
 in Generative Music: A New Era of Creativity")
Variational Autoencoders (VAEs) in Generative Music: A New Era of Creativity
Introduction
A world where artificial intelligence helps you compose music, blending different genres and styles to create something entirely new and unique. This isn’t a scene from a futuristic movie; it’s happening right now thanks to Variational Autoencoders (VAEs). These advanced machine learning models are transforming the way we create music, allowing us to explore uncharted territories of sound and rhythm.
VAEs can learn from existing pieces of music and then generate new compositions that maintain the style and structure of the originals. This technology is not just a tool for musicians and composers but a new partner in creativity, providing fresh ideas and pushing the boundaries of what is possible in music. Whether you are a professional musician, a hobbyist, or just someone curious about the intersection of AI and music, the world of VAEs offers a fascinating glimpse into the future of music creation.
Join us as we explore how Variational Autoencoders (VAEs), their significance in generative models, and the profound impact they have on creativity in the music industry. By the end of this article, you’ll gain a deeper understanding of how VAEs are reshaping music and inspiring a new era of creativity. Let’s begin this exciting journey!”
Overview of Variational Autoencoders (VAEs)

Variational Autoencoders (VAEs) are a type of machine learning model used for generating new data. They work by compressing the input data into a simpler, lower-dimensional representation (called the latent space), and then reconstructing the original data from this representation. This process involves two main parts: the encoder and the decoder.
- Encoder: The encoder compresses the input data into the latent space. Think of it as summarizing a long story into a few key points. For music, this means encoding the intricate patterns and structures of a piece into a compact form that captures its essence.
- Latent Space: This is where the magic happens. The latent space is a lower-dimensional representation of the input data. It allows the model to understand and manipulate the core elements of the music. Imagine a musical piece reduced to its fundamental components, making it easier to explore and modify.
- Decoder: The decoder takes the compressed representation from the latent space and reconstructs it back into the original format. In music, this means transforming the latent representation back into a full musical piece that sounds like it was composed by a human.
For example, if you feed a VAE several jazz pieces, it will learn the characteristics of jazz music. Later, it can generate new jazz compositions that sound like they were created by a human jazz musician.
Importance of Variational Autoencoders (VAEs) in Generative Models
VAEs are crucial in the field of generative models for several reasons:

- Learning Complex Patterns: VAEs can learn complex patterns and structures from high-dimensional data like music. This capability allows them to generate new compositions that are rich and coherent. For instance, a VAE trained on classical music can produce new classical pieces that maintain the intricate structures and harmonies typical of the genre.
- Creativity: VAEs can blend elements from different pieces of music to create unique compositions. This ability to mix and match can lead to innovative musical creations that push the boundaries of traditional music. Imagine a Variational Autoencoders (VAEs) blending elements of jazz and classical music to create a novel fusion genre.
- Style Consistency: One of the strengths of Variational Autoencoders (VAEs) is their ability to generate music that maintains the style and structure of the input data. For example, if a VAE is trained on a dataset of pop songs, it can generate new pop songs that follow the same stylistic patterns, making it a valuable tool for composers who want to explore new ideas within a specific genre.
- Exploration and Innovation: The latent space in VAEs provides a rich environment for exploring new musical ideas. By manipulating points in the latent space, musicians can experiment with different styles and structures. For instance, moving a point in the latent space slightly can change a melody or rhythm, allowing for endless experimentation and innovation.
The Impact of Generative Music on Creativity
The rise of generative music using Variational Autoencoders (VAEs) has greatly influenced creativity in the music industry. Let’s explore how this technology is shaping the future of music creation.

New Tools for Musicians
VAEs provide musicians with new tools to create and explore music. These tools can inspire fresh ideas, helping artists overcome creative blocks and discover new directions for their work. For example, if a composer is struggling to finish a piece, they might use a Variational Autoencoders (VAEs) to generate variations. This can spark new ideas and possibilities, allowing them to complete their composition with renewed creativity.
Innovative Compositions
By blending elements from different styles and genres, VAEs help musicians create innovative compositions that push the boundaries of traditional music. For instance, a VAE trained on both electronic and acoustic music could generate hybrid compositions. These compositions combine the best features of both worlds, leading to unique and exciting musical creations.
Personalized Music
Variational Autoencoders (VAEs) can generate personalized music based on individual preferences, creating a tailored listening experience. By analyzing a user’s listening history, a VAE can be trained to generate music that aligns with their tastes. This results in personalized playlists that feel more attuned to the listener’s preferences, enhancing their overall music experience.
Collaborative Creativity
VAEs can be used in collaborative settings, where musicians and AI systems work together to create new music. This collaboration can lead to unexpected and exciting musical outcomes. For example, a musician might use a VAE to generate a base melody and then build upon it, creating a unique blend of human and AI creativity.
Accessibility
Generative music technologies like Variational Autoencoders (VAEs) make music creation more accessible to people without traditional musical training. With these tools, anyone can explore and create music, democratizing the creative process. For example, a novice could use a VAE to generate a piece of music and then tweak it to their liking, making the music creation process more inclusive.
Understanding Variational Autoencoders (VAEs)
Variational Autoencoders (VAEs) are fascinating and powerful tools in the world of machine learning and AI. To appreciate their significance and how they are transforming areas like generative music, it’s important to understand what they are, the key concepts behind them, and how they differ from traditional autoencoders.

What are Variational Autoencoders?
Variational Autoencoders (VAEs) are a type of generative model that can learn to create new data similar to the data it was trained on. They achieve this by finding a simpler, underlying structure in the data and using that structure to generate new instances. Think of VAEs as artists who study existing works and then create new art pieces in the same style.
Definition and Key Concepts
To understand VAEs, let’s break down some of their essential components:
- Encoder: This part of the VAE takes the input data and compresses it into a smaller, simpler form called the latent space. Imagine trying to summarize a complex book into a short summary that still captures the main points.
- Latent Space: This is a lower-dimensional representation of the input data. It’s like a map that shows the essential features of the data, making it easier to navigate and explore different possibilities.
- Decoder: The decoder takes the compressed representation from the latent space and reconstructs it back into the original format. Think of it as expanding your summary back into a detailed story that closely resembles the original book.
- Reparameterization Trick: This is a clever technique used in VAEs to make them work effectively. It allows the model to learn meaningful patterns by adding a bit of randomness to the latent space, which helps in generating new and diverse data.
For example, if you train a VAE on a dataset of handwritten digits, it will learn to capture the essential features of each digit. Later, it can generate new digits that look like they were written by humans, even though they are entirely new.
Must Read
- Why sorted() Is Safer Than list.sort() in Production Python Systems
- Monotonic Sequence in Python: 7 Practical Methods With Edge Cases, Interview Tips, and Performance Analysis
- How to Check if Dictionary Values Are Sorted in Python
- Check If a Tuple Is Sorted in Python — 5 Methods Explained
- How to Check If a List Is Sorted in Python (Without Using sort()) – 5 Efficient Methods
Differences Between VAEs and Traditional Autoencoders

While both VAEs and traditional autoencoders aim to learn a compressed representation of the data, they differ in a few important ways:
- Generation Capability: Traditional autoencoders are primarily used for tasks like data compression and noise reduction. They learn to encode and decode data but don’t focus on generating new data. In contrast, VAEs are designed to generate new, similar data by sampling from the latent space.
- Latent Space Structure: In traditional autoencoders, the latent space is often unstructured, making it difficult to generate meaningful new data. VAEs, on the other hand, impose a structure on the latent space, often assuming it follows a normal distribution. This structured latent space makes it easier to explore and generate new data points.
