

What is generative AI and how does it work?
Introduction to Generative AI
Generative AI refers to a subset of artificial intelligence that focuses on creating new content. This can include images, text, music, and even code. Unlike traditional AI, which analyzes data to make predictions or decisions, generative AI uses models to produce original content. It’s like teaching a machine to be creative.
Key Concepts
- Models: The core of generative AI is the model, which is trained on large datasets to learn patterns and structures. Common models include Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs).
- Training Data: Generative AI models are trained on vast amounts of data. For example, a model that generates text might be trained on thousands of books and articles.
- Generation: Once trained, these models can generate new content based on the learned patterns. For example, a text model can write a new article, or an image model can create a new picture.
Key Takeaways Table
| Key Points | Details | |
| Definition | Generative AI is AI that creates new content based on learned patterns. | |
| Evolution | From simple rule-based systems to advanced neural networks like GANs. | |
| Applications | Art, music, writing, game development, healthcare, and more. | |
| Importance | Revolutionizing creative industries and enhancing human capabilities. |
What is Generative AI? An Introduction to the Future of Machine Learning
What is Generative AI?
Generative AI is a field of artificial intelligence that focuses on creating new content. Instead of just analyzing data, it produces original outputs like text, images, music, and even complex simulations.
What are the Types of Generative AI Models?
Generative AI models are designed to create new content, whether it’s text, images, or other types of data. Here’s a look at the different types of generative AI models:
1. Generative Adversarial Networks (GANs):
Overview: GANs consist of two neural networks: a generator and a discriminator. The generator creates fake data, and the discriminator evaluates its authenticity.
- Generator: Learns to produce data that is similar to the real data.
- Discriminator: Learns to distinguish between real and fake data.
- Training: These two networks compete in a zero-sum game, where the generator tries to fool the discriminator, and the discriminator tries to correctly identify real versus fake data.
Applications:
- Image generation (e.g., creating realistic images from random noise).
- Style transfer (e.g., applying the style of one image to another).
- Data augmentation (e.g., generating new training data for machine learning models).
2. Variational Autoencoders (VAEs):
Overview: VAEs are a type of autoencoder that learns a latent variable model for the data. They consist of an encoder, a decoder, and a latent space.
- Encoder: Maps the input data to a latent space representation.
- Latent Space: A compressed representation of the data.
- Decoder: Reconstructs the data from the latent space representation.
- Training: The model is trained to minimize the reconstruction error and ensure that the latent space follows a predefined distribution (e.g., Gaussian).
Applications:
- Image generation and reconstruction.
- Data compression.
- Anomaly detection (e.g., identifying outliers by reconstruction error).
In image generation, particularly with faces, generative AI can create new faces by learning from a dataset of face images. VAEs, for example, can take a compressed representation of a face and generate a new face with similar features. Additionally, these models can interpolate between two faces to create new, intermediate faces, showcasing a blend of features from both original faces.
3. Autoregressive Models
Overview: Autoregressive models generate data by predicting the next value in a sequence based on the previous values.
- Training: The model is trained on sequences of data, learning to predict each value in the sequence given the previous values.
- Generation: Data is generated one step at a time, with each new value conditioned on the previously generated values.
Applications:
- Text generation (e.g., generating coherent sentences or paragraphs).
- Speech synthesis (e.g., generating realistic speech from text).
- Music generation (e.g., composing new melodies).
Example Models:
- GPT (Generative Pre-trained Transformer): Used for text generation.
- WaveNet: Used for speech synthesis.
4. Flow-based Models
Overview: Flow-based models learn to transform simple probability distributions (e.g., Gaussian) into complex ones by applying a series of invertible transformations.
- Training: The model is trained to maximize the likelihood of the data under the transformed distribution.
- Generation: Data can be generated by applying the inverse transformations to samples from the simple distribution.
Applications:
- Density estimation.
- Image generation (e.g., generating high-quality images).
Example Models:
- RealNVP (Real-valued Non-Volume Preserving transformations).
- Glow (Generative Flow).
5. Diffusion Models
Overview: Diffusion models are a type of generative AI model used to create new data by learning the distribution of a dataset and generating new samples from this distribution. They have gained popularity for their ability to generate high-quality images and other types of content.
- Training: The model learns to reverse a diffusion process that gradually adds noise to the data.
- Generation: Data is generated by starting with noise and running the learned reverse diffusion process.
Applications:
- High-quality image generation.
- Denoising tasks.
Example Models:
- DDPMs (Denoising Diffusion Probabilistic Models).
Diagram: Types of Generative AI Models

How Does Generative AI Work?
Generative AI relies heavily on neural networks, particularly two key types: Generative Adversarial Networks (GANs) and Variational Autoencoders (VAEs). Let’s understand how these work and how they help in creating new content.
Neural Networks and Generative Models
Neural networks are the foundation of many generative models. These models use neural networks to learn from data and generate new, original content. Here’s a look at how neural networks are employed in generative models and the types of generative models commonly used.
Neural Networks
Neural networks are computational models inspired by the human brain. They consist of layers of interconnected nodes (neurons), where each connection has an associated weight. Neural networks learn to perform tasks by adjusting these weights based on the input data. They are particularly powerful for tasks that involve pattern recognition and data generation. let’s see how neural networks works
- Nodes (Neurons): These are small units in the network that process input data.
- Layers: Nodes are organized in layers. Each layer receives input from the previous layer and passes output to the next layer.
- Weights and Biases: These are parameters adjusted during training to help the network learn better.
Think of a neural network like a complex web of interconnected lights where each light (neuron) can be turned on or off (processing data) to create patterns (learning).
Generative Models
Generative models are a subset of machine learning models that can generate new data samples from learned distributions. Here are some common types of generative models that use neural networks:
- Generative Adversarial Networks (GANs)
- Variational Autoencoders (VAEs)
- Diffusion Models
Generative Adversarial Networks (GANs)
How GANs Work
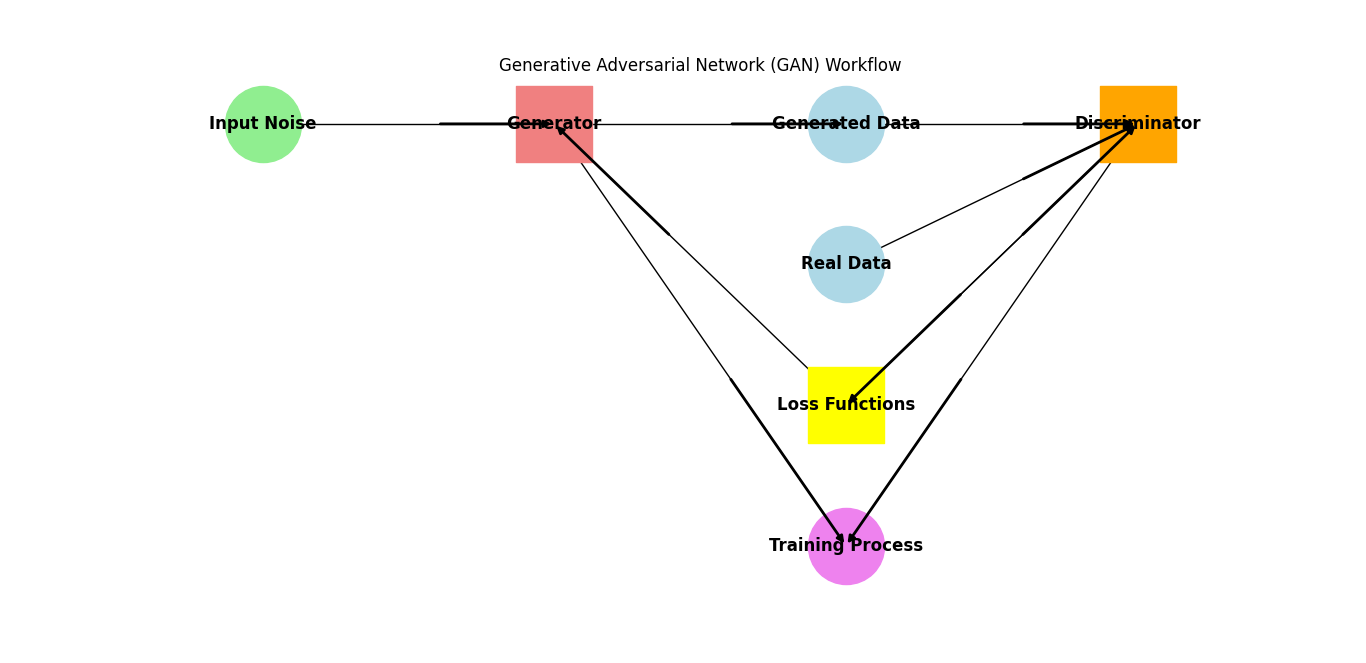
Generative Adversarial Networks (GANs) are a class of generative models that use two neural networks, a generator and a discriminator, to create new data samples that are similar to a given dataset. Here’s a detailed look at how GANs work:
The Structure of GANs
- Generator: This neural network creates new data samples. It starts with random noise and transforms it into a data sample that resembles the real data.
