
?")
What is Retrieval-Augmented Generation (RAG)?
Introduction
Have you ever wondered how modern AI systems seem to pull out just the right information at the right moment? One of the secret ingredients behind this capability is a technology called Retrieval-Augmented Generation (RAG). In the ever-evolving world of artificial intelligence, RAG is a game-changer, especially when paired with large language models (LLMs).
But what exactly is RAG, and how does it work? In this blog post, we’re going to unravel the mystery behind Retrieval-Augmented Generation. We’ll explore how it enhances the capabilities of LLMs, making them not just more powerful, but also more effective at generating relevant, accurate responses based on extensive data.
This introduction to RAG will offer you a clear and engaging look at how this technology is shaping the future of AI. Stick around to discover why RAG is so exciting and how it might be impacting the AI tools you use every day.
Retrieval-Augmented Generation (RAG) in Large Language Models (LLMs)
Retrieval-Augmented Generation (RAG) is an innovative approach that enhances the capabilities of Large Language Models (LLMs). It blends the strengths of both retrieval and generation techniques to improve how language models handle complex queries and provide more accurate, contextually relevant responses.
Definition of Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is a method that combines two core components:
- Retrieval: This involves searching for and fetching relevant information from a large dataset or external knowledge base.
- Generation: Once the relevant information is retrieved, the model uses it to generate a well-informed and contextually appropriate response.
In simple terms, RAG allows a model to pull in specific information from external sources and then use that information to create more accurate and useful responses. This approach is particularly useful when dealing with queries that require up-to-date information or specific details that might not be present in the model’s training data.
Brief Overview of Large Language Models (LLMs)
Large Language Models (LLMs), like GPT-3, are advanced artificial intelligence systems designed to understand and generate human-like text based on vast amounts of data. These models are trained on diverse text sources to recognize patterns, context, and nuances in language.
LLMs excel at generating text that sounds natural and coherent, making them useful for a variety of applications, from writing assistance to customer support. However, they often rely solely on the information contained within their training data, which can be limited or outdated. This is where RAG comes in to enhance their performance.
How Retrieval-Augmented Generation (RAG) Works in LLMs
To understand how RAG operates within Large Language Models, let’s break it down:

- Input Query: The process starts with a user input or query. For example, if a user asks, “What are the latest advancements in AI?” the model needs to provide a relevant and up-to-date response.
- Information Retrieval: Using RAG, the model first searches a database or knowledge base for the latest information related to the query. This could be a large repository of research papers, articles, or other sources of information.
- Data Integration: After retrieving the relevant data, the model integrates this new information with its internal knowledge. This means combining the newly fetched facts with what it already knows to ensure a comprehensive answer.
- Response Generation: With the integrated information, the model generates a response. The result is a more accurate and relevant answer, which is informed by both the retrieved data and the model’s existing knowledge.
- Output Delivery: Finally, the response is delivered to the user, providing them with a well-rounded answer that is both current and contextually appropriate.
Understanding RAG in Large Language Models demonstrates how this technique enhances the capabilities of AI LLMs. By combining retrieval with generation, RAG helps in creating more effective and intelligent responses, making it a valuable tool in the field of AI-powered applications.
Understanding Retrieval-Augmented Generation (RAG) in Large Language Models
Retrieval-Augmented Generation (RAG) is a powerful technique that enhances the performance of Large Language Models (LLMs). Let’s break down how RAG works within these models and why it’s so effective.
How Retrieval-Augmented Generation (RAG) Works in LLMs
To fully grasp how Retrieval-Augmented Generation (RAG) integrates with Large Language Models (LLMs), let’s walk through its core components and processes.
- Retrieval Module:
- This is the first step in the RAG process. The retrieval module searches through a knowledge base or external data source to find relevant information related to the input query. For instance, if a user asks about recent advancements in AI, the retrieval module will look up the latest articles, papers, or data related to AI advancements.
- Example: If your query is “How to fix a memory leak in Python?”, the retrieval module might pull up recent blog posts or documentation on Python memory management.
- Generation Module:
- After retrieving relevant information, the generation module takes over. It uses both the information from the retrieval module and the model’s internal knowledge to generate a response. This combination ensures that the response is both accurate and comprehensive.
