Use Cases: Adapt the model to your specific needs, whether it’s for entertainment, education, or business.
Step 9: Troubleshooting and Tips
- Out of Memory Errors: If you encounter memory issues, try reducing the batch size or using a smaller model variant.
- Slow Performance: Ensure you’re using a GPU for faster processing. If a GPU is unavailable, consider using cloud-based solutions.
- Audio Quality Issues: Experiment with different sampling rates or post-processing techniques to enhance audio quality.
Must Read
- Why sorted() Is Safer Than list.sort() in Production Python Systems
- Monotonic Sequence in Python: 7 Practical Methods With Edge Cases, Interview Tips, and Performance Analysis
- How to Check if Dictionary Values Are Sorted in Python
- Check If a Tuple Is Sorted in Python — 5 Methods Explained
- How to Check If a List Is Sorted in Python (Without Using sort()) – 5 Efficient Methods
Applications of LLaSA-3B

1. Virtual Assistants and Chatbots
LLaSA-3B helps make virtual assistants (like Siri or Alexa) sound more natural and friendly. Instead of sounding robotic, the assistant can speak with the right tone based on the situation, making conversations feel more like talking to a person. This is great for things like helping with tasks or answering questions.
2. Audiobooks and Podcasts
If you create audiobooks or podcasts, LLaSA-3B can help turn your written content into high-quality audio. It reads the text with the right emotions—like excitement or calmness—so it feels more interesting to listen to. This saves time and money compared to recording a person to read the text.
3. E-Learning and Education
LLaSA-3B can make learning materials more engaging. If you want to create interactive lessons or explain difficult ideas, LLaSA-3B can read the material aloud in a way that’s easy to understand. It also supports multiple languages, so it’s perfect for students around the world.
4. Customer Service
With LLaSA-3B, businesses can use it for customer support. It reads customer messages and replies with a tone that fits the situation—for example, calm and reassuring when a customer is frustrated. This makes conversations feel more personal and can help improve customer satisfaction.
5. Accessibility
LLaSA-3B helps people with visual impairments or those who have trouble reading. It can turn written content into speech, so people can listen to books, websites, or articles instead of reading them. It also uses natural-sounding speech, making it easier for people to understand and enjoy the content.
Conclusion
LLaSA-3B is not just a regular text-to-speech model. It’s a new step forward in voice technology. With its ability to sound very realistic, express emotions, and speak in many languages, it is ready to change the way we use AI.
This model is helping us see what is possible when we push the limits of technology and creativity. LLaSA-3B shows the amazing potential of artificial intelligence.
Are you excited to hear the next level of AI voices? The future of sound with LLaSA-3B is incredible.
FAQs
LLaSA-3B is a text-to-speech model that creates ultra-realistic, emotional, and multilingual voices. It’s great for apps like virtual assistants, audiobooks, and customer service.
Yes, if it’s under an open-source license like Apache 2.0 or MIT. Always check the license to be sure.
A GPU is best for fast results, but a CPU will work too (though slower). For big projects, use cloud platforms like AWS or Google Cloud.
Yes! You can:
Train it on your own data.
Add emotions like “happy” or “sad.”
Support more languages.
Use it in apps with tools like Flask.
External Resources
- Hugging Face Model Repository: This page provides access to the LLaSA-3B model, including installation instructions and example code for text-to-speech synthesis. You can find it here.
- Hugging Face Blog Post: An informative article discussing the capabilities of LLaSA as a state-of-the-art text-to-speech and zero-shot voice cloning model, highlighting its realistic audio generation. Read more here.
- GitHub Repository for Training: This repository contains resources for training the LLaSA model, including details about the datasets used and training methodologies. Access it here.
 Function: The Simple Trick to Checking Data Types")


) – 5 Efficient Methods")

Leave a Reply