

Top 50 Data Science Interview Questions | Part-2
Introduction
In Part 1 of our Top 50 Data Science Interview Questions series, we covered some essential questions that can help you prepare for your next data science interview. But we’re not done yet! Part 2 dives deeper into the world of data science, tackling more advanced questions that interviewers love to ask.
Whether you’re brushing up on machine learning algorithms, fine-tuning your understanding of statistical models, or trying to master those tricky coding challenges, this post will guide you through the concepts that matter. Stay with us as we unpack each question with clear explanations and real-world examples, making sure you feel confident when it’s your turn to shine in the interview room. Ready to continue your journey toward becoming a data science pro? Let’s get started!
Data Engineering
1. What is ETL, and how does it work?
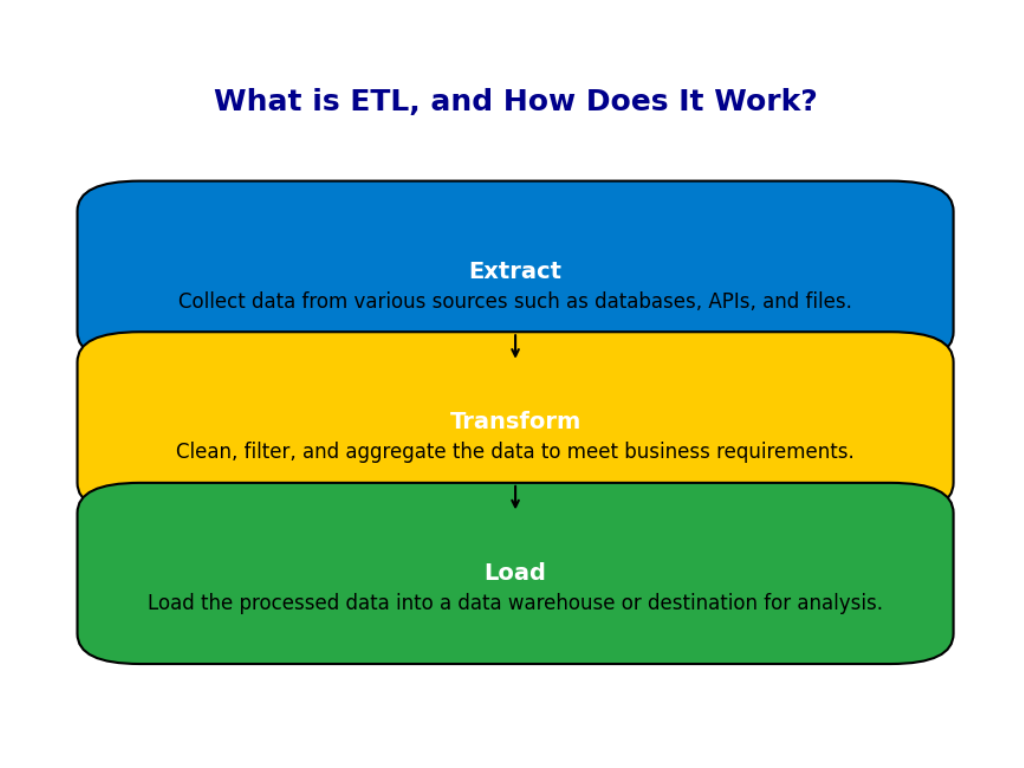
ETL stands for Extract, Transform, and Load, and it’s a key process in data engineering. You start by extracting data from various sources like databases, APIs, or flat files. This step involves pulling raw data that could be stored in different formats, such as structured tables or unstructured text files.
Once the data is extracted, the transformation step begins. This is where data gets cleaned and reshaped. For example, you might convert date formats, remove duplicates, filter out unnecessary records, or merge datasets from different sources. It’s about making the data useful and consistent so it can be easily analyzed.
Finally, the data is loaded into a target system, usually a data warehouse or a database, where it’s ready for analysis. The entire ETL process ensures that the data is accurate, clean, and available in a format that’s easy to work with.
2. Explain the differences between structured and unstructured data.
Structured data is easy to organize and fits into a well-defined model like a table with rows and columns. Think of it like data in a spreadsheet or SQL database, where every entry has a specific place. Since it’s so organized, searching and analyzing structured data is straightforward.
Unstructured data, on the other hand, doesn’t have a predefined structure. This includes things like emails, images, videos, and social media posts. You can’t store it neatly in tables, making it more difficult to manage and analyze. It often requires special tools to extract useful insights, such as natural language processing (NLP) or computer vision for images and video.
3. What is a data warehouse, and how does it differ from a database?
A data warehouse is designed for data analysis and reporting, not for everyday operations. It stores large amounts of data from various sources and is optimized for querying historical data. So, if you need to analyze trends or generate reports over a long period, a data warehouse is the right tool.
A regular database, like the ones used in websites or apps, is built for day-to-day operations. It focuses on quickly reading and writing small, real-time transactions. For example, when you update your profile on a website, it’s using a transactional database.
The key difference is how they’re used. Databases handle quick and frequent transactions, while data warehouses handle complex queries on large datasets.
4. Describe the role of a data engineer in a data science team.
A data engineer’s role is to ensure that data flows smoothly through the systems and is available in a clean and usable format for data scientists. This means designing and building data pipelines that collect data from various sources, clean it, and store it in a way that can be analyzed.