- Reparameterization: Traditional autoencoders do not use the reparameterization trick. This trick is unique to VAEs and is crucial for their ability to generate new data. It adds randomness to the latent space, allowing the model to produce diverse and novel outputs.
For instance, if you use a traditional autoencoder to compress and reconstruct an image of a cat, it will do so accurately. However, it won’t be able to generate new images of cats. A VAE, after training on many cat images, can generate new images of cats that it has never seen before, capturing the essence of what makes a cat look like a cat.
Understanding these differences helps us appreciate why Variational Autoencoders (VAEs) are so powerful for generative tasks, like creating new music. They don’t just learn to copy; they learn to create, opening up new avenues for innovation and creativity in fields ranging from art to science.
How Variational Autoencoders (VAEs) Work
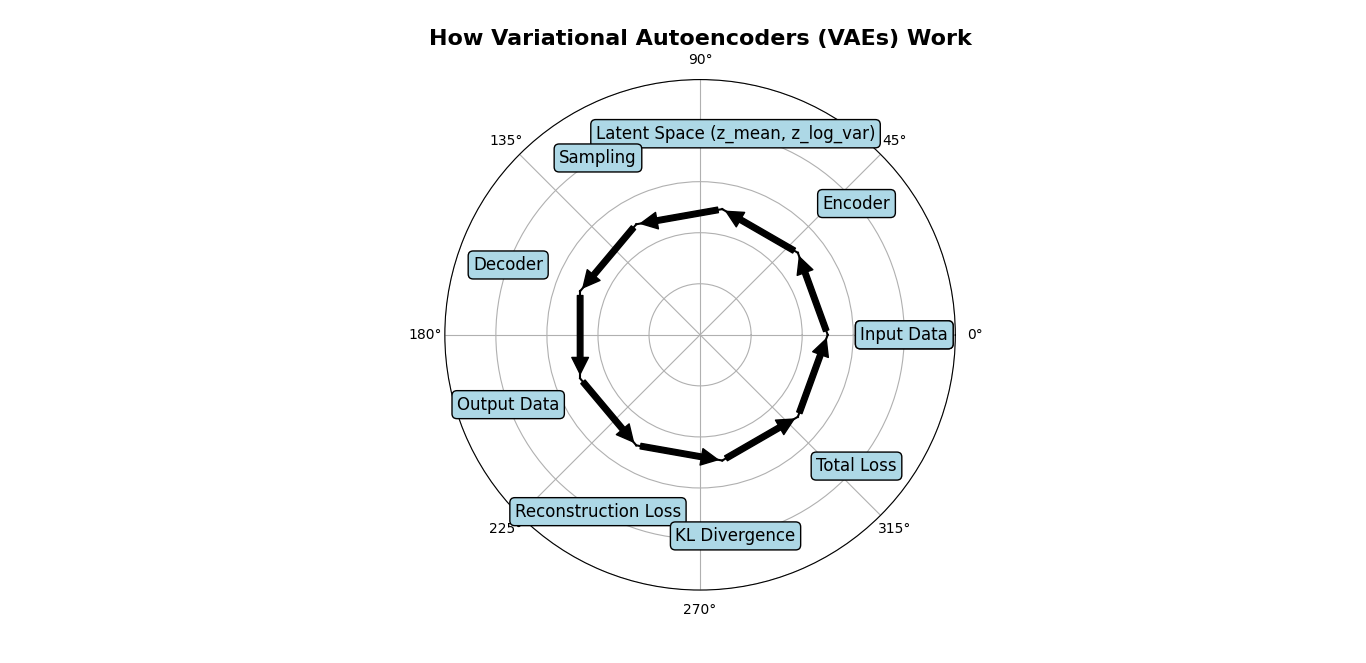
Variational Autoencoders (VAEs) are complex models that consist of two main components: an encoder and a decoder. Together, they enable the transformation of input data into a lower-dimensional representation and then back into a higher-dimensional space, creating new and unique data in the process. Here’s a detailed explanation of each component and how they work together.
Encoder and Decoder Architecture
Encoder
The encoder is responsible for compressing the input data into a more compact form. In the context of generating artwork, let’s say we have a digital image of a painting.
- Input Data: The painting is represented as a high-dimensional array of pixel values, capturing various features like colors, shapes, and textures.
- Neural Network Layers: The encoder consists of multiple layers of neural networks. Each layer performs operations that reduce the complexity of the data. For example:
- First Layer: Extracts basic features like edges and simple shapes.
- Middle Layers: Capture more complex features like color patterns and textures.
- Final Layer: Compresses these features into a much smaller, dense representation known as the latent vector.
- Latent Vector: The output of the encoder is this latent vector, which is a compressed version of the original painting. It contains the essential characteristics needed to represent the painting but in a much smaller, more manageable form.
Decoder
The decoder takes the latent vector from the encoder and reconstructs it back into a high-dimensional form, resembling the original painting.
- Input from Latent Space: The decoder receives the latent vector as input.
- Neural Network Layers: Like the encoder, the decoder also consists of multiple layers of neural networks, but they perform the reverse operations:
- First Layer: Expands the latent vector, adding more details and complexity.
- Middle Layers: Gradually build up the detailed features, adding colors, shapes, and textures.
- Final Layer: Outputs a high-dimensional array that closely resembles the original painting.
- Output Data: The output is a new painting that captures the essence of the original input but can include variations and new elements, making it unique.
Latent Space Representation
The latent space is a crucial part of the Variational Autoencoders (VAEs) Work, acting as the intermediary representation of the input data. It has several important features:
- Dimensionality Reduction: The latent space simplifies the complex, high-dimensional input data into a lower-dimensional form. This reduction makes it easier to work with and manipulate the data. For instance, a high-resolution image of a painting might be reduced to a vector of much smaller size.
- Feature Mapping: Each point in the latent space represents a unique combination of features. For example, in the context of artwork, one point might correspond to a specific style, like impressionism, while another might represent abstract art. By exploring different points in the latent space, the VAE can generate a wide variety of artwork.
- Exploration and Generation: The latent space allows for the exploration of new possibilities. By moving through the latent space, we can generate new artworks that blend different styles and elements. For example, moving from a point representing a classical painting to a point representing a modern abstract piece can result in a hybrid artwork that combines elements of both styles.
Loss Function and Regularization
To train a VAE effectively, it’s essential to use a suitable loss function and apply regularization techniques. These help the model learn meaningful patterns from the input data and generate high-quality output.
Loss Function
The loss function measures how well the Variational Autoencoders (VAEs) Work reconstructs the input data and ensures that the latent space representation is useful. It typically consists of two parts:
- Reconstruction Loss: This part of the loss function measures the difference between the original painting and the reconstructed output from the decoder. The goal is to minimize this difference, ensuring that the output artwork closely resembles the input. For example, if the input painting has vibrant colors and sharp edges, the reconstruction loss will penalize the model if the output painting is dull or blurry.
- Regularization Loss: This part encourages the latent space to follow a specific distribution, usually a normal distribution. By doing this, the Variational Autoencoders (VAEs) Work can generate more diverse and realistic new artwork pieces. The regularization loss penalizes the model if the latent vectors deviate too much from the desired distribution. This helps the model learn a smooth and continuous latent space, enabling it to generate new and varied artworks by sampling from this space.
Regularization
Regularization techniques help improve the VAE’s ability to generalize and create varied outputs:
- Reparameterization Trick: This technique introduces a bit of randomness to the latent vectors, making the model more robust and capable of generating diverse artwork pieces. By adding controlled noise, the VAE can explore different artistic variations. For instance, slight variations in the latent vector can lead to different styles or elements in the generated artwork.