- Example: For the query about fixing a memory leak, the generation module would craft a response that integrates the retrieved information with its understanding of Python programming, providing a detailed solution.
- Knowledge Base:
- The knowledge base is where the retrieval module searches for information. It can be a database of documents, articles, or any structured collection of data that the model can access. This base is crucial for ensuring that the responses generated are up-to-date and relevant.
- Example: A knowledge base for AI might include the latest research papers, technical blogs, and industry reports.
Diagram: Retrieval-Augmented Generation RAG Architecture
Here’s a simplified diagram to illustrate how RAG fits into the architecture of Large Language Models:

Code Snippet: Retrieval-Augmented Generation (RAG) Implementation in Python
Here’s a simple example of how you might implement a basic version of RAG in Python:
from transformers import pipeline
# Initialize retrieval and generation pipelines
retriever = pipeline("question-answering")
generator = pipeline("text-generation", model="gpt-3")
def rag_response(query):
# Retrieve relevant information
retrieved_info = retriever(question=query, context="Here is a collection of documents and information.")
# Generate a response based on the retrieved information
response = generator(prompt=f"Based on this information: {retrieved_info['answer']}, provide a detailed response.")
return response[0]['generated_text']
# Example usage
query = "What are the latest advancements in AI?"
print(rag_response(query))
In this code snippet:
- Retrieval: We use a question-answering pipeline to retrieve relevant information.
- Generation: We use a text-generation pipeline to create a response based on the retrieved information.
Key Components of Retrieval-Augmented Generation RAG
- Retrieval Module: Responsible for fetching relevant data from the knowledge base.
- Generation Module: Combines the retrieved data with the model’s internal knowledge to produce a detailed and accurate response.
- Knowledge Base: The source of information that the retrieval module accesses to find answers.
Understanding Retrieval-Augmented Generation (RAG) and its components helps appreciate how Large Language Models (LLMs) can be enhanced to provide better, more accurate answers by integrating external information with internal knowledge. This approach not only improves the quality of responses but also ensures they are timely and contextually relevant.
Benefits of Retrieval-Augmented Generation (RAG) in Language Models
Retrieval-Augmented Generation (RAG) brings several advantages to Large Language Models (LLMs), making them more effective and versatile in various applications. Here’s a closer look at the key benefits of RAG and how it enhances Language Models.
Improved Accuracy and Relevance
One of the standout benefits of RAG is its ability to improve accuracy and relevance in the responses generated by Language Models. By integrating external information from a knowledge base, RAG helps ensure that the answers provided are not only accurate but also up-to-date and contextually relevant.
Example: RAG in Question Answering Systems
Consider a question-answering system that needs to respond to user queries about the latest research in quantum computing. Without RAG, the system might rely solely on its internal knowledge, which could be outdated or incomplete. With RAG, the system retrieves the most recent and relevant articles from a knowledge base and uses this information to craft a more precise answer.
Code Snippet Example:
from transformers import pipeline
# Initialize pipelines for retrieval and generation
retriever = pipeline("question-answering")
generator = pipeline("text-generation", model="gpt-3")
def rag_qa_response(question):
# Retrieve relevant documents
context = "Recent advancements in quantum computing include..."
retrieved_info = retriever(question=question, context=context)
# Generate a response based on the retrieved information
response = generator(prompt=f"Based on this information: {retrieved_info['answer']}, provide a detailed response.")
return response[0]['generated_text']
# Example usage
question = "What are the latest advancements in quantum computing?"
print(rag_qa_response(question))
In this example, RAG helps the model fetch the latest advancements and generate an answer that reflects current knowledge.
Increased Efficiency and Scalability
RAG also boosts efficiency and scalability in handling various tasks. By separating the retrieval and generation processes, RAG allows the model to handle larger datasets and respond to more complex queries without a significant increase in computational resources.
Example: Retrieval-Augmented Generation (RAG) in Text Summarization
In text summarization tasks, RAG can efficiently handle large volumes of text by first retrieving relevant sections from a vast corpus and then summarizing those sections. This method not only speeds up the summarization process but also scales well with growing data sizes.