Data engineers are responsible for making sure that data is reliable and accessible. They also optimize systems to handle large volumes of data efficiently. Their work is crucial because data scientists rely on them to provide clean, well-structured data. Without proper data pipelines in place, data scientists would spend most of their time cleaning data rather than analyzing it.
5. What tools do you use for data cleaning and preparation?
When it comes to cleaning and preparing data, I use tools like Pandas and SQL for structured data. Pandas is great for handling datasets in Python, allowing me to filter, clean, and transform data easily. SQL is essential when dealing with large relational databases, as it allows me to query, join, and organize data effectively.
For larger datasets, I often rely on Apache Spark. Spark’s ability to process data across distributed systems makes it a great choice for big data projects. Additionally, I’ve used tools like OpenRefine to clean unstructured data and Airflow to automate the data preparation process.
6. How do you handle data quality issues?
Data quality issues are common, but they can be addressed by following a few steps. First, I run validation checks at the source to ensure that the data coming in meets certain standards. This helps catch errors early on.
When I encounter missing data, I handle it by either filling in the gaps using techniques like imputation (replacing missing values with averages or median values) or removing incomplete records, depending on the situation. Duplicate data is another issue I often encounter. In such cases, I identify duplicates by running queries to compare records, and I remove or merge them as needed.
Another important aspect of maintaining data quality is ensuring consistency. This could involve standardizing date formats or ensuring that data from different sources uses the same measurement units. Documenting these processes is crucial, so that anyone using the data knows what transformations were applied.
7. What is a big data framework you have worked with?
I’ve worked extensively with Apache Spark, which is one of the leading frameworks for processing big data. Spark is known for its speed because it processes data in-memory. Unlike traditional systems that read and write to disk frequently, Spark keeps the data in memory, which speeds things up significantly, especially for iterative tasks like machine learning or real-time analytics.
I’ve used Spark in distributed environments where I needed to process large datasets that couldn’t fit on a single machine. Its flexibility allows me to use Python (with PySpark), Java, or Scala, depending on the project’s needs. Spark’s ability to handle both batch and streaming data makes it a versatile tool for big data projects.
8. How do you design a data pipeline?
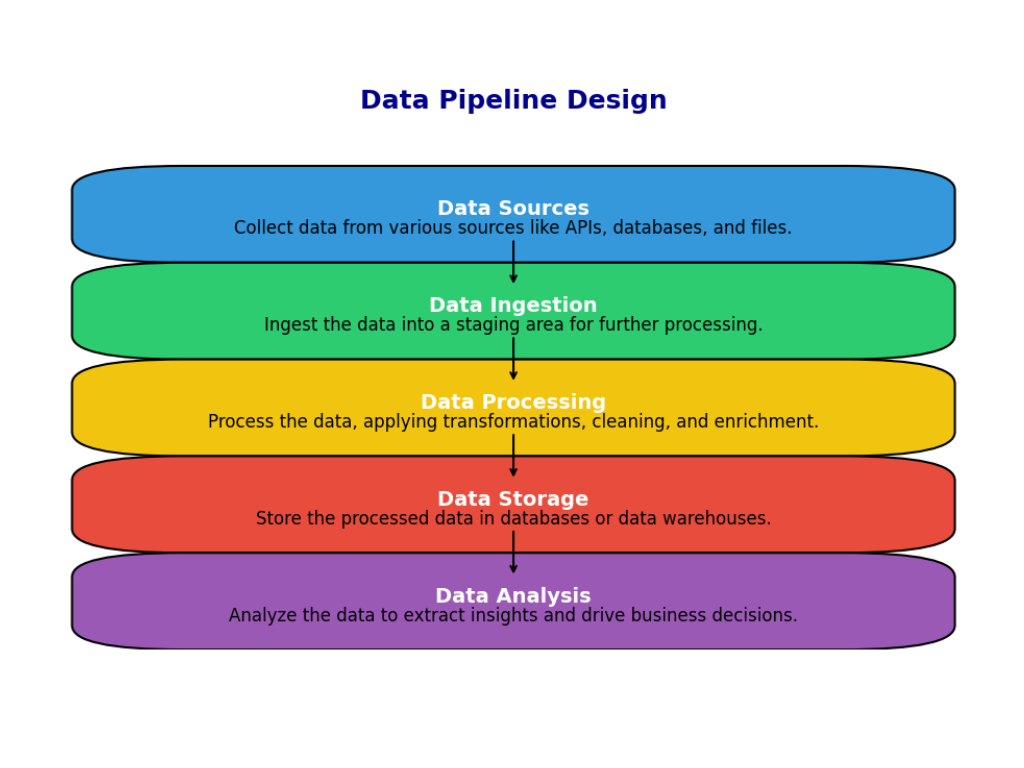
When designing a data pipeline, the first step is to clearly understand where the data is coming from and where it needs to go. I identify all the data sources, such as databases, APIs, or flat files. Then, I set up an extraction process to pull data from these sources.
Once the data is extracted, I apply transformations to clean and format it. This might involve filtering out unnecessary data, converting formats, or merging datasets. After cleaning the data, I load it into the target system, which could be a data warehouse, database, or a data lake.