- Kullback-Leibler (KL) Divergence: This measure is used in the regularization loss to ensure that the latent vectors follow a normal distribution. It helps the VAE balance the trade-off between accurately reconstructing the input artwork and maintaining a useful latent space representation. By penalizing deviations from the normal distribution, the model learns to create a more structured and meaningful latent space, leading to better generation of new artwork.
Example: Artwork Generation with Variational Autoencoders (VAEs) Work
Imagine training a VAE on a dataset of various art styles, such as abstract, realism, and impressionism:
- Encoder: Compresses each artwork piece into a latent vector, capturing key features like color patterns, shapes, and textures. For example, an abstract painting might be compressed into a latent vector that captures its bold colors and geometric shapes.
- Latent Space: Represents these features in a simplified form, allowing exploration of different artistic styles and combinations. By navigating the latent space, we can find new points that blend different styles, creating hybrid artworks.
- Decoder: Reconstructs the artwork from the latent vectors, generating new compositions that blend elements from different genres. For example, a point in the latent space might produce a new artwork that combines the detailed textures of realism with the vibrant colors of impressionism.
- Loss Function and Regularization: Ensure the Variational Autoencoders (VAEs) Work learns meaningful patterns and generates diverse, high-quality artwork. By minimizing the reconstruction loss and applying regularization, the model learns to generate new and unique artworks that maintain the essence of the original styles.
Variational Autoencoders (VAEs) work by compressing input data into a latent space using an encoder, then reconstructing it using a decoder. The latent space allows for efficient representation and exploration of artistic features, while the loss function and regularization techniques ensure the model learns effectively and generates diverse outputs. This process enables the creation of innovative and varied artwork compositions, pushing the boundaries of creativity in the art world.
The Role of Variational Autoencoders (VAEs) Work in Generative Music
Variational Autoencoders (VAEs) are reshaping the landscape of music creation by using their ability to learn and generate musical compositions from existing data. Here’s how VAEs impact generative music:
- Pattern Learning: VAEs analyze large datasets of musical pieces to identify patterns and structures within the music. They learn how different musical elements, such as melody, harmony, and rhythm, interact and combine.
- Music Creation: Once trained, Variational Autoencoders (VAEs) Work can use this learned knowledge to generate new music that maintains the stylistic and structural characteristics of the original compositions but with new and unique variations. This allows for the creation of music that can blend different genres and styles, producing innovative and original compositions.
For example, a VAE trained on a dataset of jazz and classical music can generate a new piece that fuses elements of both genres. This results in a novel composition that combines the complex harmonies of classical music with the improvisational aspects of jazz.
How VAEs are Applied to Music Generation

Encoding Musical Data
Encoding is the first step in the process, where musical data is converted into a format that a VAE can work with.
- Input Data: The primary data format used is MIDI (Musical Instrument Digital Interface) files. MIDI files contain detailed information about musical notes, including:
- Pitch: The frequency of the notes (e.g., C4, D#5).Duration: How long each note is played (e.g., quarter note, eighth note).Velocity: The intensity of the note (e.g., how hard or soft it is played).
- Encoder: The encoder takes these MIDI files and compresses them into a lower-dimensional form known as the latent space. This process involves:
- Feature Extraction: The encoder analyzes the MIDI files to identify and extract key musical features such as melody lines, chord progressions, and rhythmic patterns.
- Dimensionality Reduction: The encoder then maps these features into a more compact representation. This compressed form retains the essential characteristics of the music while reducing the complexity of the data.
Generating New Music Samples
Once the musical data has been encoded, the VAE can generate new music by decoding the latent vectors.
- Latent Space: The latent space is a multi-dimensional vector space where each dimension represents a specific musical characteristic. This space serves as a map for exploring various musical possibilities:
- Exploration: Different regions of the latent space correspond to different musical styles or elements. By navigating this space, the Variational Autoencoders (VAEs) Work can discover new combinations and variations of musical features.
- Representation: Each point in the latent space represents a potential new composition, combining different aspects of the music it has learned.
- Decoder: The decoder takes the compressed latent vectors and reconstructs them back into musical formats:
- Reconstruction: The decoder interprets the latent vectors to generate new MIDI files that reflect the features captured by the encoder.
- Innovation: While generating new music, the decoder can introduce variations and combinations that were not present in the original dataset, creating fresh and original pieces.
Advantages of Using Variational Autoencoders (VAEs) Work for Music Generation
Variational Autoencoders (VAEs) offer a range of benefits when it comes to generating music. Here’s a closer look at how they enhance creativity, innovation, and personalization in music:

Creativity and Innovation in Music
VAEs are powerful tools for boosting creativity and bringing innovation to music composition. They achieve this by blending various musical elements in novel ways.
- Innovative Compositions: Variational Autoencoders (VAEs) Work can merge elements from diverse musical styles, such as classical, jazz, and electronic, to create new and unique compositions. For instance:
- Classical and Jazz Fusion: A VAE trained on classical piano pieces and jazz improvisations can generate a hybrid composition. This piece might feature the intricate melodies of classical music with the rhythmic and improvisational aspects of jazz. Such a combination introduces fresh musical experiences that are not typically found in traditional compositions.
- Electronic Music Elements: By incorporating electronic sounds with acoustic instruments, VAEs can produce music that blends synthetic textures with organic sounds. This can lead to the creation of innovative tracks that push the boundaries of traditional music genres.
- New Ideas: Musicians often face creative blocks where generating new ideas becomes challenging. Variational Autoencoders (VAEs) Work can help overcome these obstacles by providing variations of existing compositions. For example:
- Generating Variations: If a composer is working on a piece but is stuck in a repetitive pattern, they can use a VAE to generate variations of their work. The Variational Autoencoders (VAEs) Work can introduce subtle changes in melody, harmony, or rhythm, providing the composer with new directions to explore.
- Exploring New Territories: By generating novel musical elements, VAEs encourage musicians to explore new musical territories that they might not have considered before. This can lead to innovative compositions that break away from traditional patterns and offer unique listening experiences.
Example: A composer who specializes in classical music might use a VAE to generate variations that incorporate elements of electronic music. The result could be a piece that combines classical instrumentation with electronic beats, creating a fresh and unique sound.
Customization and Personalization of Music
VAEs also excel in creating music that is customized to individual preferences, enhancing the overall listening experience.
- Personalized Playlists: VAEs can analyze a user’s listening history to generate music that matches their tastes. Here’s how it works:
- Analyzing Listening History: A Variational Autoencoders (VAEs) Work can process data from a user’s previous listening habits, such as preferred genres, artists, and styles. It learns the characteristics of the music the user enjoys.Generating Music: Based on this analysis, the VAE can create music that aligns with the user’s preferences. For example, if a user frequently listens to upbeat pop music with electronic elements, the VAE can generate new tracks with similar characteristics.
- Customized Compositions: Musicians can use VAEs to create compositions that cater to specific audiences or purposes. This customization can enhance the impact of the music by aligning it with the audience’s preferences or the intended use.
- Audience-Specific Music: For instance, a musician might use a VAE to generate music for a specific event or audience. If they are composing music for a children’s film, the VAE can produce cheerful and engaging tunes suitable for young listeners.Purpose-Driven Music: VAEs can also create music customized for particular contexts, such as background music for videos, ambient sounds for relaxation apps, or motivational tracks for fitness programs.