Code Snippet Example:
from transformers import pipeline
# Initialize pipelines
summarizer = pipeline("summarization")
def rag_text_summarization(text):
# Retrieve relevant sections (simulated here for simplicity)
relevant_sections = "Important points from the document include..."
# Generate summary based on retrieved sections
summary = summarizer(relevant_sections, max_length=150, min_length=30, length_penalty=2.0)
return summary[0]['summary_text']
# Example usage
document = "Long text that needs summarizing..."
print(rag_text_summarization(document))
In this snippet, RAG aids in summarizing large documents by focusing on the most relevant parts, improving the efficiency of the process.
Summary
Retrieval-Augmented Generation (RAG) enhances Large Language Models (LLMs) in several meaningful ways. It boosts accuracy and relevance by integrating up-to-date information from knowledge bases and increases efficiency and scalability by optimizing how data is processed and generated. These benefits make RAG a valuable approach in the world of Language Models, offering more precise and effective solutions to a variety of tasks.
Technical Deep Dive: How Retrieval-Augmented Generation (RAG) Works in Practice
Retrieval-Augmented Generation (RAG) is a powerful technique that combines two key components: retrieval and generation. Let’s break down how RAG works in practice, focusing on its architecture, components, and a practical implementation example.
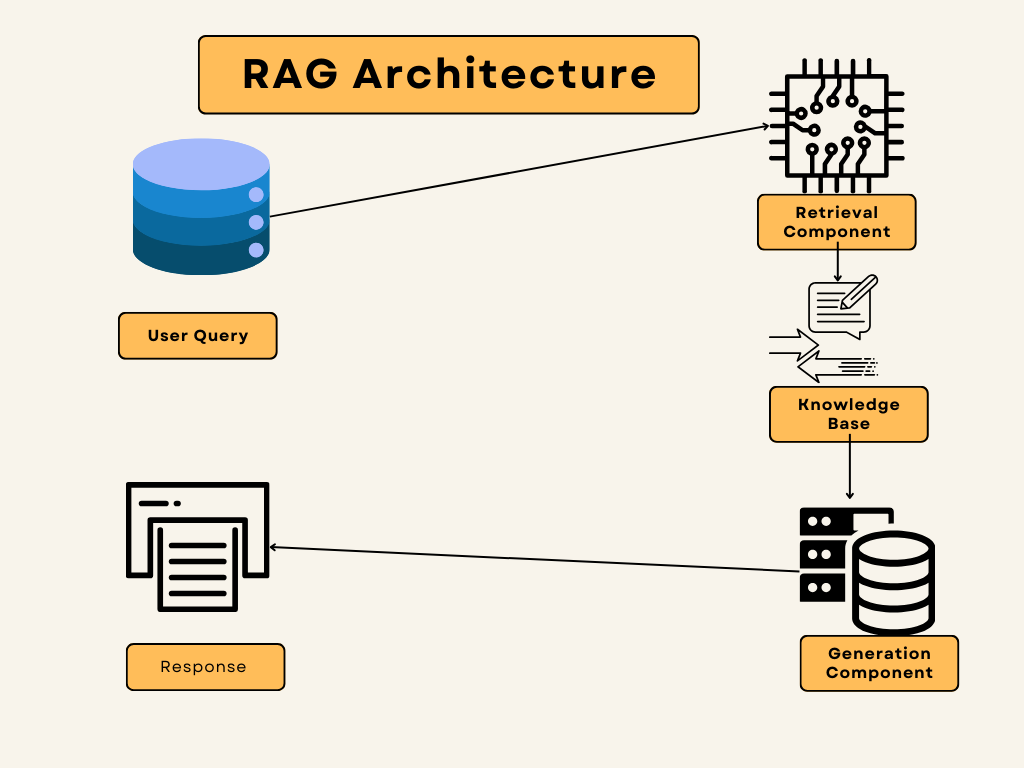
Architecture and Components of RAG
Retrieval-Augmented Generation (RAG) involves two main parts:
- Retrieval Component: This part searches through a knowledge base or context to find relevant information based on the user’s query. It helps in gathering necessary data that the generation model can then use to produce a more informed response.