- Discriminator: This neural network evaluates the data samples. It takes in both real data (from the training set) and fake data (from the generator) and attempts to distinguish between them.
The Training Process
GANs are trained through an adversarial process, where the generator and discriminator compete against each other. The training process involves the following steps:
- Generate Fake Data: The generator creates a batch of fake data samples from random noise.
- Discriminator Training: The discriminator is trained with two batches of data: real data (labeled as real) and fake data from the generator (labeled as fake). The discriminator’s goal is to correctly identify real vs. fake data.
- Generator Training: The generator is trained to produce data that the discriminator cannot distinguish from real data. The generator’s goal is to fool the discriminator.
The Adversarial Game
- Discriminator’s Objective: The discriminator aims to maximize its accuracy in distinguishing real data from fake data.
- Generator’s Objective: The generator aims to minimize the discriminator’s ability to distinguish real data from fake data.
Loss Functions
- Discriminator Loss: Measures how well the discriminator can distinguish between real and fake data.
- Generator Loss: Measures how well the generator can fool the discriminator.
Mathematically, the objectives can be expressed as:
Where:
Training Loop
- Train Discriminator:
- Feed it a batch of real data and a batch of fake data.
- Calculate the discriminator loss and update the discriminator’s weights.
- Train Generator:
- Generate a batch of fake data.
- Feed the fake data to the discriminator to get predictions.
- Calculate the generator loss based on the discriminator’s predictions and update the generator’s weights.
- Iterate: Repeat the above steps until the generator produces sufficiently realistic data, or until the training converges.
Challenges in Training GANs
- Mode Collapse: The generator produces a limited variety of outputs.
- Training Stability: The adversarial training process can be unstable and may not always converge.
- Balance: Ensuring the generator and discriminator improve together can be difficult; if one improves too quickly, the other may struggle to catch up.
Applications of GANs
- Image Generation: Creating realistic images from random noise.
- Image-to-Image Translation: Converting images from one domain to another, such as turning sketches into photos.
- Text-to-Image Synthesis: Generating images based on textual descriptions.
- Super-Resolution: Enhancing the resolution of images.
GANs have revolutionized the field of generative modeling, enabling the creation of highly realistic data that can be used in various applications, from art generation to data augmentation for machine learning.
Diagram: GANs Workflow
Example Code for GANs
Here’s a simple example of how GANs are implemented in code using TensorFlow:
import tensorflow as tf
from tensorflow.keras import layers
# Define the generator
def create_generator():
model = tf.keras.Sequential([
layers.Dense(128, activation='relu', input_shape=(100,)),
layers.Dense(784, activation='sigmoid'),
layers.Reshape((28, 28, 1))
])
return model
# Define the discriminator
def create_discriminator():
model = tf.keras.Sequential([
layers.Flatten(input_shape=(28, 28, 1)),
layers.Dense(128, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
return model
# Compile and train GAN
def train_gan(generator, discriminator, epochs=10000):
# Training loop here
pass
Explanation
This code defines the architecture for a Generative Adversarial Network (GAN) using TensorFlow and Keras. A GAN consists of two neural networks: a generator and a discriminator. Here’s a breakdown of each part of the code and what it does:
1. Importing Libraries
import tensorflow as tf
from tensorflow.keras import layers
tensorflowis the library used for creating and training machine learning models.layersis a module fromtensorflow.kerasthat contains various building blocks for neural networks.
2. Creating the Generator
def create_generator():
model = tf.keras.Sequential([
layers.Dense(128, activation='relu', input_shape=(100,)),
layers.Dense(784, activation='sigmoid'),
layers.Reshape((28, 28, 1))
])
return model
tf.keras.Sequential: This defines a linear stack of layers.layers.Dense(128, activation='relu', input_shape=(100,)): The first layer is a dense (fully connected) layer with 128 neurons and ReLU activation function. The input shape is 100, meaning the generator expects a 100-dimensional input vector.layers.Dense(784, activation='sigmoid'): The second dense layer outputs 784 values with a sigmoid activation function. 784 is the number of pixels in a 28×28 image (28*28 = 784).layers.Reshape((28, 28, 1)): The output is reshaped to a 28×28 image with 1 color channel (grayscale).
The generator creates fake images from random noise.
3. Creating the Discriminator
def create_discriminator():
model = tf.keras.Sequential([
layers.Flatten(input_shape=(28, 28, 1)),
layers.Dense(128, activation='relu'),
layers.Dense(1, activation='sigmoid')
])
return model
layers.Flatten(input_shape=(28, 28, 1)): Flattens the 28×28 image into a 1D vector of 784 values.layers.Dense(128, activation='relu'): A dense layer with 128 neurons and ReLU activation function.layers.Dense(1, activation='sigmoid'): The final layer outputs a single value between 0 and 1 using a sigmoid activation function. This output represents the probability that the input image is real.
The discriminator’s job is to distinguish between real images (from a dataset) and fake images (produced by the generator).
4. Training the GAN
def train_gan(generator, discriminator, epochs=10000):
# Training loop here
pass
- This function is a placeholder for the training loop of the GAN. The training process involves alternating between training the discriminator and the generator. During training:
- Discriminator is trained to correctly classify real and fake images.
- Generator is trained to produce images that are classified as real by the discriminator.
The epochs parameter specifies how many times the entire dataset should be passed through the network.
Must Read
- How to A/B Test Machine Learning Models the Right Way
- How to Debug ML Inference Latency and Throughput Issues
- Shadow Deployment and Canary Testing for Machine Learning Models: A Practical Guide
- How to Build an ML Monitoring Dashboard from Scratch (Streamlit Tutorial)
- ML Model Monitoring: How to Detect Data Drift and Model Decay in Production
Variational Autoencoders (VAEs)
How VAEs Work
Variational Autoencoders (VAEs) are a type of generative model that use neural networks to encode data into a lower-dimensional latent space and then decode it back to the original data space. This allows them to generate new data samples by sampling from the latent space. Here’s a detailed explanation of how VAEs work:
The Structure of VAEs
- Encoder: This neural network compresses the input data into a latent representation (a lower-dimensional space). Instead of encoding the data to a single point, the encoder maps it to a distribution, typically a Gaussian distribution.
- Latent Space: This is the lower-dimensional space where the data is represented as a distribution. Each data point is encoded as a mean and a standard deviation, defining the Gaussian distribution in this space.
- Decoder: This neural network reconstructs the original data from the latent representation. It takes a sample from the distribution in the latent space and transforms it back to the data space.
The VAE Process
- Encoding: The encoder network takes the input data x and maps it to two vectors: μ (mean) and σ\sigmaσ (standard deviation). These vectors define a Gaussian distribution in the latent space.
2. Sampling: A latent vector z is sampled from the Gaussian distribution defined by μ\muμ and σ\sigmaσ.
Here, ϵ\epsilonϵ is a random variable sampled from a standard normal distribution.
3. Decoding: The decoder network takes the sampled latent vector z and reconstructs the original data x^.
Loss Function
The VAE loss function has two components:
- Reconstruction Loss: Measures how well the decoder can reconstruct the original data from the latent representation. This is often the mean squared error or binary cross-entropy between the input data x and the reconstructed data x^.
2. KL Divergence: Measures the difference between the encoded distribution (a Gaussian with mean μ\mu and standard deviation σ\sigmaσ) and a standard normal distribution. This regularizes the latent space to ensure it follows a standard normal distribution, which makes sampling new data easier.
- Where q(z∣x)q(z|x)q(z∣x) is the encoded distribution and p(z) is the prior (standard normal distribution).