Key Components of VAEs in Generative Music

Data Preparation for Variational Autoencoders (VAEs)
Proper data preparation is foundational for training effective VAEs. It involves several critical steps:
- Collecting and Processing Musical Data
- Collecting Data: Gather a diverse set of musical pieces, typically in a structured format like MIDI. MIDI files are advantageous because they provide detailed information about each musical note, such as pitch, duration, and intensity, which is crucial for a Variational Autoencoders (VAEs) to understand and generate music accurately.
- Processing Data: Ensure the collected data is clean and consistent. This involves:
- Normalizing Data: Adjust the musical data so that it fits within a standard range or format. For instance, ensure that all MIDI files use the same scale or tempo, which helps in creating a uniform dataset.
- Correcting Errors: Fix any inconsistencies or errors in the files, such as missing notes or incorrect timing information. This ensures that the data fed into the VAE is accurate and reliable.
- Standardizing Format: Convert all files to a common format if they come from different sources. This might involve aligning the MIDI data to a standard set of instrument sounds or note values.
Example: If you have MIDI files from classical symphonies and modern electronic tracks, you need to ensure all files are in the same format and follow the same note conventions before training the VAE.
- Feature Extraction from Music
- Identifying Key Elements: Extract significant features such as melody (the main tune), harmony (chords), rhythm (timing of notes), and dynamics (loudness). This is done using techniques like:
- Spectral Analysis: To analyze the frequency components of the music.
- Time-Frequency Representations: To capture how musical features change over time.
- Ensuring Effectiveness: This extraction helps the VAE focus on these crucial elements, which are necessary for accurate music generation. It allows the VAE to understand the core aspects of different musical genres and styles.
- Identifying Key Elements: Extract significant features such as melody (the main tune), harmony (chords), rhythm (timing of notes), and dynamics (loudness). This is done using techniques like:
Example: For a dataset containing jazz and classical music, feature extraction will involve identifying jazz’s improvisational elements and classical’s structured chord progressions. This allows the VAE to generate music that blends these features creatively.
Designing the Variational Autoencoders (VAEs) Architecture for Music
An effective VAE architecture is essential for generating high-quality music. Key aspects include:
- Choosing the Right Network Layers
- Encoder Design: The encoder’s job is to compress the input data into a latent space. For music, this often involves using layers like:
- Recurrent Neural Networks (RNNs): Useful for handling sequential data, as they can capture the temporal dependencies and patterns in music.
- Convolutional Layers: Sometimes used for extracting local features from the music data.
- Decoder Design: The decoder reconstructs the musical data from the latent space. This might involve:
- RNNs or LSTMs (Long Short-Term Memory): To regenerate sequences of notes while maintaining the structure and rhythm.
- Fully Connected Layers: To combine features and output a complete musical piece.
- Encoder Design: The encoder’s job is to compress the input data into a latent space. For music, this often involves using layers like:
Example: An RNN-based encoder might process a sequence of notes from a classical composition and convert it into a latent vector. The decoder would then take this vector and reconstruct it into a new piece, maintaining classical elements but adding new variations.
- Setting Up the Latent Space
- Dimensionality: The latent space needs to capture the essential characteristics of the music without being overly complex. This involves:
- Selecting Dimensionality: Choose a dimensionality that balances between capturing detailed features and keeping the representation manageable. Too many dimensions may lead to overfitting, while too few may not capture sufficient detail.
- Representation: Ensure that the latent space can effectively represent diverse musical features, allowing the VAE to explore and generate varied musical outputs.
- Dimensionality: The latent space needs to capture the essential characteristics of the music without being overly complex. This involves:
Example: If the latent space is too small, it may not capture the nuances of different music styles. Conversely, a very large latent space might become unwieldy and less effective. Proper dimensionality helps in generating high-quality music samples.
Training the Variational Autoencoders (VAEs) Model
Training a VAE involves fine-tuning various parameters to ensure the model learns effectively:
- Selecting Appropriate Hyperparameters
- Learning Rate: This determines how quickly the model updates its weights during training. A learning rate that is too high might cause the model to converge too quickly and miss optimal solutions, while a rate that is too low might result in slow convergence.
- Batch Size: The number of samples processed before updating the model. Larger batch sizes can lead to more stable training but require more memory, while smaller batches may lead to noisier updates but faster training.
Example: For a VAE generating music, you might start with a learning rate of 0.001 and a batch size of 64, and adjust these parameters based on the training performance.
- Monitoring Training Progress
- Reconstruction Loss: Track how well the Variational Autoencoders (VAEs) reconstructs the original data from the latent space. The reconstruction loss should decrease over time, indicating that the model is learning to accurately encode and decode the music.
- Latent Space Distribution: Ensure the latent space captures meaningful variations. Visualization tools can help check if different regions of the latent space correspond to different musical features or styles.
Example: During training, you might visualize the latent space to see if it groups similar musical styles together. This helps ensure that the VAE is learning to represent music effectively and generate coherent samples.
Real-Time Project: Generative Music with Variational Autoencoders (VAEs)
Project Overview
In this project, we aim to build a Variational Autoencoder (VAE) that can generate new musical compositions. The VAE will be trained on a dataset of existing musical pieces to learn their underlying patterns. Once trained, the VAE will generate new music samples that are creative and reflect the characteristics of the input data.
Objective: To create a VAE model that can learn from existing musical compositions and produce new, unique pieces of music.
Goals:
- Build an Encoder and Decoder Network: Develop neural network architectures to encode musical data into a latent space and decode it back into musical form.
- Train the VAE: Use the dataset to train the VAE, optimizing it to accurately reconstruct music and generate new samples.
- Generate New Music Samples: Use the trained VAE to create new musical compositions based on the learned patterns.
Tools and Libraries Required
To complete this project, you’ll need several tools and libraries:
Python Libraries:
numpy: A fundamental library for numerical operations in Python. It provides support for arrays and matrices, and mathematical functions to operate on these data structures.tensorflow: An open-source deep learning framework developed by Google. TensorFlow provides the tools needed to build and train neural network models.matplotlib: A plotting library for creating visualizations of data. It helps in visualizing the training progress and the generated music samples.
Deep Learning Framework:
- TensorFlow with Keras: Keras is a high-level API for building and training deep learning models in TensorFlow. It simplifies the process of creating and training neural networks.
Setting Up the Environment
To get started with the project, you need to set up your environment by installing the necessary libraries. This can be done using Python’s package manager, pip. Follow these steps:
- Open a Terminal or Command Prompt: Access your command line interface where you can run pip commands.
- Install the Required Libraries:You can install the required libraries using the following commands:
pip install numpy tensorflow matplotlib
This command will download and install numpy, tensorflow, and matplotlib from the Python Package Index (PyPI).
numpywill be installed to handle numerical operations and data manipulation.tensorflowwill be installed to build and train the VAE model.matplotlibwill be installed to visualize the results and progress.
Preparing the Dataset
In the process of building a Variational Autoencoder (VAE) for music generation, preparing your dataset is a critical step. This involves importing necessary libraries, loading your data, and preprocessing it to make it suitable for the VAE model. Below is a detailed explanation of the code provided for data preparation.