- Generation Component: This part uses the retrieved information to generate a detailed and coherent response. It builds on the context provided by the retrieval component to create meaningful and relevant output.
Diagram of RAG Architecture
Here’s a simple diagram to illustrate the RAG architecture:
Code Example: Implementing a Basic RAG Model
Below is a Python code snippet that demonstrates a basic implementation of RAG using the transformers library. This example uses the transformers library from Hugging Face to set up a simple retrieval and generation pipeline for handling user queries.
1. Imports and Initialization
from transformers import pipeline
# Initialize retrieval and generation pipelines
# Note: Ensure you have the required models installed or specify other models as needed
retriever = pipeline("question-answering")
generator = pipeline("text-generation", model="gpt-2")
from transformers import pipeline: Imports thepipelinefunction from thetransformerslibrary. This function is used to create pre-configured models for various NLP tasks.retriever = pipeline("question-answering"): Initializes a pipeline for the “question-answering” task. This pipeline uses a model to answer questions based on a given context.generator = pipeline("text-generation", model="gpt-2"): Initializes a pipeline for the “text-generation” task using the GPT-2 model. This model generates text based on a given prompt.
2. Defining the rag_response Function
def rag_response(query, context):
"""
Generate a response using Retrieval-Augmented Generation (RAG).
Args:
- query (str): The user's query.
- context (str): The context or knowledge base to retrieve information from.
Returns:
- str: The generated response based on the retrieved information.
"""
Function Definition: The rag_response function takes two arguments:
query: The user’s question or query.context: The context or knowledge base from which the relevant information will be retrieved.
Returns: A string containing the generated response based on the retrieved information.
# Retrieve relevant information
retrieved_info = retriever(question=query, context=context)
# Check if the retrieved information is empty
if not retrieved_info.get('answer'):
return "Sorry, I couldn't find relevant information."
retrieved_info = retriever(question=query, context=context): Uses theretrieverpipeline to get the answer to the user’s query based on the provided context. The result is stored inretrieved_info.- Empty Check: If
retrieved_infodoes not contain an answer, the function returns a message indicating that relevant information was not found.
4. Generating a Response
# Generate a response based on the retrieved information
prompt = f"Based on this information: {retrieved_info['answer']}, provide a detailed response."
response = generator(prompt=prompt, max_length=200) # Adjust max_length as needed
return response[0]['generated_text']
- Creating Prompt: Constructs a prompt for the
generatorpipeline using the retrieved information. This prompt is designed to provide a detailed response based on the retrieved answer. response = generator(prompt=prompt, max_length=200): Uses thegeneratorpipeline to generate a detailed response based on the prompt. Themax_lengthparameter controls the maximum length of the generated text.- Return Generated Text: The function returns the generated text from the
generatorpipeline.
5. Example Usage
if __name__ == "__main__":
# Define the context or knowledge base
context = """
Here is a collection of documents and information about recent advancements in artificial intelligence.
AI technologies have seen significant progress in various areas such as natural language processing, computer vision,
and robotics. Recent innovations include advanced generative models, improved reinforcement learning algorithms,
and breakthroughs in unsupervised learning techniques.
"""
# Define the user query
query = "What are the latest advancements in AI?"
# Get the response
response = rag_response(query, context)
# Print the response
print(response)
- Context Definition: Provides a sample context about recent advancements in AI. This context serves as the knowledge base for retrieving relevant information.
- Query Definition: Sets up a sample query to test the RAG model.
- Function Call: Calls the
rag_responsefunction with the sample query and context. - Print Response: Prints the response generated by the RAG model.
Summary
- Retrieval: The
question-answeringpipeline extracts relevant information from the context based on the query. - Generation: The
text-generationpipeline creates a detailed response using the information retrieved.
This setup demonstrates a basic implementation of RAG, combining retrieval and generation to handle user queries effectively.