The total loss is a combination of these two components:
VAE Loss = Reconstruction Loss + KL Divergence
Training Process
- Feed Input Data: Pass the input data x through the encoder to obtain μ\muμ and σ\sigmaσ.
- Sample Latent Vector: Sample a latent vector z from the Gaussian distribution defined by μ\muμ and σ\sigmaσ.
- Reconstruct Data: Pass the latent vector z through the decoder to obtain x^.
- Calculate Loss: Compute the VAE loss using the reconstruction loss and KL divergence.
- Update Weights: Use backpropagation to update the weights of the encoder and decoder networks to minimize the VAE loss.
Applications of VAEs
- Image Generation: VAEs can generate new images by sampling from the latent space and decoding them.
- Data Denoising: VAEs can learn to remove noise from data by training on noisy inputs and clean outputs.
- Anomaly Detection: By learning the distribution of normal data, VAEs can identify anomalies as data points with high reconstruction error.
- Representation Learning: VAEs can learn meaningful latent representations of data, useful for downstream tasks like clustering and classification.
VAEs provide a powerful framework for generative modeling, enabling the creation of new data samples and learning useful representations of data in a lower-dimensional space.
Diagram: VAEs Workflow

Example Code for VAEs
Here’s a basic example of how VAEs are implemented in code using TensorFlow:
import tensorflow as tf
from tensorflow.keras import layers
# Define the encoder
def create_encoder():
model = tf.keras.Sequential([
layers.Flatten(input_shape=(28, 28, 1)),
layers.Dense(128, activation='relu'),
layers.Dense(64)
])
return model
# Define the decoder
def create_decoder():
model = tf.keras.Sequential([
layers.Dense(128, activation='relu', input_shape=(64,)),
layers.Dense(784, activation='sigmoid'),
layers.Reshape((28, 28, 1))
])
return model
# Compile and train VAE
def train_vae(encoder, decoder, epochs=10000):
# Training loop here
pass
Explanation
This code sets up the architecture for a Variational Autoencoder (VAE) using TensorFlow and Keras. VAEs are used for unsupervised learning tasks and are particularly useful in generating new data samples similar to the input data. Here’s a breakdown of each part of the code:
1. Importing Libraries
import tensorflow as tf
from tensorflow.keras import layers
tensorflowis the library used for creating and training machine learning models.layersis a module fromtensorflow.kerascontaining various building blocks for neural networks.
2. Creating the Encoder
def create_encoder():
model = tf.keras.Sequential([
layers.Flatten(input_shape=(28, 28, 1)),
layers.Dense(128, activation='relu'),
layers.Dense(64)
])
return model
tf.keras.Sequential: This defines a linear stack of layers.layers.Flatten(input_shape=(28, 28, 1)): Flattens the 28×28 grayscale image into a 1D vector of 784 values.layers.Dense(128, activation='relu'): A dense layer with 128 neurons and ReLU activation function. This layer learns to extract features from the input data.layers.Dense(64): The final dense layer reduces the dimensionality of the data to 64. This represents the latent space, where the VAE will learn a compressed representation of the data.
The encoder maps the input image to a lower-dimensional latent space representation.
3. Creating the Decoder
def create_decoder():
model = tf.keras.Sequential([
layers.Dense(128, activation='relu', input_shape=(64,)),
layers.Dense(784, activation='sigmoid'),
layers.Reshape((28, 28, 1))
])
return model
layers.Dense(128, activation='relu', input_shape=(64,)): A dense layer with 128 neurons and ReLU activation function. This layer takes the latent space representation as input and starts reconstructing the image.layers.Dense(784, activation='sigmoid'): A dense layer that outputs 784 values with a sigmoid activation function. This will produce a flattened version of the reconstructed image.layers.Reshape((28, 28, 1)): Reshapes the output to a 28×28 grayscale image.
The decoder reconstructs the image from the compressed latent space representation.
4. Training the VAE
def train_vae(encoder, decoder, epochs=10000):<br>
# Training loop here<br>
pass- This function is a placeholder for the training loop of the VAE. Training involves:
- Encoding: Using the encoder to map input images to latent space.
- Decoding: Using the decoder to reconstruct images from the latent space representation.
- Loss Function: The loss function typically includes two components:
- Reconstruction Loss: Measures how well the decoder reconstructs the original images.
- KL Divergence Loss: Measures how closely the learned latent space distribution matches a standard normal distribution.
The epochs parameter specifies how many times the entire dataset should be passed through the network during training.
Comparing GANs and VAEs
Both GANs and VAEs are used for generating new content, but they have different strengths:

Key Differences
1. Architecture and Training Process:
- GANs:
- Components: Consist of two neural networks—a generator and a discriminator.
- Training: The generator creates fake data, and the discriminator evaluates it against real data. They are trained in an adversarial manner, where the generator tries to fool the discriminator, and the discriminator tries to distinguish between real and fake data.
- Objective: The generator aims to minimize the discriminator’s ability to tell real from fake, while the discriminator aims to maximize its classification accuracy.
- VAEs:
- Components: Consist of an encoder and a decoder.
- Training: The encoder compresses the input data into a latent space, and the decoder reconstructs the data from this representation. The model is trained to minimize the reconstruction error and ensure the latent space follows a standard normal distribution using a KL divergence term.
- Objective: The encoder-decoder network aims to reconstruct the input data while regularizing the latent space to follow a known distribution.
2. Latent Space Representation:
- GANs: The latent space in GANs is typically unstructured, and there is no explicit control over the distribution of the latent variables. This can make interpolation and understanding of the latent space less straightforward.
- VAEs: The latent space is explicitly regularized to follow a standard normal distribution. This structured latent space allows for smooth interpolation between points and easier sampling.
3. Output Quality:
- GANs: Generally produce sharper and more realistic images compared to VAEs. The adversarial training helps GANs learn to generate high-quality, detailed images.
- VAEs: Tend to produce blurrier images due to the reliance on reconstruction loss and the regularization of the latent space. However, VAEs provide more control over the generation process and can smoothly interpolate between different data points.
4. Training Stability:
- GANs: Training can be unstable and difficult. The adversarial nature often leads to issues like mode collapse, where the generator produces limited varieties of outputs, and the generator and discriminator can fall out of sync.
- VAEs: Generally more stable to train compared to GANs. The loss functions are well-defined and more straightforward, leading to more predictable training dynamics.
Similarities
- Generative Capability: Both GANs and VAEs are capable of generating new data samples that resemble the input data distribution.
- Deep Learning Based: Both models leverage deep learning techniques and neural networks to learn data distributions.
- Applications: Used in similar applications like image generation, data augmentation, and representation learning.
- GANs excel in generating high-quality, realistic images but are challenging to train and lack a structured latent space.
- VAEs provide a stable training process and a structured latent space, making them useful for applications requiring interpolation and representation learning, but they tend to produce blurrier images.
Choosing between GANs and VAEs depends on the specific application requirements, such as the need for high-quality image generation (GANs) versus a structured latent space and stable training (VAEs). Both models have their unique advantages and can be powerful tools in the field of generative modeling.
What are the Key Components of Generative AI?
Generative AI encompasses a range of techniques and models designed to generate new, original data from learned patterns in existing datasets. Here are the key components that form the foundation of generative AI:
1. Neural Networks
Neural networks are the backbone of many generative AI models. They consist of layers of interconnected nodes (neurons) that process input data to produce output data. In generative AI, neural networks learn the underlying distribution of the data and generate new samples from this distribution. Key types of neural networks used in generative AI include:
- Feedforward Neural Networks: Basic building blocks for many generative models.
- Convolutional Neural Networks (CNNs): Particularly useful for image generation tasks.
- Recurrent Neural Networks (RNNs): Used for sequential data generation, such as text or time series data.
- Transformers: Employed for tasks like text generation and language modeling due to their ability to handle long-range dependencies.
2. Generative Models
Generative models are algorithms that learn to produce new data samples that are similar to the input data. Common generative models include:
- Generative Adversarial Networks (GANs): Consist of a generator and a discriminator that compete against each other to produce realistic data.
- Variational Autoencoders (VAEs): Use an encoder-decoder architecture to learn a latent space representation and generate new data by sampling from this space.
- Diffusion Models: Generate data by gradually denoising a sample from a random distribution, effectively reversing a diffusion process.