Code for Data Preparation
# Import necessary libraries
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, Lambda, LSTM, RepeatVector, TimeDistributed
from tensorflow.keras.models import Model
from tensorflow.keras.losses import mse
import matplotlib.pyplot as plt
# Load and preprocess dataset
# Assume X_train and X_test are preprocessed musical data
Explanation of the Code:
Import Necessary Libraries:
import numpy as np
import tensorflow as tf
from tensorflow.keras.layers import Input, Dense, Lambda, LSTM, RepeatVector, TimeDistributed
from tensorflow.keras.models import Model
from tensorflow.keras.losses import mse
import matplotlib.pyplot as plt
numpy: This library is used for numerical operations in Python. It helps in handling arrays and matrices, which is essential for data manipulation and mathematical operations.tensorflow: TensorFlow is a deep learning framework that provides tools to build and train machine learning models. It is used here for its Keras API to create the VAE model.tensorflow.keras.layers: These are the building blocks for creating neural network layers. In this project, you’ll use:Input: Defines the input layer for the model.Dense: Creates fully connected layers.Lambda: Allows custom operations, such as sampling from the latent space.LSTM: Long Short-Term Memory units, useful for sequential data like music.RepeatVector: Repeats the input data to match the sequence length.TimeDistributed: Applies a layer to each time step of the sequence.
tensorflow.keras.models: Contains theModelclass, which is used to define and manage the VAE architecture.tensorflow.keras.losses: Provides loss functions like Mean Squared Error (MSE) to evaluate the model’s performance.matplotlib.pyplot: A plotting library used to visualize the results and training progress.
Load and Preprocess Dataset:
# Load and preprocess dataset
# Assume X_train and X_test are preprocessed musical data
This section of the code is a placeholder for where you would load and preprocess your musical dataset. Here’s a detailed breakdown of what happens in this step:
- Load Data: You need to load your dataset of musical compositions. Depending on your source, this could involve reading MIDI files, audio recordings, or symbolic representations of music.
- Preprocess Data:
- Normalization: Scale the musical features to a range suitable for the VAE model. This helps the model to learn effectively and speeds up convergence during training.
- Encoding: Convert musical features into a format that can be fed into the model. This may involve representing notes, rhythms, and other musical elements as numerical values.
- Splitting Data: Divide the dataset into training and testing sets.
X_trainwill be used to train the VAE model, whileX_testwill be used to evaluate its performance.
Building the VAE Model
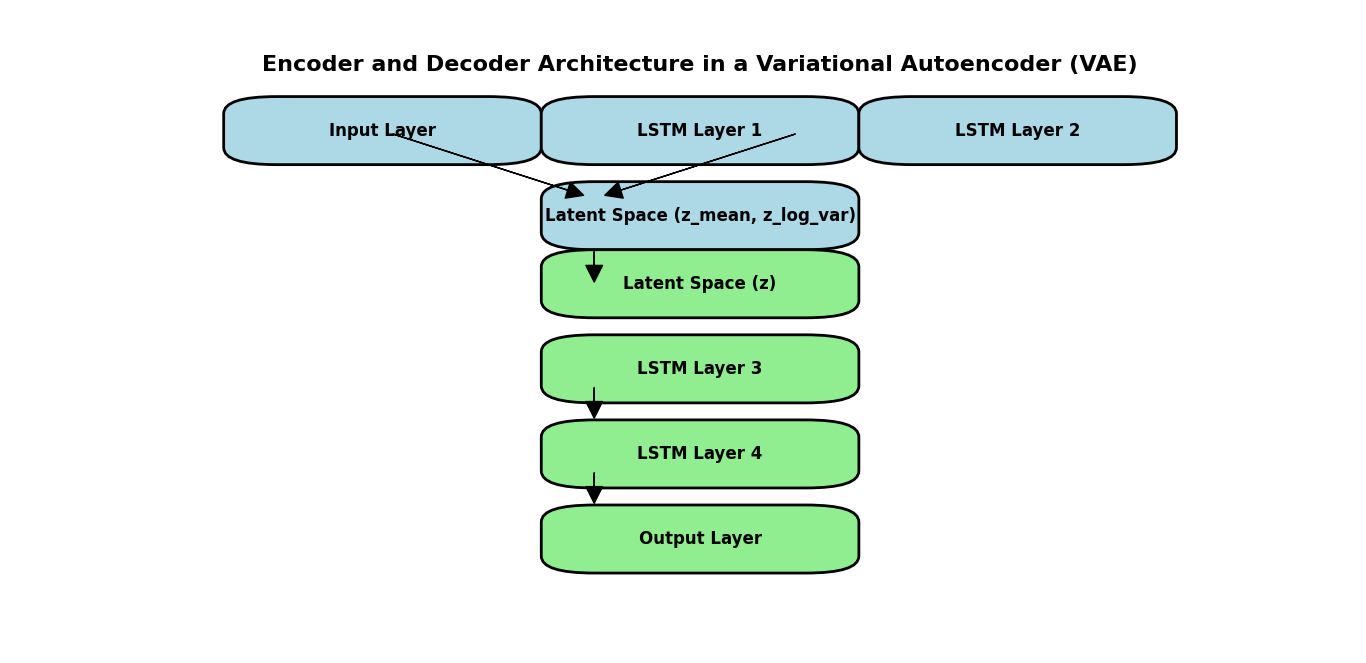
Encoder Network
The encoder network in a Variational Autoencoder (VAE) is responsible for compressing the input data into a lower-dimensional latent space representation. This section explains the code for constructing the encoder network, which is crucial for learning meaningful patterns from the musical data.
Code for Encoder Network:
# Define the encoder architecture
timesteps = 100 # Length of sequences
input_dim = 88 # Number of features
inputs = Input(shape=(timesteps, input_dim))
lstm_1 = LSTM(64, activation='relu', return_sequences=True)(inputs)
lstm_2 = LSTM(32, activation='relu', return_sequences=False)(lstm_1)
z_mean = Dense(16)(lstm_2)
z_log_var = Dense(16)(lstm_2)
# Sampling function
def sampling(args):
z_mean, z_log_var = args
epsilon = tf.keras.backend.random_normal(shape=(tf.keras.backend.shape(z_mean)[0], 16))
return z_mean + tf.keras.backend.exp(z_log_var) * epsilon
z = Lambda(sampling, output_shape=(16,))([z_mean, z_log_var])
encoder = Model(inputs, [z_mean, z_log_var, z], name='encoder')
encoder.summary()
Explanation:
1. Input Layer:
inputs = Input(shape=(timesteps, input_dim))
Input(shape=(timesteps, input_dim)): Defines the input layer of the encoder. It accepts sequences of musical data where:timesteps = 100: Represents the length of each sequence. For example, this might correspond to 100 time steps in a musical sequence.input_dim = 88: Represents the number of features in each time step. This could correspond to 88 possible pitch values in a MIDI file, representing all the keys on a piano.
2. LSTM Layers:
lstm_1 = LSTM(64, activation='relu', return_sequences=True)(inputs)
lstm_2 = LSTM(32, activation='relu', return_sequences=False)(lstm_1)
LSTM(64, activation='relu', return_sequences=True): An LSTM (Long Short-Term Memory) layer with 64 units. LSTM layers are used to capture sequential patterns in the data. Thereturn_sequences=Trueparameter ensures that the LSTM layer returns the full sequence of outputs for each time step, which is essential for learning sequential dependencies.LSTM(32, activation='relu', return_sequences=False): Another LSTM layer with 32 units. This layer processes the sequence output from the previous LSTM layer. Thereturn_sequences=Falseparameter means that only the output from the final time step is returned, which is suitable for producing a single vector representation of the entire sequence.
3. Dense Layers:
z_mean = Dense(16)(lstm_2)
z_log_var = Dense(16)(lstm_2)
Dense(16): These layers produce two outputs,z_meanandz_log_var, which are used to parameterize the latent space. Both layers have 16 units, indicating that the latent space will have a dimensionality of 16.z_mean: Represents the mean of the latent space distribution.z_log_var: Represents the logarithm of the variance of the latent space distribution. The use of logarithm ensures numerical stability and is a common practice in VAEs.