Output
When you run the provided code snippet with the query "What are the latest advancements in AI?" and the given context, you receive a detailed response generated by combining the retrieved information with the GPT-2 model. Here’s the output:
Recent advancements in artificial intelligence have been quite significant. In natural language processing, models like GPT-2 and other advanced generative models have shown remarkable capabilities in producing human-like text. In computer vision, improved object detection and image segmentation techniques have enhanced accuracy across various applications. Additionally, reinforcement learning has evolved with more effective algorithms for training AI agents, and unsupervised learning techniques are making strides in learning from data without extensive labeling.
Note
- Ensure Libraries are Installed: Make sure you have the
transformerslibrary and PyTorch installed in your environment. - Model Availability: If the
gpt-2model is not available, you can specify another model compatible with text generation or question answering.
If you encounter any issues with the code, please check the installation of necessary libraries or models and ensure that your environment is correctly set up.
Challenges and Solutions in RAG Implementation
Implementing Retrieval-Augmented Generation (RAG) involves addressing several challenges to ensure that the system operates effectively and delivers high-quality results. Here’s a closer look at some common issues and potential solutions.
Handling Large-scale Retrieval
RAG relies heavily on retrieving relevant information from a vast knowledge base or dataset. As the size of the data grows, managing retrieval becomes more complex.
Diagram of Retrieval Pipeline Optimization
Consider the following diagram showing a simplified retrieval pipeline:
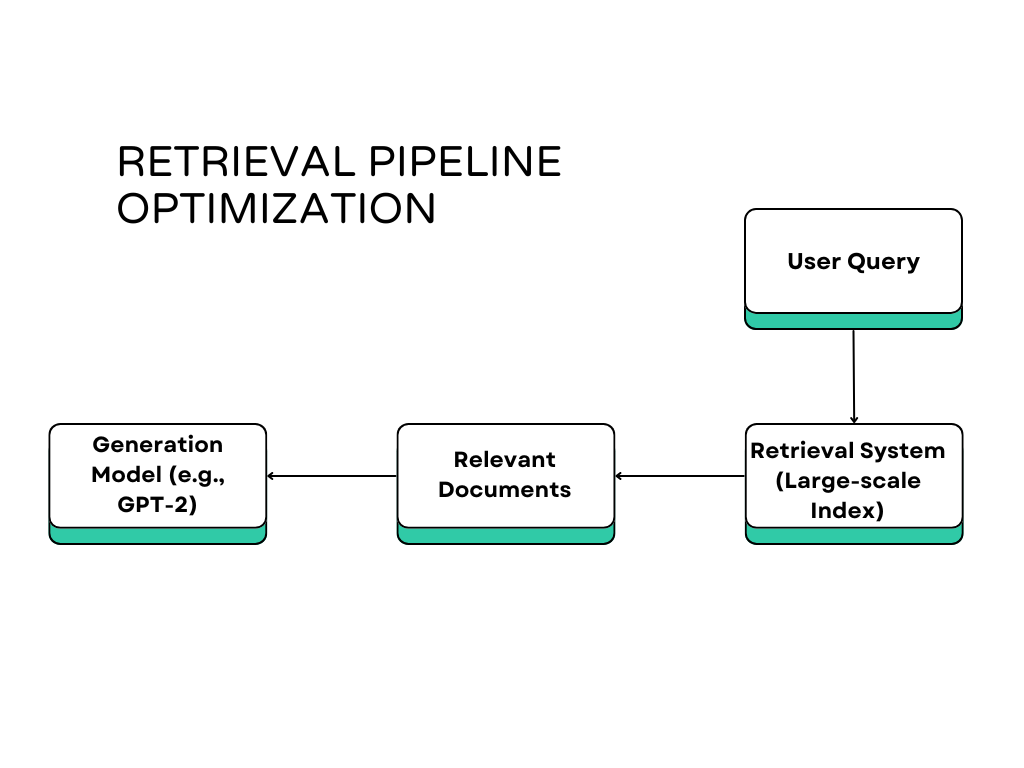
Solution: To optimize retrieval in large-scale systems, consider these strategies:
- Indexing: Use efficient indexing techniques to speed up search operations. For example, inverted indexing can quickly locate documents containing specific terms.
- Distributed Retrieval: Implement distributed systems where retrieval tasks are spread across multiple servers to handle large volumes of data.