It’s important to automate the pipeline using tools like Apache Airflow to ensure the process runs on schedule and to monitor it for any issues. If a pipeline fails, I set up alerts so that problems can be addressed quickly.
9. Explain the concept of data lakes.
A data lake is a large repository where you can store all kinds of data—structured, semi-structured, or unstructured. Unlike a data warehouse, which organizes data into specific formats, a data lake keeps data in its raw form. This gives you flexibility because you don’t need to structure the data before storing it.
Data lakes are particularly useful for handling big data and for machine learning projects. You can store raw data now and process it later when you know how you want to analyze it. However, managing a data lake can be tricky, as unstructured data can become hard to organize and search through without proper governance.
10. What is Apache Spark, and how does it differ from Hadoop?
Apache Spark and Hadoop are both big data frameworks, but they have key differences. Spark is much faster because it processes data in-memory. This makes it ideal for real-time analytics and tasks that require repeated data access, like machine learning algorithms.
Hadoop, on the other hand, uses a disk-based system called MapReduce, which writes data to disk after each operation. This makes Hadoop slower, especially for iterative processes. However, Hadoop is more reliable for processing extremely large datasets because of its ability to handle massive amounts of data across many machines.
Real-World Scenarios
11. Describe a data science project you worked on and your role in it.
In one of the key projects I worked on, we aimed to reduce customer churn for an e-commerce platform. The goal was to predict which users were likely to stop using the platform so that the marketing team could take action to retain them. I was part of a data science team that collaborated closely with the marketing and product departments.
My role was centered around data analysis and model development:
- First, I conducted exploratory data analysis (EDA) to understand customer behaviors, using tools like Pandas and Matplotlib. I worked with a variety of data sources, including transaction history, customer demographics, and website interaction logs.
- Next, I built the churn prediction model using a combination of machine learning algorithms like logistic regression, decision trees, and random forests. I also used cross-validation techniques to fine-tune the model’s performance.
- I implemented feature engineering to extract useful features from raw data, such as calculating the average time between purchases and customer lifetime value (CLV).
- Finally, I worked on deploying the model in the company’s data pipeline, which was built on AWS. This allowed the marketing team to automatically receive updates on high-risk customers.
The project resulted in a 20% improvement in churn prediction accuracy, and our efforts led to a 10% decrease in overall churn after targeted interventions by the marketing team.
12. How do you approach solving a new data science problem?
When faced with a new data science problem, I follow a systematic approach that ensures I don’t miss any critical steps:
- Define the Problem: The first step is to clearly understand the business objective. For example, is the goal to increase sales, reduce costs, or improve customer experience? I always make sure the problem is well-defined by discussing it with stakeholders, so I understand the metrics of success.
- Collect and Understand the Data: Next, I gather the necessary data from available sources, whether it’s structured (like databases) or unstructured (like text or images). During this phase, I perform exploratory data analysis (EDA) to uncover patterns, trends, and any missing or noisy data.
- Formulate a Plan: Based on the problem and the data, I decide which algorithms and techniques to use. For example, if it’s a classification problem, I might consider logistic regression or XGBoost, while for a regression task, I’ll explore models like linear regression or random forests.
- Build and Test Models: I experiment with different models and adjust hyperparameters to improve performance. I use techniques like cross-validation to ensure that the model generalizes well and doesn’t overfit the data.
- Communicate Results and Iterate: Once I have the model, I present the findings in a way that’s easy for stakeholders to understand. This often includes creating visualizations that demonstrate how the model performs and discussing how it can be deployed in real-world scenarios. If needed, I make improvements based on feedback.
- Deploy and Monitor: Finally, if the solution is going to be implemented in production, I ensure the model is properly integrated into the company’s data pipeline, with appropriate monitoring to track performance over time.
13. What challenges have you faced in your data science projects, and how did you overcome them?
In one project, the biggest challenge I faced was working with messy and incomplete data. The company was collecting user data from multiple sources, but some data points were missing or inconsistent due to system issues.
To overcome this:
- I used data imputation techniques to fill in missing values. For example, for missing numerical values, I used methods like mean or median imputation, while for categorical data, I used the most frequent value.
- In cases where the data was highly incomplete or noisy, I opted to remove those entries or work with domain experts to figure out the best course of action.
- Another challenge was dealing with imbalanced data, where the target variable (like customers who churn) was only a small percentage of the overall dataset. I used techniques like SMOTE (Synthetic Minority Over-sampling Technique) to create a balanced dataset, which helped improve model performance.
Lastly, implementing the model into production posed challenges, as we needed the model to work efficiently in real-time. I worked closely with the engineering team to optimize the model’s performance by using batch processing and caching techniques to ensure the system could handle high loads without slowing down.
14. How do you stay updated with the latest trends in data science?
Data science is a constantly evolving field, so staying updated is essential. Here’s how I do it:
- I follow well-known data science blogs like Towards Data Science and KDnuggets, where industry experts frequently share their latest insights, tutorials, and research papers.
- I regularly participate in online courses and webinars through platforms like Coursera and edX. For example, I recently completed a course on deep learning techniques for NLP.
- To stay informed about cutting-edge research, I read academic papers on sites like arXiv and follow discussions in AI conferences like NeurIPS and ICML.