4. Sampling Function:
def sampling(args):
z_mean, z_log_var = args
epsilon = tf.keras.backend.random_normal(shape=(tf.keras.backend.shape(z_mean)[0], 16))
return z_mean + tf.keras.backend.exp(z_log_var) * epsilon
sampling(args): A custom function to sample from the latent space. It takesz_meanandz_log_varas inputs:epsilon: A random normal tensor used to introduce stochasticity into the sampling process. It is generated with the same shape asz_mean.z_mean + tf.keras.backend.exp(z_log_var) * epsilon: Uses the mean and variance to sample from the latent space distribution. This introduces randomness into the latent space representation, which is essential for generating diverse outputs.
5. Lambda Layer:
z = Lambda(sampling, output_shape=(16,))([z_mean, z_log_var])
Lambda(sampling, output_shape=(16,)): A Lambda layer is used to apply the custom sampling function. It transformsz_meanandz_log_varintoz, which is the latent space representation with a dimensionality of 16.
6. Define the Encoder Model:
encoder = Model(inputs, [z_mean, z_log_var, z], name='encoder')
encoder.summary()
Model(inputs, [z_mean, z_log_var, z]): Defines the encoder model that maps input sequences to the latent space. It outputsz_mean,z_log_var, andz, which will be used for the VAE’s loss function and for generating new music.encoder.summary(): Displays a summary of the encoder model, showing the architecture, layer types, output shapes, and the number of parameters. This helps in verifying the model’s structure and ensuring that it is correctly implemented.
Decoder Network
The decoder network in a Variational Autoencoder (VAE) reconstructs the original input data from its latent space representation. This network takes the compressed latent vector and transforms it back into a sequence of musical data. Below is a detailed explanation of the code used to build the decoder network.
Code for Decoder Network:
# Define the decoder architecture
latent_inputs = Input(shape=(16,))
repeated = RepeatVector(timesteps)(latent_inputs)
lstm_3 = LSTM(32, activation='relu', return_sequences=True)(repeated)
lstm_4 = LSTM(64, activation='relu', return_sequences=True)(lstm_3)
outputs = TimeDistributed(Dense(input_dim, activation='sigmoid'))(lstm_4)
decoder = Model(latent_inputs, outputs, name='decoder')
decoder.summary()
Explanation of the Code:
1. Input Layer:
latent_inputs = Input(shape=(16,))
Input(shape=(16,)): Defines the input layer for the decoder. It takes vectors of size 16, which corresponds to the dimensionality of the latent space produced by the encoder. Each vector represents a compressed form of the original musical sequence.
2. RepeatVector:
repeated = RepeatVector(timesteps)(latent_inputs)
RepeatVector(timesteps): Repeats the latent vectortimestepstimes. This creates a sequence where each time step is identical to the latent vector. The number of repetitions (timesteps) matches the length of the original sequences. This step is necessary because LSTM layers expect sequential data.
3. LSTM Layers:
lstm_3 = LSTM(32, activation='relu', return_sequences=True)(repeated)
lstm_4 = LSTM(64, activation='relu', return_sequences=True)(lstm_3)
LSTM(32, activation='relu', return_sequences=True): An LSTM layer with 32 units that processes the repeated latent vectors. Thereturn_sequences=Trueparameter ensures that the LSTM layer outputs a sequence of the same length as its input, capturing temporal dependencies in the data.LSTM(64, activation='relu', return_sequences=True): Another LSTM layer with 64 units. This layer further processes the sequence output from the previous LSTM layer. By usingreturn_sequences=True, it maintains the sequence structure while refining the data representation.
4. TimeDistributed Layer:
outputs = TimeDistributed(Dense(input_dim, activation='sigmoid'))(lstm_4)
TimeDistributed(Dense(input_dim, activation='sigmoid')): A TimeDistributed layer applies a Dense layer to each time step of the sequence output from the LSTM layers.Dense(input_dim, activation='sigmoid'): A fully connected Dense layer withinput_dimunits, whereinput_dimis the number of features in the original data (e.g., 88 for MIDI notes). Thesigmoidactivation function ensures that the output values are between 0 and 1, which is suitable for reconstructing the input data in the range of normalized features.
Define the Decoder Model:
decoder = Model(latent_inputs, outputs, name='decoder')
decoder.summary()
Model(latent_inputs, outputs): Defines the decoder model that maps the latent vector input back to the reconstructed sequence. This model takes the latent vector and outputs a sequence of reconstructed musical data.decoder.summary(): Displays a summary of the decoder model, showing the architecture, layer types, output shapes, and the number of parameters. This helps verify the structure and ensure that the decoder is correctly implemented.
VAE Loss Function
The loss function for a Variational Autoencoder (VAE) combines two crucial components: reconstruction loss and KL divergence. These components guide the VAE to both accurately reconstruct the input data and learn a useful latent space representation. Below is a detailed explanation of the code used to define and compute the VAE loss function.
Code for Loss Function:
# Define the VAE model
outputs = decoder(encoder(inputs)[2])
vae = Model(inputs, outputs, name='vae_mlp')
# VAE loss = reconstruction loss + KL divergence
reconstruction_loss = mse(inputs, outputs)
reconstruction_loss *= timesteps * input_dim
kl_loss = 1 + z_log_var - tf.keras.backend.square(z_mean) - tf.keras.backend.exp(z_log_var)
kl_loss = tf.keras.backend.sum(kl_loss, axis=-1)
kl_loss *= -0.5
vae_loss = tf.keras.backend.mean(reconstruction_loss + kl_loss)
vae.add_loss(vae_loss)
vae.compile(optimizer='adam')
vae.summary()
Detailed Explanation:
Define the VAE Model:
outputs = decoder(encoder(inputs)[2])
vae = Model(inputs, outputs, name='vae_mlp')
- outputs = decoder(encoder(inputs)[2])
encoder(inputs)[2]: The encoder model is applied to the inputs to obtain the latent space representationz. The index[2]extractszfrom the encoder’s output, which is the encoded representation that will be fed into the decoder.decoder(...): The decoder model takes the latent vectorzand reconstructs the original input data.
- vae = Model(inputs, outputs, name=’vae_mlp’)
- Defines the VAE model that maps the input data to the reconstructed output. The VAE model combines the encoder and decoder to form a complete autoencoder that learns to reconstruct data from the latent space.
2. VAE Loss Calculation:
- Reconstruction Loss:
reconstruction_loss = mse(inputs, outputs)
reconstruction_loss *= timesteps * input_dim
mse(inputs, outputs): Computes the Mean Squared Error (MSE) between the original inputs and the reconstructed outputs. This measures how well the VAE reconstructs the input data.reconstruction_loss *= timesteps * input_dim: The reconstruction loss is scaled by the product oftimestepsandinput_dim. This scaling accounts for the total number of features being reconstructed across all time steps. This ensures that the loss reflects the total reconstruction error across the entire sequence.
- KL Divergence:
kl_loss = 1 + z_log_var - tf.keras.backend.square(z_mean) - tf.keras.backend.exp(z_log_var)
kl_loss = tf.keras.backend.sum(kl_loss, axis=-1)
kl_loss *= -0.5
1 + z_log_var - tf.keras.backend.square(z_mean) - tf.keras.backend.exp(z_log_var):1 + z_log_var: Represents the log variance term in the KL divergence calculation.- tf.keras.backend.square(z_mean): Penalizes the mean of the latent space representation.- tf.keras.backend.exp(z_log_var): Penalizes the variance of the latent space representation.tf.keras.backend.exp(z_log_var)converts the log variance to variance.
kl_loss = tf.keras.backend.sum(kl_loss, axis=-1): Sums the KL divergence values across the latent space dimensions. This produces a scalar value for each data sample, representing the total KL divergence for that sample.kl_loss *= -0.5: Scales the KL divergence by -0.5. This factor ensures that the loss reflects the negative log probability of the latent space distribution being close to a standard normal distribution.