3. Latent Space
Latent space refers to a lower-dimensional representation of the data learned by models like VAEs and GANs. In the latent space, data points are encoded as vectors that capture the essential features of the data. This space allows for:
- Sampling: New data can be generated by sampling points from the latent space and decoding them into the original data space.
- Interpolation: Smooth transitions between different data points can be achieved by interpolating between their representations in the latent space.
4. Training Process
The training process is crucial for generative AI models to learn the underlying data distribution. It involves:
- Loss Functions: Measure the difference between the generated data and the real data, guiding the model to improve its generation capabilities. Common loss functions include reconstruction loss (for VAEs) and adversarial loss (for GANs).
- Optimization Algorithms: Methods like stochastic gradient descent (SGD) or Adam are used to minimize the loss function and update the model’s weights.
- Adversarial Training: Specific to GANs, where the generator and discriminator networks are trained in an adversarial setup to improve each other’s performance.
5. Regularization Techniques
Regularization techniques help prevent overfitting and ensure the generative model generalizes well to new data. Common techniques include:
- Dropout: Randomly dropping units during training to prevent over-reliance on specific neurons.
- Weight Regularization: Adding penalties to the loss function to constrain the weights (e.g., L2 regularization).
6. Evaluation Metrics
Evaluating generative models is challenging due to the subjective nature of generated data. Common evaluation metrics include:
- Inception Score (IS): Measures the quality and diversity of generated images by assessing the confidence of a pre-trained classifier.
- Frechet Inception Distance (FID): Compares the distributions of real and generated data in a feature space, providing a sense of both quality and diversity.
- Reconstruction Error: Used in VAEs to assess how well the model can reconstruct the original data from the latent space.
How These Components Interact
The key components of generative AI—neural networks, generative models, latent space, training processes, regularization techniques, evaluation metrics, and applications—interact in a cohesive manner to enable the generation of new, original data. Here’s how these components work together:
1. Neural Networks and Generative Models
Neural networks are the core building blocks of generative models. They consist of interconnected layers that process data through various transformations. The interaction between neural networks and generative models can be described as follows:
- In GANs: The generator network generates new data samples, while the discriminator network evaluates these samples against real data. The neural networks in GANs are adversarial, meaning the generator and discriminator have opposing objectives. The generator tries to create realistic data to fool the discriminator, while the discriminator aims to distinguish between real and generated data.
- In VAEs: The encoder network maps input data to a latent space representation (mean and standard deviation), and the decoder network reconstructs the data from this latent representation. The neural networks in VAEs work together to compress data into a latent space and then reconstruct it, learning a meaningful representation of the data distribution.
- In Diffusion Models: Neural networks are used to model the forward and reverse diffusion processes. The forward process adds noise to the data, while the reverse process, modeled by a neural network, learns to remove the noise and generate new data.
2. Latent Space and Data Generation
Latent space plays a critical role in generating new data:
- In VAEs: Data is encoded into a latent space where each point represents a distribution of possible data samples. By sampling from this latent space and decoding the samples, VAEs can generate new data that resembles the training data.
- In GANs: The latent space is used by the generator to produce new data samples. Random noise is sampled from the latent space and transformed into data through the generator network. The structure and properties of the latent space influence the quality and diversity of the generated data.
3. Training Process and Loss Functions
The training process involves optimizing neural networks to improve their performance based on specific loss functions:
- In GANs: The generator and discriminator are trained simultaneously but with opposing objectives. The generator aims to minimize the discriminator’s ability to distinguish between real and fake data, while the discriminator tries to maximize its classification accuracy. The adversarial loss functions guide this process.
- In VAEs: The encoder and decoder are trained to minimize the reconstruction loss (how well the decoder reconstructs the original data) and the KL divergence (how well the latent space follows a standard normal distribution). This training process ensures that the latent space is well-structured and that the data can be accurately reconstructed.
4. Regularization Techniques and Stability
Regularization techniques help stabilize the training process and prevent overfitting:
- In GANs: Techniques like feature matching and historical averaging can stabilize training by ensuring that the generator does not produce similar outputs repeatedly. Regularization helps balance the generator and discriminator’s performance.
- In VAEs: Regularization is applied to the latent space through the KL divergence term in the loss function. This ensures that the latent space follows a known distribution, which helps in generating diverse and coherent samples.
5. Evaluation Metrics and Model Performance
Evaluation metrics are used to assess the quality of generated data and the performance of the generative model:
- In GANs: Metrics like Inception Score (IS) and Frechet Inception Distance (FID) are used to evaluate the quality and diversity of generated images. These metrics assess how well the generated data mimics real data.
- In VAEs: Reconstruction error is used to measure how accurately the model reconstructs input data from the latent space. Lower reconstruction error indicates better performance.
6. Applications and Real-World Impact
Generative models are applied in various domains, leveraging the interaction of all the components:
- Image Generation: GANs and VAEs generate realistic images for creative applications, such as art and design.
- Text Generation: Models based on VAEs and transformers generate coherent and contextually relevant text for applications like chatbots and content creation.
- Data Augmentation: Generative models create synthetic data to enhance training datasets for machine learning.
- Music and Audio Synthesis: Generative models produce new music or sound effects, expanding creative possibilities in media.
How Neural Networks Changed Generative AI
Neural networks have profoundly transformed the field of generative AI, enabling more sophisticated, realistic, and diverse data generation. Here’s how neural networks have changed generative AI:
1. Enhanced Model Complexity and Capacity
Neural networks, particularly deep learning models, allow for more complex architectures with multiple layers and units. This increased capacity has enabled the following advancements in generative AI:
- Higher Dimensional Data Representation: Deep neural networks can capture intricate patterns in high-dimensional data, such as images, text, and audio. This allows for more realistic and detailed data generation.
- Complex Feature Learning: Neural networks can automatically learn and extract complex features from data, leading to more accurate and diverse generative models.
2. Development of Advanced Generative Models
Neural networks have paved the way for several groundbreaking generative models, including:
- Generative Adversarial Networks (GANs): Introduced by Ian Goodfellow and colleagues, GANs use two neural networks—a generator and a discriminator—that compete against each other. The generator creates synthetic data, while the discriminator evaluates its authenticity. This adversarial setup has led to the generation of highly realistic images, videos, and other data types.
- Variational Autoencoders (VAEs): VAEs use neural networks to learn a probabilistic latent space representation of data. The encoder maps data to a latent space distribution, and the decoder reconstructs data from this space. VAEs have been effective in generating new samples, image denoising, and anomaly detection.
- Diffusion Models: These models use neural networks to model the forward and reverse diffusion processes. They progressively add and then remove noise to generate high-quality data, leading to improved performance in tasks like image generation.
3. Improved Training Techniques
Neural networks have introduced advanced training techniques that enhance the performance and stability of generative models:
- Backpropagation and Optimization Algorithms: Techniques like stochastic gradient descent (SGD) and Adam optimize neural network parameters, allowing for effective training of complex models. These methods help in minimizing loss functions and improving generative capabilities.
- Regularization Methods: Techniques such as dropout and weight regularization prevent overfitting and ensure that neural networks generalize well to new data. These methods stabilize training and improve the quality of generated data.
4. Scalability and Flexibility
Neural networks offer scalability and flexibility, enabling the development of large-scale generative models:
- Large-Scale Models: Neural networks can scale to handle large datasets and complex tasks. This scalability has led to the creation of powerful generative models capable of producing high-quality and diverse outputs.
- Transfer Learning and Pretrained Models: Transfer learning allows models trained on one task to be adapted for another. Pretrained models, such as GPT-3 or StyleGAN, can be fine-tuned for specific generative tasks, improving performance and reducing training time.
5. Enhanced Realism and Creativity
Neural networks have significantly improved the realism and creativity of generated data:
- High-Quality Image Generation: Models like GANs and diffusion models produce images with high fidelity and detail, making them useful for applications in art, design, and media.
- Creative Content Generation: Neural networks can generate novel and creative content, such as music compositions, text, and artwork. This capability has opened new avenues for creative expression and content creation.
6. Broadened Applications
The advancements in neural networks have expanded the range of applications for generative AI:
- Medical Imaging: Generative models assist in synthesizing medical images for training and diagnostics, helping in disease detection and treatment planning.
- Personalization and Customization: Generative AI models can create personalized content, such as tailored recommendations, customized designs, and individualized experiences.