- I also participate in Kaggle competitions to sharpen my practical skills. These competitions expose me to real-world problems and allow me to learn from top practitioners in the community.
- Networking is also key. I attend data science meetups and join forums like Reddit’s r/MachineLearning and Data Science Stack Exchange, where I engage with other professionals and exchange ideas on the latest trends.
By combining these strategies, I stay on top of new technologies, methodologies, and best practices.
15. Describe a time when your analysis influenced a business decision.
In one instance, I worked on a project where my analysis directly impacted a significant business decision for an online retail company. The company was considering launching a new subscription service for its premium customers. My role was to conduct a customer segmentation analysis to determine if there was enough interest in this service.
Using unsupervised learning techniques like K-means clustering, I grouped customers based on their purchasing behavior, engagement levels, and lifetime value. My analysis revealed a distinct group of customers who were highly engaged and spent significantly more than others—an ideal target audience for the subscription service.
Based on these insights, I presented my findings to the management team, showing that launching the service could significantly increase customer loyalty and revenue. The company decided to move forward with the service, and after its launch, they saw a 15% increase in repeat purchases from premium customers.
In this case, my analysis not only provided a clear data-driven recommendation but also helped the business achieve a positive outcome.
Must Read
- How to Diagnose Overfitting in Machine Learning — 9 Proven Tools
- PyTorch Debugging Checklist: A Systematic Framework to Fix Models That Won’t Learn
- Why sorted() Is Safer Than list.sort() in Production Python Systems
- Monotonic Sequence in Python: 7 Practical Methods With Edge Cases, Interview Tips, and Performance Analysis
- How to Check if Dictionary Values Are Sorted in Python
Business and Communication
16. How do you communicate your findings to stakeholders?
Communicating findings is key in data science. It helps stakeholders understand insights and take action. Here’s my approach:
- Know Your Audience: I adjust my language based on who I’m talking to. For technical teams, I use more jargon. For executives, I keep it high-level and focus on key insights.
- Use Visualizations: I create charts and graphs using tools like Tableau or Power BI. Visuals make complex information easier to grasp quickly.
- Tell a Story: I present my findings as a story. I start with the problem, share my methods, and end with insights and recommendations.
- Highlight Key Insights: I summarize the most important findings. I focus on how they relate to the stakeholders’ goals, such as showing how a feature can boost revenue.
- Encourage Interaction: I invite questions during my presentations. This engages the audience and helps me clarify points of confusion.
By following these strategies, I ensure that my findings are understood and lead to informed decisions.
17. What role does a data scientist play in product development?

Data scientists have a vital role in product development. Here’s what they do:
- Understanding User Needs: They analyze user data to find pain points and preferences. This information helps shape product features.
- Data-Driven Insights: They provide insights based on past data. For example, they analyze A/B tests to see which features users prefer.
- Model Development and Testing: Data scientists create algorithms that improve product functions. They might develop recommendation systems to boost user engagement.
- Collaboration with Teams: They work closely with product managers, engineers, and designers. This ensures that data insights are integrated into product development.
- Performance Monitoring: After launching a product, data scientists track its performance using key metrics. They analyze user feedback to make ongoing improvements.
Overall, data scientists help create user-centered products and ensure decisions are based on solid analysis.
18. How do you prioritize projects in a data science team?
Prioritizing projects is essential in a data science team. Here’s how I do it:
- Align with Business Goals: I start by matching projects with the company’s main goals. Projects that drive revenue or reduce costs get priority.
- Evaluate Impact and Effort: I assess each project’s potential impact against the effort needed. I often use an Impact-Effort Matrix to categorize projects.
- Stakeholder Input: I gather input from key stakeholders to understand their priorities. This helps focus on critical projects.
- Resource Availability: I consider the skills and time of my team. If a project requires skills that we don’t have, I may put it on hold.
- Iterative Review: I regularly review project priorities to adapt to changing business needs.
By systematically prioritizing projects, I ensure the data science team focuses on the most valuable initiatives.
19. Describe how you would evaluate the success of a data science project.
Evaluating a data science project’s success involves several steps. Here’s my approach:
- Define Success Metrics: Before starting, I work with stakeholders to define clear success metrics. These could be accuracy, revenue increase, or customer retention.
- Model Performance: I assess the model’s performance using metrics. For classification tasks, I might look at accuracy and F1 scores. For regression, I consider R-squared and Mean Absolute Error (MAE).
- Business Impact: I measure whether project outcomes translate into real business results. This might include increased sales or improved user engagement.
- User Feedback: I gather feedback from users affected by the project. Surveys and A/B testing help assess whether the solution meets their needs.
- Iterative Improvement: I look for ways to adapt or improve the project in the future. Success also means finding opportunities for further value.
This approach helps me determine whether the project was successful and how to enhance it going forward.
20. What metrics would you use to measure the impact of a machine learning model?
To measure a machine learning model’s impact, I use various metrics. The choice depends on the model and context. Here are common metrics:
- Classification Metrics:
- Accuracy: The percentage of correctly classified instances.
- Precision: The ratio of true positive predictions to all predicted positives.
- Recall: The ratio of true positive predictions to actual positives.
- F1 Score: The balance between precision and recall.