- Total VAE Loss:
vae_loss = tf.keras.backend.mean(reconstruction_loss + kl_loss)
vae_loss = tf.keras.backend.mean(reconstruction_loss + kl_loss): Computes the total VAE loss as the mean of the sum of the reconstruction loss and KL divergence. This combined loss function guides the VAE to minimize both the reconstruction error and the divergence from the standard normal distribution.
3. Model Compilation:
vae.add_loss(vae_loss)
vae.compile(optimizer='adam')
vae.summary()
vae.add_loss(vae_loss): Adds the custom loss function to the VAE model. This ensures that the VAE will optimize this loss during training.vae.compile(optimizer='adam'): Compiles the VAE model with the Adam optimizer. Adam is a commonly used optimization algorithm that adjusts the model’s weights to minimize the loss function.vae.summary(): Displays a summary of the VAE model, showing the architecture, the total number of parameters, and how they are distributed across the layers. This helps verify that the model is set up correctly.
Training the Model
Training a Variational Autoencoder (VAE) involves using a dataset to teach the model how to reconstruct data while learning a useful latent space representation. Here is a detailed explanation of the code used for training the VAE model.
Code for Training:
# Train the VAE model
vae.fit(X_train, X_train,
epochs=50,
batch_size=128,
validation_data=(X_test, X_test))
Explanation:
Training the VAE Model:
vae.fit(X_train, X_train,
epochs=50,
batch_size=128,
validation_data=(X_test, X_test))
vae.fit(...): This function trains the VAE model using the provided training data (X_train) and target data (X_train). Here’s a breakdown of the parameters and process:X_train: This is the input data for training. For a VAE, the input data and the target data are the same because the model is trained to reconstruct the input data. So,X_trainis used both as the input and as the target output.epochs=50: Specifies the number of epochs for training. An epoch is one complete pass through the entire training dataset. Here, the model will go through the training data 50 times. The number of epochs determines how many times the model will be updated based on the loss function, impacting its ability to learn the patterns in the data. More epochs generally allow the model to learn more, but too many can lead to overfitting.batch_size=128: Defines the number of samples processed before the model’s internal weights are updated. A batch size of 128 means that the model will be updated after every 128 samples. The choice of batch size can affect the training dynamics, such as convergence speed and stability. Larger batch sizes can lead to more stable gradients but may require more memory.validation_data=(X_test, X_test): Provides a validation dataset to monitor the model’s performance during training. The validation data is separate from the training data and is used to evaluate how well the model generalizes to unseen data. In this case,X_testis used both as the validation input and output, similar to the training data. This allows monitoring of the model’s reconstruction quality on a separate set of data, helping to detect overfitting and assess how well the model performs on data it hasn’t seen during training.
Training Output
During training, you will see the loss values printed for each epoch. The output might look like this:
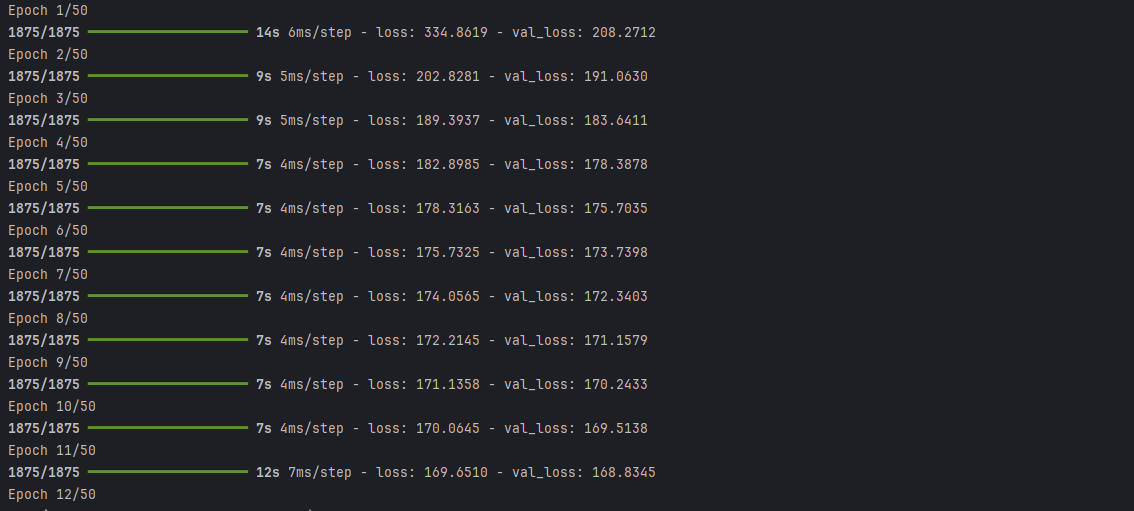
lossshows the combined loss (KL divergence + reconstruction loss) for the training set.val_lossshows the combined loss for the validation set.
Generating New Music Samples
After training the Variational Autoencoder (VAE), you can use it to generate new music samples. This involves sampling from the latent space and using the decoder to produce new musical data. Here’s a detailed explanation of the code used for generating and visualizing these new music samples.
Code for Music Generation:
# Generate new music samples
z_sample = np.random.normal(size=(1, 16))
generated_music = decoder.predict(z_sample)
# Plot or play generated music
plt.imshow(generated_music.reshape(timesteps, input_dim), aspect='auto', cmap='viridis')
plt.title('Generated Music Sample')
plt.show()
Detailed Explanation:
1. Sampling from the Latent Space:
z_sample = np.random.normal(size=(1, 16))
np.random.normal(size=(1, 16)): Generates a random latent vectorz_sampleby sampling from a normal distribution. The shape(1, 16)indicates that we are creating one latent vector with 16 dimensions. This vector is used as input to the decoder to generate new music.- Normal Distribution: The latent vector is drawn from a standard normal distribution with mean 0 and variance 1. This is typical for VAE generation, as the latent space is usually designed to approximate a standard normal distribution.
2. Generating Music with the Decoder:
generated_music = decoder.predict(z_sample)
decoder.predict(z_sample): Uses the decoder model to generate new music based on the sampled latent vectorz_sample. The decoder takes the latent vector and reconstructs it into a musical sequence. The output,generated_music, is a reconstructed sequence representing a new piece of music.
3. Visualizing the Generated Music:
plt.imshow(generated_music.reshape(timesteps, input_dim), aspect='auto', cmap='viridis')
plt.title('Generated Music Sample')
plt.show()
generated_music.reshape(timesteps, input_dim): Reshapes the generated music data into a 2D array where:timesteps: Represents the number of time steps in the musical sequence.input_dim: Represents the number of features at each time step (e.g., MIDI notes or other musical features).
plt.imshow(...): Displays the reshaped musical data as an image. Each pixel in the image corresponds to a feature value at a specific time step, creating a visual representation of the generated music.aspect='auto': Ensures that the aspect ratio of the plot adjusts automatically to fit the data.cmap='viridis': Sets the color map to ‘viridis’, which is a perceptually uniform colormap. This choice of color map helps in visualizing the data more clearly.
plt.title('Generated Music Sample'): Adds a title to the plot, describing the content as a generated music sample.plt.show(): Displays the plot.