- Synthetic Data Generation: Neural networks generate synthetic data for various applications, including training machine learning models, augmenting datasets, and simulating scenarios for research and development.
7. Ethical Considerations and Challenges
The power of neural networks in generative AI also brings ethical considerations and challenges:
- Deepfakes and Misinformation: The ability to create highly realistic synthetic media raises concerns about misinformation and malicious use. Efforts are being made to develop detection methods and ethical guidelines.
- Bias and Fairness: Generative models can inadvertently propagate biases present in training data. Ensuring fairness and addressing bias in generative AI is an ongoing area of research.

How They Work:
- Layers: Neural networks have multiple layers. The first layer receives the input data (like images or text), and each subsequent layer processes this data to find patterns.
- Nodes: Each node in a layer performs a mathematical operation on the data it receives. The result is passed to the next layer, where it’s further processed.
Example:
Imagine a neural network trained to recognize cats in photos. The first layer might detect basic shapes and edges. The next layers could recognize more complex features, like fur and ears, ultimately identifying the image as a cat.
Benefits:
- Learning Patterns: Neural networks can identify intricate patterns in data. They’re not limited to simple rules but can understand and reproduce complex features.
- Adaptability: They improve their performance as they learn from more data. The more examples they see, the better they get at recognizing patterns.
How is Generative AI Different from Traditional AI?
Understanding Traditional AI: Classification and Prediction
Traditional AI encompasses a range of technologies focused on classification and prediction. Here’s a detailed look at these two core functions and how they work in practice.
1. Classification in Traditional AI
Definition: Classification is the process of sorting data into predefined categories or classes. The AI system is trained to recognize patterns and features in the data to categorize it correctly.
How It Works:
- Training: The AI model is trained on a dataset where the categories are already known. For example, if we’re training a spam filter, the dataset might include emails labeled as “spam” or “not spam.”
- Feature Extraction: The model identifies key features in the data that help distinguish between categories. In the case of emails, features might include specific words, phrases, or patterns.
- Classification: Once trained, the model uses these features to classify new, unseen data. For instance, it can sort a new email into “spam” or “not spam” based on the patterns it has learned.
Example: Spam Filters
- Objective: To automatically sort emails into “spam” or “not spam.”
- Process:
- Training Data: Emails are labeled as spam or not spam.
- Features: Keywords like “free,” “winner,” or “buy now” are identified.
- Classification: New emails are analyzed and classified based on the presence of these keywords.
2. Prediction in Traditional AI
Definition: Prediction involves forecasting future events or outcomes based on historical data. The AI system uses patterns from past data to make informed guesses about future events.
How It Works:
- Training: The AI model is trained on historical data where the outcomes are known. For example, a sales forecasting model might use past sales data to predict future sales.
- Pattern Recognition: The model identifies trends, patterns, and relationships in the data that are used to make predictions.
- Prediction: After training, the model uses the identified patterns to estimate future values or outcomes based on new input data.
Example: Sales Forecasting
- Objective: To estimate future sales based on historical sales data.
- Process:
- Training Data: Historical sales data, including dates and sales figures.
- Patterns: Seasonal trends, growth rates, and other patterns are identified.
- Prediction: Future sales are forecasted based on these patterns.
Let’s Summarize Traditional AI
- Classification: Focuses on sorting data into predefined categories based on learned features. It’s useful for tasks like filtering emails or categorizing images.
- Prediction: Focuses on forecasting future events or values using patterns from historical data. It’s useful for tasks like estimating sales or predicting stock prices.
These traditional AI functions are fundamental to many applications, helping automate processes and provide insights based on data. They are critical for tasks that involve sorting and forecasting, which are common in various industries.
Understanding Generative AI
Focus: Generative AI is centered around the creation of new content.
- Creation: Unlike traditional AI, which works with existing data, generative AI creates new data that wasn’t part of the original training set.
- Examples: This includes generating new images, composing music, or writing text that mimics a certain style or genre.
Examples:
- Image Generation: Tools that create new images based on learned patterns from a set of existing images.
- Music Composition: AI systems that generate original music compositions in the style of known genres.
- Text Generation: AI models that write articles, stories, or even poetry based on learned language patterns.
Comparison Diagram: Traditional AI vs. Generative AI
Here’s a simple diagram that compares Traditional AI with Generative AI:

- Traditional AI is focused on understanding and predicting based on existing data. It classifies data into categories and predicts future trends.
- Generative AI is all about creating new and original content that wasn’t part of the initial data. It generates new data like images, music, and text.
Both types of AI have unique strengths and applications. Traditional AI is great for analyzing and predicting based on known data, while Generative AI excels at creating new and innovative content.
The Evolution of Generative AI: From Inception to Modern-Day Applications
Key Milestones in the Development of Generative AI: In-Depth Analysis
Generative AI has come a long way, evolving significantly over the decades. Here’s a journey through the key milestones that have shaped the field, showcasing notable contributions, technical advancements, and their impacts on modern AI systems.

1. Early Rule-Based Systems (1950s-1980s)
Overview:
In the early days, generative AI was all about rule-based systems. These systems used predefined rules to create content, operating in a very structured way. They followed strict grammatical patterns and vocabulary lists, making their output predictable but limited.
Key Contributors:
- Alan Turing (1950): Proposed the idea of machines that could mimic human responses, setting the stage for early AI concepts.
- Joseph Weizenbaum (1966): Developed ELIZA, a chatbot that simulated conversation using a fixed set of patterns.
Technical Insights:
Rule-based systems relied heavily on manual programming of rules. These systems were limited by their inability to learn from data or adapt to new patterns beyond the rules set by their developers. For example, ELIZA used pattern-matching techniques to generate responses that mimicked human conversation but lacked true understanding.
Example Code: A simple rule-based text generator might use fixed rules like:
import random # Import the random module
rules = {
"subject": ["The cat", "The dog"],
"verb": ["jumps", "runs"],
"object": ["over the fence", "through the park"]
}
def generate_sentence():
return f"{random.choice(rules['subject'])} {random.choice(rules['verb'])} {random.choice(rules['object'])}."
print(generate_sentence())
Output
The dog jumps through the park.
Impact:
These early systems laid the groundwork but were limited by their lack of flexibility and learning capability.
2. Statistical Methods (1990s-2000s)
Overview:
Statistical methods marked a shift from deterministic rule-based systems to approaches that utilized data patterns and probabilities. These methods enabled the generation of content based on statistical properties observed in training datasets.
Key Contributors:
- Claude Shannon (1948): Laid the groundwork for information theory, which later influenced statistical models in AI.
- Francois Chollet (2015): Created Keras, a high-level neural networks API, facilitating the development of statistical methods in machine learning.
Technical Insights:
Statistical models use techniques such as n-grams to predict the next word or sequence based on previous data. For instance, a text generator might use a Markov chain to predict the next word in a sequence by analyzing word frequencies in the training data.
Example Code: An n-gram model for text generation:
from collections import defaultdict
import random
def train_ngram_model(text, n):
ngrams = defaultdict(lambda: defaultdict(int))
words = text.split()
for i in range(len(words) - n + 1):
prefix = tuple(words[i:i + n - 1])
suffix = words[i + n - 1]
ngrams[prefix][suffix] += 1
return ngrams
def generate_text(model, n, length=10):
prefix = random.choice(list(model.keys()))
result = list(prefix)
for _ in range(length):
suffixes = list(model[prefix].keys())
next_word = random.choices(suffixes, weights=model[prefix].values())[0]
result.append(next_word)
prefix = tuple(result[-(n - 1):])
return ' '.join(result)
text = "the cat sat on the mat and the cat ran away"
model = train_ngram_model(text, 2)
print(generate_text(model, 2))
Output
mat and the cat sat on the mat and the mat
Impact:
Statistical methods improved content generation quality by using data patterns but still had limitations in handling complex content.
3. Introduction of Neural Networks (2000s-2010s)
Overview:
Neural networks brought a big change to generative AI. They introduced models that could understand and learn from complex patterns in data. This was a game-changer, as deep learning techniques started to make generative models much more powerful and capable.
Key Contributors:
- Geoffrey Hinton, Yann LeCun, and Yoshua Bengio (2018): Received the Turing Award for their work on deep learning, which laid the foundation for modern neural network-based generative models.