- AUC-ROC: A measure of how well the model distinguishes between classes.
- Regression Metrics:
- R-squared: How well the model explains the variance in the dependent variable.
- Mean Absolute Error (MAE): The average of absolute errors between predicted and actual values.
- Mean Squared Error (MSE): The average of the squared errors.
- Business Impact Metrics:
- Return on Investment (ROI): The financial return compared to the costs of the model.
- Customer Satisfaction: Measuring changes in satisfaction or engagement.
- Conversion Rate: Tracking changes in conversion rates after implementing the model.
Using these metrics, I can effectively evaluate the performance and impact of a machine learning model.
Advanced Topics
21. What are Generative Adversarial Networks (GANs)?
Generative Adversarial Networks (GANs) are a type of machine learning model. They consist of two parts: a generator and a discriminator. Here’s how they function:
- Generator: This part creates fake data. It aims to produce data that looks real, such as realistic images.
- Discriminator: This part evaluates the data. It checks whether the data comes from the training set (real) or from the generator (fake).
- Adversarial Training: The generator and discriminator work against each other. The generator improves its ability to create realistic data, while the discriminator enhances its skills in identifying fakes. This process continues until the generator produces data that the discriminator cannot distinguish from real data.
Applications: People use GANs in various areas, such as image generation, video creation, and drug discovery.
22. Explain the concept of reinforcement learning.
Reinforcement learning (RL) is a type of machine learning. It focuses on training agents to make decisions by interacting with an environment. Here are the key components:
- Agent: The agent makes decisions and learns by taking actions in the environment.
- Environment: The environment provides the setting where the agent operates. It can be a game or a robot navigating a room.
- Actions: The agent chooses actions that affect the environment’s state.
- Rewards: The environment gives feedback to the agent based on its actions. Positive rewards encourage the agent, while negative rewards discourage it.
- Policy: The agent uses a strategy to decide actions based on the current state.
The goal of reinforcement learning is to maximize cumulative rewards. The agent learns through trial and error, adjusting its actions based on the rewards received.
Applications: People use RL in robotics, gaming, and autonomous vehicles.
23. What is transfer learning, and when would you use it?
Transfer learning is a technique in machine learning. It allows a model trained on one task to be reused for another related task. Here’s how it works:
- Pre-trained Model: First, someone trains a model on a large dataset for a specific task. For example, an image classification model might train on thousands of images.
- Fine-Tuning: Next, the model adapts to a new task with a smaller dataset. This process, called fine-tuning, saves time and computational resources.
When to Use It:
- Limited Data: Use transfer learning when you have a small dataset for the new task. It can help improve performance.
- Similar Tasks: Use it when the new task is similar to the original task. A pre-trained model can be very beneficial.
Applications: Researchers commonly use transfer learning in image recognition, natural language processing, and speech recognition.
24. Describe the concept of natural language processing (NLP).
Natural Language Processing (NLP) is a field of artificial intelligence. It focuses on how computers and human language interact. Here are the main aspects:
- Understanding Language: NLP helps computers understand, interpret, and generate human language, including text and speech.
- Components of NLP:
- Tokenization: This process breaks text into smaller units, such as words or sentences.
- Part-of-Speech Tagging: This identifies the grammatical role of each word.
- Named Entity Recognition: This identifies and classifies key entities in the text, like names and locations.
- Sentiment Analysis: This determines the sentiment or emotion behind the text.
Applications: People use NLP in chatbots, translation services, sentiment analysis, and voice recognition systems.
25. How do you implement a recommendation system?
Implementing a recommendation system involves several steps. Here’s a simple overview:
- Define the Goal: Start by determining what you want to achieve. For example, you might want to recommend products, movies, or articles.
- Data Collection: Gather data about users and items. This data can include user preferences, ratings, and interactions.
- Choose a Method: You can choose between two main types of recommendation systems:
- Collaborative Filtering: This method uses user behavior and preferences to make recommendations. It can be user-based (similar users) or item-based (similar items).
- Content-Based Filtering: This method recommends items based on their features. For example, if a user liked action movies, the system recommends other action films.
- Build the Model: Use algorithms to create the recommendation model. Libraries like Surprise or TensorFlow can help with implementation.
- Evaluation: Test the model’s performance using metrics like precision, recall, and F1 score. Adjust the model as needed.
- Deployment: Once the model is ready, deploy it to your application. Ensure that it can handle real-time user interactions.
Applications: Recommendation systems find wide use in e-commerce, streaming services, and social media platforms.
Case Studies and Problem Solving
26. How would you approach building a fraud detection system?

To build a fraud detection system, I would first define the scope of the project and the specific types of fraud we want to detect, such as credit card or account fraud. Then, I would collect relevant data like transaction logs, user behavior patterns, and historical fraud cases.
Next, I would preprocess the data to clean it, handle missing values, and normalize it as needed. I’d focus on feature engineering, creating features that highlight suspicious activity, such as unusual transaction amounts or locations.
After that, I would select appropriate machine learning algorithms like logistic regression or decision trees and train my model using historical data. I would use cross-validation to ensure the model generalizes well. Finally, I would implement the system in a production environment, monitor its performance, and regularly update it with new data to adapt to evolving fraud tactics.