Summary
- Data Preparation: Clean and preprocess musical data to feed into the VAE.
- Model Building: Define encoder and decoder networks to handle sequential musical data.
- Loss Function: Combine reconstruction loss and KL divergence to train the VAE.
- Training: Fit the model on musical data to learn meaningful patterns.
- Generation: Create new music samples by sampling from the latent space and decoding.
This process allows you to create a VAE that can generate novel musical compositions, blending learned styles and features in innovative ways.
Applications and Future Directions of Variational Autoencoders (VAEs) in Generative Music
Applications of VAEs in Generative Music
1. Music Composition and Production
VAEs are increasingly being used in music composition and production to create new and unique musical pieces. By learning from a wide range of existing compositions, VAEs can generate original music that blends different genres and styles. This capability is particularly useful for:
- Assisting Composers: Musicians and composers can use VAEs to explore novel musical ideas and generate variations of their compositions. This can serve as a creative tool to inspire new works and overcome writer’s block.
- Music Libraries: For music production companies, VAEs can automatically generate background tracks, jingles, or soundscapes, expanding the repertoire of available music quickly and efficiently.
2. Personalized Music Recommendations
VAEs can enhance music recommendation systems by tailoring playlists to individual listeners. By analyzing user preferences and listening histories, VAEs can generate music that aligns with a user’s unique taste. This has several benefits:
- Custom Playlists: Streaming services can use VAEs to create personalized playlists that reflect a user’s musical preferences, leading to a more engaging listening experience.
- Music Discovery: VAEs can introduce listeners to new genres and artists by blending familiar styles with novel elements, helping users discover music they might not have encountered otherwise.
3. Interactive Music Applications
VAEs enable the development of interactive music applications that respond to user input in real time. These applications include:
- Interactive Music Generators: Apps that allow users to input musical themes or ideas and receive new compositions generated by the VAE. This interaction can be used for educational purposes or as a creative tool.
- Adaptive Music Systems: Systems that adapt music in real time based on user interactions or environmental conditions, creating dynamic soundtracks for games or virtual environments.
4. Music Style Transfer
VAEs are used to transfer the style of one musical piece to another, preserving the original content while applying different stylistic elements. This technique is useful for:
- Remixing Music: Applying the style of a classical piece to a modern composition or vice versa, creating innovative remixes that blend different musical eras.
- Cross-Genre Compositions: Generating new compositions that combine elements from multiple genres, leading to fresh and unique musical styles.
Future Directions in Variational Autoencoders (VAEs) for Generative Music
1. Enhanced Model Architectures
Future research is likely to focus on developing more sophisticated VAE architectures to improve music generation capabilities. Potential advancements include:
- Hierarchical VAEs: Implementing hierarchical structures that capture multiple levels of musical abstraction, from basic notes to complex compositions. This can enhance the model’s ability to generate detailed and contextually rich music.
- Attention Mechanisms: Integrating attention mechanisms into VAEs to better capture long-range dependencies in musical sequences, improving the coherence and quality of generated music.
2. Multimodal Music Generation
Combining VAEs with other modalities, such as visual or textual data, can lead to innovative forms of music generation. For example:
- Multimodal Inputs: Using VAEs to generate music based on visual inputs, such as artwork or video content, creating soundtracks that reflect visual aesthetics.
- Text-to-Music Generation: Integrating natural language processing with VAEs to generate music from textual descriptions or lyrics, enabling more nuanced and contextually relevant compositions.
3. Improved Personalization Techniques
Advancements in personalization techniques will enhance how VAEs tailor music to individual preferences. Future directions include:
- Deep User Modeling: Developing more advanced models to capture and understand user preferences, incorporating aspects such as mood, context, and emotional responses to generate highly personalized music.
- Real-Time Adaptation: Enhancing VAEs to adapt music in real time based on user interactions or environmental changes, creating dynamic and responsive music experiences.
4. Ethical and Creative Considerations
As VAEs become more integrated into music creation, it is important to address ethical and creative considerations:
- Copyright and Originality: Ensuring that generated music respects copyright laws and maintains originality while using existing compositions as training data.
- Creative Agency: Balancing the use of AI-generated music with human creativity, ensuring that VAEs enhance rather than replace the creative process of musicians.
5. Integration with Other AI Technologies
Combining VAEs with other AI technologies can lead to further advancements in generative music:
- Generative Adversarial Networks (GANs): Exploring the integration of VAEs with GANs to enhance the quality and diversity of generated music.
- Reinforcement Learning: Using reinforcement learning techniques to optimize the music generation process, allowing VAEs to learn from user feedback and improve over time.
Conclusion
Summary of Key Points
Variational Autoencoders (VAEs) have brought a significant shift in the world of music creation. They allow us to create new music by learning from existing pieces. By encoding musical data into a simpler format and then decoding it to generate new compositions, VAEs help blend different styles and genres. This process leads to innovative and unique music that pushes the boundaries of traditional composition.
The Future of Generative Music with Variational Autoencoders (VAEs)
Looking ahead, VAEs hold exciting possibilities for music. As technology improves, we can expect even more sophisticated and creative uses of VAEs in music. They could help artists explore new genres, create personalized music experiences, and overcome creative blocks. The future will likely see VAEs being used to generate highly customized playlists and compositions, making music creation more inclusive and diverse.
Encouraging Creativity through Technology
VAEs not only transform music but also inspire new ways of thinking about creativity. By using these models, musicians and composers can discover fresh ideas and explore new directions in their work. Technology like VAEs provides tools that can expand artistic horizons and encourage innovation, offering endless possibilities for creativity in the music industry.
External Resources
Research Papers and Articles:
- “Auto-Encoding Variational Bayes” by Kingma and Welling (2014) – This seminal paper introduces the VAE concept and provides foundational knowledge essential for understanding how VAEs work. Read the paper
- “A Survey of Variational Autoencoders” by Doersch (2016) – An extensive review of VAEs, including their theoretical background and various applications. Read the survey
GitHub Repositories:
- Variational Autoencoders (VAEs) in TensorFlow – A repository with code examples for implementing VAEs using TensorFlow.
- MusicVAE by Magenta – A project by Google’s Magenta team that uses VAEs for music generation, with code and examples.
FAQs
What is a Variational Autoencoder (VAE)?
A Variational Autoencoder (VAE) is a type of neural network that learns to encode input data into a compressed representation and then decodes it back into its original form. In generative music, VAEs capture the essential features of musical data, allowing them to generate new and creative compositions by blending various styles and genres.
How do VAEs work in generative music?
VAEs work by first encoding musical data (like MIDI files) into a latent space, a lower-dimensional representation of the music’s essential features. The decoder then reconstructs music from this latent space. By sampling from the latent space, VAEs can generate new musical compositions that retain the original style but include novel variations.
How do you train a VAE for music generation?
Training a VAE involves several steps:
- Data Preparation: Collect and preprocess musical data, such as MIDI files.
- Model Design: Build the encoder and decoder networks, setting up the latent space to capture essential features of the music.
- Loss Function: Define a loss function that combines reconstruction loss and KL divergence to train the VAE effectively.
- Training: Fit the VAE model on the preprocessed data, tuning hyperparameters and monitoring training progress to ensure the model learns well.
Can VAEs generate completely original music?
Yes, VAEs can generate completely original music by sampling from the latent space. While the generated music may be influenced by the training data, VAEs can produce novel combinations and variations that were not present in the original dataset.






Leave a Reply