Technical Insights:
Neural networks, particularly Recurrent Neural Networks (RNNs) and Long Short-Term Memory (LSTM) networks, were used for generating sequences such as text. These models could learn and generate sequences based on long-term dependencies within the data.
Example Code: An LSTM model for text generation using Keras:
from keras.models import Sequential
from keras.layers import LSTM, Dense, Embedding
from keras.preprocessing.text import Tokenizer
from keras.preprocessing.sequence import pad_sequences
# Example code assumes preprocessing has been done
model = Sequential()
model.add(Embedding(vocab_size, embedding_dim))
model.add(LSTM(units, return_sequences=True))
model.add(LSTM(units))
model.add(Dense(vocab_size, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer='adam')
Impact:
Neural networks allowed for more sophisticated content generation, including handling complex sequences and dependencies, paving the way for even more advanced models.
4. Emergence of Generative Adversarial Networks (GANs) (2014)
Overview:
Generative Adversarial Networks (GANs), introduced by Ian Goodfellow and his team, represented a major leap in generative AI. GANs use two competing neural networks—a generator and a discriminator—to create and evaluate content.
Key Contributor:
- Ian Goodfellow (2014): Proposed GANs in a groundbreaking paper that demonstrated how adversarial training could significantly improve generative models.
Technical Insights: GANs consist of two components:
- Generator: Creates new data samples.
- Discriminator: Evaluates whether these samples are real (from the training data) or fake (generated by the generator).
The competition between these networks helps both improve over time, leading to highly realistic content.
Example Code:
A simplified GAN training loop:
# Simplified example - actual implementation involves complex architecture
for epoch in range(num_epochs):
noise = np.random.normal(0, 1, (batch_size, noise_dim))
generated_images = generator.predict(noise)
real_images = get_real_images(batch_size)
d_loss_real = discriminator.train_on_batch(real_images, real_labels)
d_loss_fake = discriminator.train_on_batch(generated_images, fake_labels)
d_loss = 0.5 * (d_loss_real + d_loss_fake)
g_loss = gan.train_on_batch(noise, real_labels)
Impact:
GANs revolutionized content generation by enabling the creation of highly realistic images, videos, and other types of media. They also introduced the concept of adversarial training, which has become a core technique in generative AI.
5. Development of Variational Autoencoders (VAEs) (2013-2015)
Overview:
Variational Autoencoders (VAEs) introduced another approach to generative modeling. VAEs focus on learning a compressed representation (latent space) of input data and then generating new data from this representation.
Key Contributors:
- Kingma and Welling (2013): Published the foundational paper on VAEs, providing a new framework for generative modeling.
Technical Insights: VAEs consist of:
- Encoder: Compresses input data into a latent space.
- Latent Space: A lower-dimensional representation of the input data.
- Decoder: Reconstructs data from the latent space.
Example Code: A simple VAE implementation in PyTorch:
class VAE(nn.Module):
def __init__(self):
super(VAE, self).__init__()
self.encoder = nn.Sequential(
nn.Linear(input_dim, hidden_dim),
nn.ReLU()
)
self.fc1 = nn.Linear(hidden_dim, z_dim)
self.fc2 = nn.Linear(hidden_dim, z_dim)
self.fc3 = nn.Linear(z_dim, input_dim)
self.decoder = nn.Sequential(
nn.Linear(z_dim, hidden_dim),
nn.ReLU(),
nn.Linear(hidden_dim, input_dim),
nn.Sigmoid()
)
def forward(self, x):
h = self.encoder(x)
z_mean, z_log_var = self.fc1(h), self.fc2(h)
z = self.reparameterize(z_mean, z_log_var)
x_recon = self.decoder(z)
return x_recon, z_mean, z_log_var
Impact: VAEs have been particularly effective in tasks involving continuous data and interpolation, offering a powerful way to generate diverse and realistic data samples.
6. Breakthroughs with Transformer Models (2017-Present)
Overview:
Transformers, introduced by Vaswani et al. in 2017, have transformed natural language processing (NLP) and generative AI. Transformers use self-attention mechanisms to handle long-range dependencies in text, enabling more coherent and contextually accurate text generation.
Key Contributors:
- Vaswani et al. (2017): Published the seminal paper “Attention is All You Need,” introducing the Transformer model architecture.
Technical Insights: Transformers use self-attention mechanisms to process and generate text. Models like GPT-3 use these mechanisms to generate coherent and contextually relevant text based on input prompts.
Example Code:
A basic Transformer block using TensorFlow:
class TransformerBlock(tf.keras.layers.Layer):
def __init__(self, embed_dim, num_heads):
super(TransformerBlock, self).__init__()
self.att = tf.keras.layers.MultiHeadAttention(
key_dim=embed_dim, num_heads=num_heads)
self.ffn = tf.keras.Sequential([
tf.keras.layers.Dense(embed_dim, activation="relu"),
tf.keras.layers.Dense(embed_dim)
])
def call(self, x):
att_output = self.att(x, x)
ffn_output = self.ffn(att_output)
return ffn_output
Impact: Transformers have revolutionized text generation, enabling models like GPT-3 to produce human-like text, complete tasks, and perform language-based applications with unprecedented accuracy and creativity.
7. Advances in Multimodal Generative Models (2020s)
Overview:
The latest advancements in generative AI include multimodal models that integrate different types of data, such as text and images, to generate content that spans multiple modalities.
Key Contributors:
- OpenAI (2021): Developed DALL·E, a model that generates images from textual descriptions, showcasing the capabilities of multimodal AI.
Technical Insights: Multimodal models combine data from various sources to create integrated content. For instance, models can generate images based on text descriptions or produce videos based on scripts.
Example Code:
A simple example of combining text and image data using a multimodal model:
# Pseudocode for multimodal model
class MultimodalModel(tf.keras.Model):
def __init__(self):
super(MultimodalModel, self).__init__()
self.text_encoder = TextEncoder()
self.image_encoder = ImageEncoder()
self.cross_modal_attention = CrossModalAttention()
def call(self, text_input, image_input):
text_features = self.text_encoder(text_input)
image_features = self.image_encoder(image_input)
combined_features = self.cross_modal_attention(text_features, image_features)
return combined_features
Impact:
Multimodal generative models represent a significant leap forward, enabling AI to create more complex and integrated content, enhancing applications in creative industries, and expanding the horizons of what generative AI can achieve.
Generative AI has come a long way with several key milestones shaping its development. We started with basic rule-based systems and gradually moved to sophisticated multimodal models. Each step has built on the last, making generative AI more powerful and strong. Today, these advancements have opened up exciting new possibilities, from creating art to solving complex technical problems.
Latest Trends in Generative AI
Generative AI is rapidly advancing, and two notable trends are emerging:
Understanding Diffusion Models
What Are Diffusion Models?

Diffusion models are a cutting-edge method for creating high-quality images. Instead of starting with a clear image, these models begin with a noisy, random image. They then work to gradually refine this image, step by step, until it becomes clear and detailed. This approach is effective in generating highly realistic images, even with complex features.
1. Concept of Diffusion Models
Diffusion models are inspired by the physical process of diffusion, where particles spread out over time. In the context of generative modeling, the diffusion process involves gradually adding noise to data until it becomes pure noise. The model then learns to reverse this process, transforming noise back into coherent data.
2. Key Components
Forward Diffusion Process
- Description: This is the process of adding noise to data progressively over multiple steps. Starting from a data sample (e.g., an image), noise is added in small increments until the data is completely random noise.
- Objective: The forward diffusion process models how data transitions into noise, providing a way to understand how data can be reconstructed from noisy inputs.
Reverse Diffusion Process
- Description: This is the process of learning to remove noise and recover the original data from the noisy input. The model learns this process by training on pairs of noisy and clean data.
- Objective: The reverse diffusion process aims to transform noise into data by iteratively refining the noisy input, eventually generating high-quality samples.
Neural Network Architecture
- Role: Neural networks, often convolutional neural networks (CNNs) or transformer-based architectures, are used to model the reverse diffusion process. They learn the mapping from noisy data to clean data and generate new samples.
- Training: The network is trained using pairs of noisy and clean data, optimizing a loss function that measures the difference between the predicted and actual clean data.
3. Training Diffusion Models
Training diffusion models involves the following steps:
- Define the Diffusion Process: Set up the forward and reverse diffusion processes, including the noise schedule (how noise is added over time).