27. Explain how you would analyze customer churn.
To analyze customer churn, I would start by defining what churn means for the company, which typically refers to customers who stop using our service over a certain period.
Next, I would gather and analyze relevant data, such as transaction histories, customer support interactions, and demographic information. Conducting exploratory data analysis (EDA) would help me identify patterns and factors contributing to churn.
I’d then focus on feature engineering to create variables that might indicate churn risk, like the time since the last purchase or engagement levels. After developing a churn prediction model using techniques such as logistic regression, I’d evaluate its performance using metrics like precision and recall.
Finally, based on the analysis, I would provide actionable insights to improve retention strategies, targeting specific customer segments that are more likely to churn.
28. What steps would you take to improve the performance of an existing model?
To improve an existing model’s performance, I would begin by analyzing its current metrics to identify areas needing improvement. I would then check the data quality to ensure there are no missing values or anomalies that could affect the model.
Next, I would explore feature engineering options, either by creating new features or refining existing ones to enhance predictive power. I would also conduct hyperparameter tuning to find the optimal settings for the model.
If necessary, I’d consider trying different algorithms to see if a new approach yields better results. Implementing cross-validation would help ensure the model is robust and generalizes well.
Finally, I would continuously monitor the model’s performance in production and retrain it with new data to keep it updated and accurate.
29. How would you handle an imbalanced dataset?
When dealing with an imbalanced dataset, I would first assess the extent of the imbalance to understand its impact. Then, I might apply resampling techniques like oversampling the minority class using SMOTE or undersampling the majority class, depending on the situation.
I would also consider using algorithms that are robust to imbalances, such as decision trees or ensemble methods. Additionally, adjusting the class weights in the model can help emphasize the minority class during training.
For evaluating the model, I would focus on metrics that reflect performance across classes, such as precision, recall, and the F1 score, rather than accuracy alone, which can be misleading in imbalanced scenarios.
30. Describe how you would forecast sales for the next quarter.
To forecast sales for the next quarter, I would start by collecting historical sales data from previous quarters to identify trends and patterns. I’d analyze factors that may affect sales, such as seasonality, marketing campaigns, and economic conditions.
I would then choose a suitable forecasting model, such as time series analysis (like ARIMA) or regression analysis that accounts for these influencing factors. After cleaning the data and handling any anomalies, I would fit the model to the historical data.
I would use a validation set to evaluate the model’s accuracy and make adjustments as necessary. Once the model performs satisfactorily, I would use it to generate forecasts for the next quarter, ensuring to present my findings clearly to stakeholders.
Ethics and Privacy
31. What ethical considerations do you think are important in data science?
In data science, several ethical considerations are crucial. First, data privacy is paramount. We must respect individuals’ rights to control their personal information and ensure that data is collected and used responsibly.
Second, we must be aware of bias in our data and models. It’s vital to understand how biases can affect outcomes and lead to unfair treatment of certain groups. Implementing techniques to identify and mitigate bias is essential.
Finally, transparency is key. Stakeholders should understand how models work and how decisions are made based on data. Clear communication about the limitations and assumptions of our analyses fosters trust and accountability.
32. How do you ensure data privacy and security in your projects?
To ensure data privacy and security, I start by anonymizing sensitive data where possible. This means removing personally identifiable information (PII) to protect individuals’ identities.
I also implement data encryption both in transit and at rest to prevent unauthorized access. Access controls are critical; I ensure that only authorized personnel have access to sensitive data.
Regular security audits and compliance checks help identify potential vulnerabilities. Additionally, I follow relevant legal frameworks, such as GDPR or HIPAA, to ensure that all data handling practices are compliant with regulations.
33. Describe a situation where you had to deal with biased data.
In a previous project, I worked on a predictive model for loan approvals. I discovered that the historical data reflected systemic bias, favoring certain demographic groups over others.
To address this, I conducted a thorough analysis to identify the specific biases in the data. I then implemented oversampling techniques for the underrepresented groups and adjusted the model’s training process to minimize bias.
After retraining the model, I validated it using fairness metrics to ensure that the predictions were equitable across different demographic groups. This experience reinforced the importance of recognizing and addressing bias in data science.
34. What is GDPR, and why is it important for data scientists?
GDPR, or the General Data Protection Regulation, is a comprehensive data privacy regulation enacted by the European Union. It sets strict guidelines for the collection and processing of personal information of individuals within the EU.
For data scientists, GDPR is important because it imposes obligations to ensure that data is handled lawfully, transparently, and fairly. It emphasizes the need for informed consent from individuals before collecting their data and provides individuals with rights to access, rectify, and delete their data.
Non-compliance with GDPR can result in significant fines, so understanding and adhering to its principles is crucial for maintaining ethical practices and legal compliance in data science projects.
35. How do you handle sensitive data in your analysis?
When handling sensitive data, I take a cautious and methodical approach. First, I ensure that I have the necessary permissions and that I follow ethical guidelines for data usage.
I always start by anonymizing or pseudonymizing sensitive information to protect individuals’ identities. Additionally, I only use the data that is absolutely necessary for my analysis to minimize exposure.
During the analysis, I employ secure computing environments and limit access to sensitive data to authorized team members only. Finally, I ensure that any reports or visualizations do not reveal sensitive information and that any data is securely stored or deleted after the project’s completion.