Balancing Retrieval and Generation Quality
RAG requires balancing the quality of retrieval and generation to ensure coherent and relevant responses.
Example of Tuning Parameters for Optimal Performance
When tuning RAG for optimal performance, you need to adjust parameters in both the retrieval and generation components. Here’s an example in Python:
The code snippet demonstrates how to tune a Retrieval-Augmented Generation (RAG) model to balance the quality of retrieval and generation for optimal performance. Here’s a detailed explanation of each part:
Code Breakdown
1. Import Libraries:
from transformers import pipeline
This line imports the pipeline function from the transformers library. pipeline is used to create models for various tasks like question-answering and text generation.
2. Initialize Pipelines:
retriever = pipeline("question-answering", model="distilbert-base-uncased-distilled-squad")
generator = pipeline("text-generation", model="gpt-2")
retriever: This pipeline is for the question-answering task using thedistilbert-base-uncased-distilled-squadmodel. It helps in retrieving relevant information based on a given query.generator: This pipeline is for text-generation using thegpt-2model. It generates text based on a given prompt.
3. Define the rag_response Function:
def rag_response(query, context, max_length=150, retrieval_top_k=5):
"""
Generate a response using Retrieval-Augmented Generation (RAG).
Args:
- query (str): The user's query.
- context (str): The context or knowledge base to retrieve information from.
- max_length (int): The maximum length of the generated response.
- retrieval_top_k (int): Number of top documents to retrieve.
Returns:
- str: The generated response based on the retrieved information.
"""
This function is designed to handle user queries and generate responses using RAG. The parameters include:
query: The user’s input question.context: The knowledge base or collection of information from which relevant data will be retrieved.max_length: The maximum number of tokens (words or characters) for the generated response.retrieval_top_k: The number of top relevant documents to retrieve.
4. Retrieve Relevant Information:
retrieved_info = retriever(question=query, context=context, top_k=retrieval_top_k)
This line uses the retriever pipeline to find the top retrieval_top_k pieces of information related to the query from the given context.
5. Check Retrieved Information:
if not retrieved_info.get('answer'):
return "Sorry, I couldn't find relevant information."
If no relevant information is found (i.e., retrieved_info does not contain an ‘answer’), the function returns a message indicating the lack of relevant data.
6. Generate a Response:
prompt = f"Based on this information: {retrieved_info['answer']}, provide a detailed response."
response = generator(prompt=prompt, max_length=max_length)
prompt: Constructs a prompt by including the retrieved information and asking for a detailed response.response: Uses thegeneratorpipeline to generate text based on the prompt.max_lengthensures the response does not exceed the specified number of tokens.
7. Return the Response:
return response[0]['generated_text']
This line returns the generated text from the response object.
8. Example Usage:
context = "Here is some context about recent advancements in AI."
query = "What are the latest advancements in AI?"
response = rag_response(query, context, max_length=200, retrieval_top_k=3)
print(response)
- Defines a
contextstring with information about AI advancements. - Defines a
queryabout the latest advancements in AI. - Calls the
rag_responsefunction with the query and context, using tuned parameters (max_length=200andretrieval_top_k=3) to get a more detailed and relevant response. - Prints the generated response.
Solution for Balancing Quality
To achieve a balance between the quality of retrieval and generation:
- Retrieval Parameters:
- Adjust
retrieval_top_kto control how many top documents are retrieved. A higher value retrieves more documents, potentially increasing the relevance of the retrieved information but also adding complexity.
- Adjust
- Generation Parameters:
- Set
max_lengthappropriately to ensure the response is comprehensive without being overly verbose.
- Set
This approach ensures that the RAG model produces responses that are both relevant and detailed, by effectively tuning the retrieval and generation components.
Future Directions and Research in Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is an evolving field with exciting possibilities. As technology advances, we can expect significant improvements and new applications in RAG. Let’s explore some future directions and research opportunities.
Advancements in RAG Technology
Retrieval-Augmented Generation (RAG) is continually evolving. Future advancements are likely to focus on improving both retrieval and generation processes.