- Prepare Training Data: Create a dataset of clean data samples and their corresponding noisy versions using the forward diffusion process.
- Train the Model: Use the noisy-clean pairs to train the neural network. The model learns to predict the clean data from noisy inputs by minimizing a loss function, typically based on mean squared error (MSE) or other relevant metrics.
- Evaluate and Refine: Evaluate the model’s performance on generating samples and refine the training process as needed.
4. Generating Samples
To generate new data using a trained diffusion model:
- Start with Noise: Begin with random noise as the initial input.
- Reverse Diffusion: Apply the reverse diffusion process iteratively using the trained neural network to transform the noise into a data sample.
- Refinement: The iterative process gradually refines the noise, resulting in a generated data sample that resembles the training data.
5. Advantages of Diffusion Models
- High Quality: Diffusion models can produce high-quality samples with fine details and fewer artifacts compared to some other generative models.
- Flexibility: They can be applied to various types of data, including images, audio, and text.
- Stable Training: Diffusion models often have more stable training compared to adversarial methods like GANs, as they do not rely on adversarial loss.
6. Applications
- Image Generation: Generating realistic and detailed images, including artwork and photography.
- Audio Synthesis: Creating high-quality audio samples for music, sound effects, and other applications.
- Text Generation: Producing coherent and contextually relevant text, though this application is less common compared to other generative models.
7. Challenges and Future Directions
- Computational Cost: Training diffusion models can be computationally intensive due to the iterative nature of the diffusion process.
- Sample Quality: While diffusion models generate high-quality samples, further research is needed to enhance their performance in certain domains.
- Scalability: Improving the scalability of diffusion models for large datasets and complex tasks remains an area of active research.
Example Code Concept
While real implementation can be complex, here’s a simplified idea of how a diffusion model might work:
import numpy as np
# Function to simulate refining an image
def refine_image(noisy_image, num_steps=10):
refined_image = noisy_image
for step in range(num_steps):
# Apply a mock refinement process (actual algorithms are more complex)
refined_image = reduce_noise(refined_image)
return refined_image
# Mock functions for demonstration
def generate_noisy_image():
# Generate a random noisy image
return np.random.rand(64, 64) # Example: 64x64 noisy image
def reduce_noise(image):
# Simple mock noise reduction (actual implementation is more sophisticated)
return image * 0.9 # Just an example to show gradual improvement
# Generate and refine a noisy image
noisy_image = generate_noisy_image()
high_quality_image = refine_image(noisy_image)
print("Refinement process completed.")
Explanation:
generate_noisy_image(): Creates a starting point with random noise.reduce_noise(image): A mock function to simulate reducing noise, improving the image in each step.refine_image(noisy_image): Applies the noise reduction multiple times to transform the noisy image into a clearer one.
Diffusion models represent a powerful approach to image generation by gradually transforming noisy inputs into detailed and realistic images. Their ability to handle complex visual details makes them a valuable tool in modern AI for creating high-quality visuals.
Understanding Cross-Modal Generation
What Is Cross-Modal Generation?

Cross-modal generation is a fascinating area of AI that involves creating content across different types of data. Essentially, it enables AI to translate information from one format into another. For example, you can give an AI a text description, and it can generate a corresponding image, or you can provide a script, and the AI can produce sound or music based on it. This capability allows for creating content that integrates multiple data types, offering richer and more dynamic experiences.
1. Concept of Cross-Modal Generation
Cross-modal generation involves translating or transforming data from one modality into another. For instance, generating an image from a text description, creating audio from text, or producing a video from a sequence of images.
2. Key Components
Modalities
- Text: Natural language descriptions or textual content.
- Image: Visual representations, including photographs, drawings, or graphics.
- Audio: Sound recordings, including speech, music, or environmental sounds.
- Video: Moving images or sequences of frames.
Transformation Models
- Text-to-Image Models: Generate images from textual descriptions. These models map the semantic content of a text description to a visual representation.
- Image-to-Text Models: Convert images into textual descriptions, often used for image captioning.
- Text-to-Audio Models: Create audio clips based on textual input. This can include text-to-speech synthesis or generating sound effects from descriptions.
- Image-to-Video Models: Produce video sequences from images or descriptions, enabling the creation of dynamic visual content from static images or textual narratives.
3. Model Architectures
Generative Adversarial Networks (GANs)
- Structure: Consists of a generator and a discriminator. In cross-modal tasks, GANs can be adapted to transform data from one modality to another by training on paired data.
- Application: Text-to-image synthesis, where the generator creates images based on textual input, and the discriminator evaluates the generated images for realism and alignment with the text.
Variational Autoencoders (VAEs)
- Structure: Encodes input data into a latent space and decodes it to reconstruct or generate new data. For cross-modal tasks, VAEs can be adapted to learn joint representations of different modalities.
- Application: Translating textual descriptions into visual content by learning a shared latent space between text and images.
Transformers
- Structure: Self-attention mechanisms and large-scale pretraining enable transformers to handle various modalities. Models like GPT-4 and DALL-E use transformers to handle text and image data, respectively.
- Application: Generating coherent text from images or creating images from textual prompts. Transformers excel in learning complex relationships between modalities.
4. Training Process
- Data Collection: Gather a dataset with paired samples from different modalities, such as images with captions or audio with transcripts.
- Preprocessing: Normalize and prepare the data for training. This may include tokenizing text, resizing images, or standardizing audio formats.
- Model Training: Train the generative model to learn the mapping between modalities. This involves minimizing a loss function that measures the discrepancy between generated outputs and target data.
- Evaluation and Fine-Tuning: Evaluate the model’s performance using metrics specific to the task, such as image quality, coherence of generated text, or accuracy of generated audio. Fine-tune the model to improve results.
5. Applications
- Text-to-Image Generation: Creating visual content from textual descriptions for use in art, design, and content creation. For example, generating illustrations based on story descriptions.
- Image Captioning: Automatically generating descriptive text for images, which is useful for accessibility and content management.
- Text-to-Speech: Converting written text into spoken audio, used in virtual assistants, audiobooks, and accessibility tools.
- Video Synthesis: Producing video content from static images or textual descriptions, applicable in animation, video creation, and multimedia storytelling.
6. Challenges and Future Directions
- Data Quality and Availability: High-quality paired datasets are essential for training effective cross-modal models. Collecting and curating such datasets can be challenging.
- Consistency and Coherence: Ensuring that generated content accurately reflects the input modality and maintains coherence across modalities is an ongoing challenge.
- Computational Resources: Training large-scale cross-modal models requires significant computational power, which can be a barrier to entry.
- Ethical Considerations: Managing the potential for misuse of cross-modal technologies, such as creating misleading or deceptive content, requires careful consideration and regulation.
Example Code Concept
Here’s a simplified example to illustrate the concept of generating an image from text:
# Pseudocode for cross-modal generation
def generate_image_from_text(text_description):
# Imagine we have a pre-trained text-to-image model
image = text_to_image_model.generate(text_description)
return image
# Example text description
text = "a sunset over the mountains"
# Generate the image based on the text
generated_image = generate_image_from_text(text)
print("Image generation completed.")
Explanation:
text_to_image_model.generate(text_description): This represents a call to a model that converts text descriptions into images. In practice, this involves complex algorithms and training on large datasets to understand how to generate accurate and visually appealing images from text.text: This is the input text description that guides the image generation.generated_image: The result is the image produced based on the provided text description.
Cross-modal generation is an exciting development in AI that allows for creating content across different data types, such as transforming text into images or generating sound from written scripts. By understanding and integrating multiple formats, AI can produce richer, more engaging content and open up new possibilities for creative and practical applications.
Generative AI Applications Across Different Industries

Generative AI has found applications across a wide range of industries, transforming how businesses operate and how creative content is produced. Here’s a look at how generative AI is making an impact in various fields, with practical examples to illustrate its applications.
1. Healthcare
Medical Imaging and Diagnostics: Generative AI is enhancing medical imaging by creating high-resolution images from lower-quality scans. For example, models can generate detailed images from MRI or CT scans, improving diagnostic accuracy. Additionally, AI can simulate how diseases progress, helping doctors understand and predict patient outcomes.
Example: Generative models can help create clearer images from blurry scans, aiding radiologists in detecting tumors or other abnormalities more accurately.