Personal Insights
36. What sparked your interest in data science?
My interest in data science was sparked during my undergraduate studies in statistics. I realized the potential of data to tell compelling stories and drive impactful decisions. A pivotal moment came when I worked on a project analyzing social media trends to predict customer behavior. Seeing how data could uncover patterns and inform business strategies was fascinating and motivated me to delve deeper into the field. Since then, I’ve been captivated by the intersection of technology, statistics, and real-world applications.
37. Describe your favorite data science project and what you learned from it.
One of my favorite projects was developing a predictive model for a retail company to optimize inventory management. I worked closely with cross-functional teams to gather requirements and understand business challenges. Through this project, I learned the importance of collaborative communication. It was essential to align technical aspects with business needs to ensure our model was practical and effective. Additionally, I gained insights into the significance of feature engineering and how small adjustments could significantly impact model performance.
38. How do you balance technical skills with business acumen?
Balancing technical skills with business acumen is crucial in data science. I make a conscious effort to understand the business context behind the data I analyze. This means regularly engaging with stakeholders to grasp their goals and challenges. I also strive to enhance my business knowledge by reading industry reports and attending relevant workshops. By doing so, I can apply my technical skills more effectively, ensuring that my analyses not only provide insights but also drive meaningful business outcomes.
39. What tools or frameworks do you find indispensable in your work?
In my work, I find several tools and frameworks indispensable. For data manipulation and analysis, I rely heavily on Pandas and NumPy. When it comes to visualization, Matplotlib and Seaborn are my go-to libraries. For machine learning, I frequently use Scikit-learn for model building and evaluation. Additionally, I value Jupyter Notebooks for prototyping and sharing analyses. Each of these tools enhances my productivity and enables me to deliver high-quality results efficiently.
40. How do you approach learning new technologies or methodologies?
When learning new technologies or methodologies, I adopt a structured approach. I typically start by identifying a specific use case or project that I can apply the new knowledge to. This practical application helps reinforce my learning. I utilize a mix of resources, such as online courses, documentation, and community forums, to gain a well-rounded understanding. I also make it a point to engage with others in the field, attending meetups or discussions where I can learn from their experiences. This blend of theoretical knowledge and practical application keeps me motivated and ensures I stay updated with industry trends.
The Future of Data Science
41. What do you think will be the biggest trends in data science in the next few years?

In the coming years, I anticipate several significant trends in data science. Automated Machine Learning (AutoML) will gain traction, making it easier for non-experts to develop models without extensive coding knowledge. This democratization of data science will broaden its accessibility.
Additionally, the integration of AI and data science will become more pronounced, enabling more advanced predictive analytics and decision-making processes. The use of real-time data analytics will also rise, as organizations seek to respond quickly to changes in the market or customer behavior.
Finally, ethical considerations and data privacy will increasingly shape practices, driven by regulations like GDPR. As a result, there will be a greater emphasis on explainable AI and building trust in data-driven decisions.
42. How do you see AI impacting the field of data science?
AI is set to revolutionize data science by enhancing the capabilities of data analysts and scientists. With advancements in machine learning algorithms, AI can automate repetitive tasks, such as data cleaning and feature selection, allowing data scientists to focus on more strategic aspects of their work.
AI can also improve the accuracy of predictions and insights through advanced modeling techniques, such as deep learning. Furthermore, AI-powered tools will facilitate better data visualization and interpretation, making it easier to communicate findings to stakeholders.
Ultimately, AI will drive a shift towards more collaborative approaches in data science, where data scientists work alongside AI systems to derive insights and make informed decisions.
43. What skills do you think will be most important for future data scientists?
As the field of data science evolves, several skills will become increasingly important. Statistical knowledge and programming skills will remain foundational, with a strong emphasis on languages like Python and R for data manipulation and analysis.
Additionally, machine learning expertise will be essential, especially in understanding various algorithms and their applications. Data scientists will also need to be proficient in data engineering, as the ability to work with large datasets and data pipelines will be crucial.
Soft skills like communication and collaboration will be vital as data scientists must effectively share their findings with non-technical stakeholders. Finally, a solid understanding of ethics and data privacy will be critical as organizations navigate the complexities of data usage in a responsible manner.
44. How can data science be applied to solve global challenges?
Data science has the potential to address numerous global challenges. For example, in healthcare, data analytics can improve patient outcomes by predicting disease outbreaks, optimizing treatment plans, and personalizing healthcare services.
In climate change, data science can analyze environmental data to develop models for predicting weather patterns, assessing climate risks, and optimizing renewable energy use.
Moreover, in education, data science can help identify at-risk students and personalize learning experiences to improve educational outcomes. By harnessing the power of data, we can develop actionable insights and strategies to tackle these pressing global issues effectively.
45. Describe a potential application of data science that you find exciting.
One potential application of data science that excites me is its use in personalized medicine. By analyzing vast amounts of genetic, environmental, and lifestyle data, we can tailor medical treatments to individual patients rather than using a one-size-fits-all approach.
This application could lead to significantly improved health outcomes, as treatments would be based on a deeper understanding of each patient’s unique characteristics. Moreover, combining data science with genomics could help identify genetic markers for diseases, enabling early detection and prevention strategies.