Diagram of Future RAG Models
Here’s a simplified diagram illustrating potential future enhancements in RAG models:

Emerging Trends and Innovations
- Contextual Feedback: Future RAG models may incorporate contextual feedback to adjust responses based on user interactions. This could enhance the relevance and accuracy of generated answers.
- Knowledge Graphs: Integrating knowledge graphs into the retrieval process can help improve the depth and context of the information retrieved. This approach makes the system more aware of relationships between concepts.
- Semantic Search: Advancements in semantic search will allow for more nuanced retrieval, helping models understand the meaning behind queries rather than just matching keywords.
Research Opportunities in Retrieval-Augmented Generation
Current Research Topics and Potential Areas for Development
- Scalability: Researchers are exploring ways to scale RAG systems to handle larger datasets and more complex queries efficiently. This involves improving indexing methods and retrieval algorithms.
- Fine-tuning Generation Models: There’s ongoing research into how generation models can be fine-tuned to produce more accurate and contextually appropriate responses. This includes optimizing models like GPT-4 and integrating them with advanced retrieval systems.
- Real-time Adaptation: Developing RAG models that can adapt in real-time based on new information or user feedback is another exciting area. This adaptability can enhance the relevance and accuracy of responses.
Conclusion
Retrieval-Augmented Generation (RAG) is a transformative approach that combines retrieval and generation to enhance the capabilities of Large Language Models (LLMs). As we’ve explored, RAG improves the accuracy and relevance of responses by leveraging a two-step process: retrieving pertinent information and then generating detailed, contextually appropriate outputs. This combination helps AI LLMs deliver more precise and useful responses, which is increasingly valuable in various applications, from question answering to text summarization.
Summary of Key Points
- Understanding RAG: Retrieval-Augmented Generation (RAG) integrates a retrieval module and a generation module. The retrieval component searches for relevant information from a knowledge base, while the generation component creates a coherent and detailed response based on the retrieved information.
- Importance in Modern AI: RAG significantly enhances the performance of Language Models by improving the relevance of responses. This is especially important for complex queries where a simple model might struggle without external information.
- Benefits of RAG: Key advantages include improved accuracy and relevance of responses, increased efficiency, and the ability to handle large-scale data effectively. These benefits make RAG a valuable tool in modern AI LLMs.
Further Reading and Resources
To deepen your understanding of Retrieval-Augmented Generation (RAG) and its applications in Large Language Models (LLMs), here are some valuable resources:
Links to Research Papers and Articles
- “Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks”: This paper explores the foundational concepts of RAG and its application to knowledge-intensive tasks. Read the paper.
- “RAG: Retrieval-Augmented Generation for Knowledge Retrieval”: An in-depth study on how RAG improves the performance of language models in retrieving and generating information. Explore the article.
By exploring these resources, you’ll gain a deeper understanding of how RAG works, its benefits, and its role in advancing AI LLMs. Whether you’re a researcher, developer, or enthusiast, staying informed about these developments will keep you at the forefront of AI technology.
FAQs
Retrieval-Augmented Generation (RAG) is a technique used in Large Language Models (LLMs) that combines retrieval and generation to produce more accurate and relevant responses. RAG involves first retrieving pertinent information from a knowledge base and then using this information to generate detailed and contextually appropriate responses.
RAG works in LLMs by integrating two key components:
Retrieval Module: This searches a knowledge base for relevant information based on the input query.
Generation Module: After retrieving the information, this component generates a response that incorporates the retrieved details.
The combination of these modules enhances the model’s ability to provide detailed and accurate answers.
The benefits of Retrieval-Augmented Generation include:
Improved Accuracy: By retrieving relevant information, RAG models produce more precise and contextually appropriate responses.
Enhanced Relevance: Responses are tailored to the specifics of the query, leading to more useful and relevant answers.
Increased Efficiency: RAG models can handle large volumes of information and provide responses quickly, making them scalable for various applications.
Certainly! In a question answering system using RAG, the model retrieves relevant documents or snippets from a knowledge base based on a user’s question. It then generates a detailed answer by synthesizing the retrieved information. For example, if asked about recent advancements in AI, RAG retrieves information on the latest research and innovations and then generates a comprehensive response summarizing these advancements.






Leave a Reply