Drug Discovery: AI models can generate new molecular structures by analyzing patterns in existing drug compounds. This speeds up the discovery of new medications and helps in designing drugs that target specific diseases more effectively.
Example: Generative models like DeepChem can suggest new chemical compounds that might be effective in treating conditions such as cancer or Alzheimer’s disease.
2. Entertainment and Media
Content Creation: In the entertainment industry, generative AI is revolutionizing content creation. AI can generate scripts, create music, and even design visual effects. For instance, AI-driven tools can write movie scripts or produce background scores, reducing the time and cost associated with traditional content creation methods.
Example: AI tools like OpenAI’s GPT-3 can write engaging and coherent scripts for films or TV shows based on given prompts.
Visual Art and Design: Generative AI is also used to create art and design elements. Artists and designers use AI to generate new artworks, create digital designs, or even automate routine design tasks.
Example: AI platforms like DALL·E can generate unique artwork based on textual descriptions, allowing artists to explore new creative possibilities.
3. Finance
Fraud Detection: Generative AI helps in detecting fraudulent activities by generating patterns of normal and suspicious behavior. These models analyze transaction data to identify unusual patterns that may indicate fraud.
Example: Banks use AI to generate models of typical transaction behavior and then identify anomalies that might suggest fraudulent activity.
Algorithmic Trading: In finance, AI models generate trading strategies and simulate market scenarios. These models help traders make informed decisions by predicting market trends based on historical data.
Example: Generative AI can create trading algorithms that adapt to changing market conditions, optimizing investment strategies in real-time.
4. Retail and E-Commerce
Personalized Recommendations: AI models generate personalized product recommendations by analyzing customer behavior and preferences. These recommendations improve user experience and increase sales by suggesting products that customers are likely to buy.
Example: Online retailers use AI to generate product recommendations based on users’ browsing history and purchase patterns, enhancing shopping experiences.
Virtual Try-Ons: Generative AI enables virtual try-ons, allowing customers to visualize how clothing or accessories will look on them before making a purchase. This technology improves online shopping by offering a more interactive and personalized experience.
Example: Virtual fitting rooms powered by AI can generate realistic images of how clothes fit different body types, helping customers make better purchasing decisions.
5. Education
Adaptive Learning: Generative AI creates personalized learning experiences by generating educational content tailored to individual students’ needs. These models adapt lessons and exercises based on students’ performance and learning styles.
Example: AI-driven platforms can generate custom practice problems and explanations to help students grasp difficult concepts in subjects like mathematics or science.
Content Generation: AI can assist in generating educational materials such as textbooks, practice exams, and interactive learning modules. This speeds up the creation of educational content and makes it more accessible.
Example: AI tools can automatically generate quiz questions and educational exercises based on the curriculum, saving educators time and effort.
6. Automotive
Design and Simulation: Generative AI is used in automotive design to create innovative vehicle designs and simulate their performance. AI models generate and test various design configurations, improving efficiency and safety.
Example: Car manufacturers use AI to generate and evaluate thousands of design iterations for new vehicle models, optimizing factors like aerodynamics and fuel efficiency.
Autonomous Vehicles: AI models generate scenarios for testing and improving autonomous driving systems. These models simulate various driving conditions and potential hazards, helping in the development of safer autonomous vehicles.
Example: Generative AI creates virtual environments to test how autonomous vehicles react to different driving situations, enhancing the reliability of self-driving technology.
Conclusion
Generative AI represents a monumental leap in the realm of technology, offering possibilities that were once confined to the realm of imagination. This technology is not just a trend but a powerful tool that has the potential to reshape multiple facets of our lives and industries.
Broad Applications and Impact
Generative AI has proven its worth across a variety of fields, making significant strides in areas such as art, healthcare, content creation, and more. For instance, in the creative arts, generative AI has enabled the creation of breathtaking visuals and innovative music that push the boundaries of human creativity. Artists and designers are harnessing AI to explore new styles, generate unique designs, and enhance their creative processes in ways that were previously unimaginable.
In healthcare, generative AI is revolutionizing drug discovery and development. By generating synthetic data and simulating molecular structures, AI helps researchers accelerate the discovery of new treatments and therapies. This ability to model and test different scenarios quickly can potentially lead to breakthroughs in medical science and better patient outcomes.
The content creation industry is also seeing a transformation thanks to generative AI. Automated writing tools powered by AI can craft articles, create marketing materials, and even generate personalized content, saving time and enhancing productivity. This technology enables businesses to reach their audiences more effectively and creatively, offering new ways to engage with users.
Ethical Considerations and Responsible Use
As we forge ahead with generative AI, it’s crucial to approach its development and deployment with a sense of responsibility. The technology’s ability to create realistic content also brings with it challenges and ethical concerns. Issues such as misinformation, deepfakes, and unauthorized content generation are pressing concerns that need to be addressed.
Ensuring ethical use involves implementing robust guidelines and frameworks to prevent misuse. Developers, researchers, and policymakers must work together to create standards that promote transparency and accountability. By fostering a culture of responsible AI use, we can maximize the benefits of generative AI while minimizing potential risks.
Looking Ahead
The future of generative AI is bright and full of promise. As technology continues to advance, we can expect even more groundbreaking applications and innovations. However, it is essential that we balance technological advancement with ethical considerations. Embracing this technology with a thoughtful approach will ensure that its benefits are realized in a way that is both transformative and respectful of ethical boundaries.
In summary, generative AI is more than just a technological marvel; it is a tool that, when used wisely, can drive progress across numerous fields. By continuing to explore its potential while being mindful of ethical implications, we can harness the full power of generative AI to create a future that is both innovative and responsible.
External Resources
Here are some External Resources for “Generative AI: A Guide to Unlocking New Possibilities”:
- DeepMind
- URL: https://www.deepmind.com/research/publications
- Description: DeepMind’s research publications page offers a wealth of information on their latest research, including advancements in generative models and applications of AI in various domains.
- NVIDIA AI Research
- URL: https://www.nvidia.com/en-us/research/
- Description: NVIDIA’s AI research focuses on innovative developments in AI and machine learning, with numerous publications on generative models, including GANs and VAEs.
- Google AI
- URL: https://ai.google/research/
- Description: Google AI’s research page provides access to a wide range of papers and projects related to generative AI, showcasing their advancements and applications in real-world scenarios.
- MIT Technology Review
- URL: https://www.technologyreview.com/
- Description: MIT Technology Review covers the latest trends and breakthroughs in AI, including generative AI. Their articles and reports provide insights into how generative models are being used to solve complex problems.
FAQs
1. What is Generative AI?
Generative AI refers to artificial intelligence systems designed to create new content or data that resembles existing data. It can generate text, images, music, and more by learning patterns from large datasets.
2. How does Generative AI work?
Generative AI works by training on large amounts of data to learn patterns and relationships. Once trained, it can generate new data by applying what it has learned. For example, a model trained on images of cats can generate new, realistic images of cats.
3. What are some common types of Generative AI models?
Common types include:
- Generative Adversarial Networks (GANs): Models with two networks (a Generator and a Discriminator) that work against each other to create realistic data.
- Variational Autoencoders (VAEs): Models that learn to encode data into a compressed format and then decode it to generate new data.
- Diffusion Models: Models that generate data by gradually refining a noisy input.
- Autoregressive Models: Models that generate data sequentially, such as text or music, by predicting the next element based on previous ones.
4. What are some practical applications of Generative AI?
Generative AI can be used in various fields including:
- Art and Design: Creating new artworks, designs, or graphics.
- Healthcare: Generating synthetic medical images or drug discovery.
- Entertainment: Creating realistic characters and scenes in video games and movies.
- Text and Language: Generating coherent and contextually relevant text, such as articles or poetry.
5. How is Generative AI different from traditional AI?
Traditional AI typically focuses on analyzing and making decisions based on existing data. In contrast, Generative AI creates new data or content that mimics the original data, enabling novel and creative outputs.
6. What are some challenges associated with Generative AI?
Challenges include:
- Quality Control: Ensuring the generated content is high-quality and useful.
- Ethical Concerns: Addressing issues related to the misuse of generated content, such as deepfakes.
- Computational Resources: Generative AI models can require significant computational power and storage.
7. Can Generative AI be used for creative tasks?
Yes, Generative AI is widely used for creative tasks such as generating art, music, and writing. It can assist artists and writers by providing new ideas and inspirations.






Leave a Reply