Overall, the possibilities for personalized medicine showcase how data science can profoundly impact healthcare and improve lives.
Additional Questions
46. What is data normalization, and why is it important?
Data normalization is the process of scaling numerical data to fall within a specific range, typically between 0 and 1, or transforming it to have a mean of 0 and a standard deviation of 1. This is crucial in machine learning because features on different scales can disproportionately influence the model’s performance.
For example, if one feature ranges from 1 to 1000 while another ranges from 0 to 1, the model may give more weight to the feature with the larger scale, leading to biased results. Normalization helps improve the convergence speed of optimization algorithms and ensures that all features contribute equally to the distance calculations, which is especially important for algorithms like k-means clustering and support vector machines.
47. Explain the concept of time series analysis.
Time series analysis involves analyzing data points collected or recorded at specific time intervals. The primary goal is to identify patterns over time, such as trends, seasonal variations, and cyclic behavior.
This analysis is vital in various fields, including finance, economics, and environmental science, where understanding temporal dynamics can lead to better forecasts and decision-making. Common techniques in time series analysis include decomposition, which breaks down a time series into its components (trend, seasonality, and residuals), and ARIMA models, which are used for making predictions based on past values.
Additionally, time series forecasting can help organizations plan for future demand, manage inventory, and allocate resources efficiently.
48. How do you perform dimensionality reduction?
Dimensionality reduction is the process of reducing the number of features in a dataset while preserving as much information as possible. There are several methods to achieve this, with two of the most common being Principal Component Analysis (PCA) and t-distributed Stochastic Neighbor Embedding (t-SNE).
- PCA works by identifying the directions (principal components) that maximize variance in the data. It transforms the original features into a smaller set of uncorrelated features, making it easier to visualize and analyze the data while retaining its essential characteristics.
- t-SNE is particularly useful for visualizing high-dimensional data in two or three dimensions. It works by converting similarities between data points into probabilities and then minimizing the divergence between these probabilities in the lower-dimensional space.
The choice of method often depends on the specific problem, but dimensionality reduction can improve model performance, reduce computation time, and help avoid the curse of dimensionality.
49. What are the differences between L1 and L2 regularization?
L1 and L2 regularization are techniques used to prevent overfitting in machine learning models by adding a penalty to the loss function.
- L1 regularization, also known as Lasso regression, adds the absolute value of the coefficients as a penalty term. This can lead to sparse solutions, meaning that some feature coefficients can become zero, effectively selecting a simpler model by excluding less important features.
- L2 regularization, known as Ridge regression, adds the square of the coefficients as a penalty term. Unlike L1, L2 regularization does not lead to sparsity; instead, it shrinks the coefficients of less important features but keeps all features in the model.
In summary, L1 regularization is beneficial for feature selection, while L2 regularization is more effective at handling multicollinearity and keeping all features.
50. How do you document your data science projects?
Documenting data science projects is crucial for ensuring reproducibility and facilitating collaboration. I follow several best practices:
- Clear Project Structure: I organize the project folder with clearly defined directories for data, scripts, and documentation. This makes it easy for others to navigate.
- README Files: I create a README file at the root level that provides an overview of the project, including its objectives, data sources, and instructions for running the code.
- Code Comments: Throughout the code, I include comments that explain the logic and steps taken, which helps others understand the thought process behind the analyses.
- Version Control: I use version control systems like Git to track changes and collaborate with others, providing a history of the project’s evolution.
- Documentation Tools: I often use tools like Jupyter Notebook or R Markdown to combine code, visualizations, and narrative explanations in a single document. This makes the analysis more accessible and comprehensible.
- Final Report: At the end of the project, I prepare a comprehensive report summarizing the methodology, findings, and recommendations. This document is essential for stakeholders who may not be involved in the day-to-day work.
Overall, thorough documentation ensures that my work is transparent and can be easily understood and built upon by others in the future.
Conclusion
As we wrap up this exploration of the Top 50 Data Science Interview Questions, it’s clear that preparation is key to success in the data science field. From understanding fundamental concepts like data normalization and time series analysis to tackling advanced topics such as dimensionality reduction and regularization techniques, having a solid grasp of these questions can significantly enhance your confidence and performance in interviews.
Remember, interviews are not just about answering questions; they are also an opportunity to showcase your analytical thinking, problem-solving skills, and passion for data. By reflecting on these questions and considering how they relate to your own experiences and projects, you’ll be well-equipped to engage with potential employers meaningfully.
Whether you’re a seasoned professional or just starting your journey in data science, staying updated with the latest trends and continuously refining your skills will set you apart in this rapidly evolving field.
Thank you for joining us in this two-part series! We hope you found these insights valuable and that they inspire you to explore the exciting world of data science further. For more in-depth discussions, tips, and resources, feel free to visit our blog and stay tuned for more content that can help you succeed in your data science career.
External Resources
Coursera – Data Science Specialization by Johns Hopkins University
A comprehensive course covering data science fundamentals, including statistical analysis and machine learning.
Visit Coursera
edX – Professional Certificate in Data Science by Harvard University
This program provides a robust introduction to data science, including R programming and data analysis techniques.
Visit edX






Leave a Reply