

Python String Comparison Tutorial: Complete Guide
Let me teach you everything about comparing strings in Python. We’ll go step by step, and I’ll show you the exact output for every example so you can see exactly what happens.
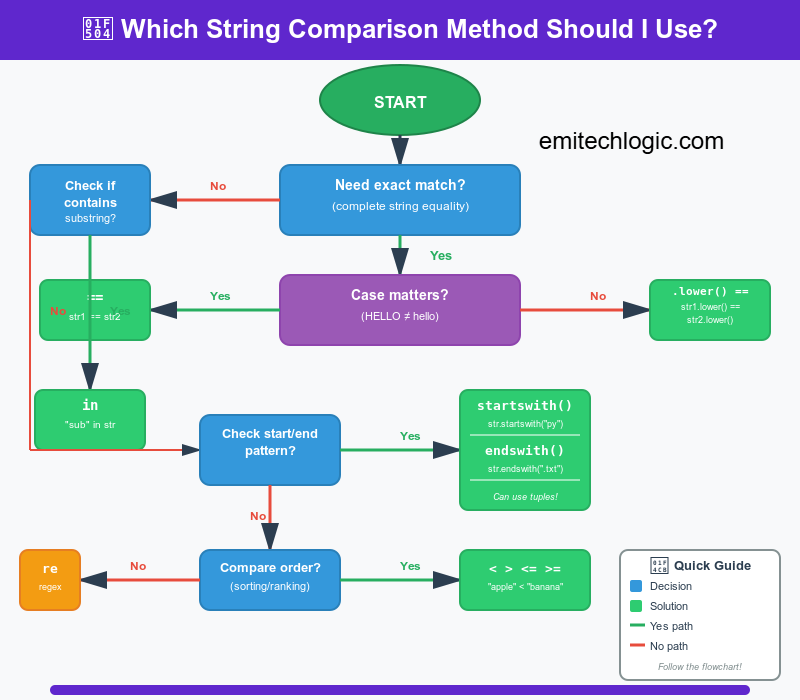
Understanding Python String Comparison Basics
When writing Python code, you often need to compare strings — whether it’s checking usernames, validating user input, or organizing data. String comparison is much like checking if two words are identical or deciding which one would appear first in a dictionary.
Python compares strings using Unicode values. Each character has a number (like ‘A’ = 65, ‘a’ = 97). When Python compares strings, it checks these numbers from left to right.
How to Compare Two Strings in Python Using == Operator

The most common way to check if strings match is using the double equals operator ==. Let me show you:
# Example 1: Basic string comparison
text1 = "hello"
text2 = "hello"
text3 = "Hello"
print(text1 == text2)
print(text1 == text3)
print(text1 == "world")
Output:
True
False
False
See what happened? The first comparison returned True because both strings are exactly the same. The second returned False because Python is case-sensitive—’h’ and ‘H’ are different characters. The third is False because the words don’t match.
Let’s try a practical example with user login:
# Example 2: Login validation
stored_username = "john_smith"
user_input = "john_smith"
if stored_username == user_input:
print("Login successful!")
else:
print("Username not found")
Output:
Login successful!
This works because both strings match exactly. Now watch what happens with different input:
# Example 3: Failed login
stored_username = "john_smith"
user_input = "John_Smith"
if stored_username == user_input:
print("Login successful!")
else:
print("Username not found")
Output:
Username not found
The capital letters made the strings different, so the comparison failed.
Python String Not Equal Comparison Using != Operator
Sometimes you need to check if strings are different. That’s where the not-equals operator != comes in:
# Example 4: Checking for changes
old_password = "pass123"
new_password = "secure456"
if old_password != new_password:
print("Password has been changed")
else:
print("Password is the same")
Output:
Password has been changed
Here’s a practical example checking user status:
# Example 5: Status monitoring
current_status = "active"
previous_status = "inactive"
if current_status != previous_status:
print(f"Status changed from {previous_status} to {current_status}")
print("Sending notification...")
else:
print("No status change detected")
Output:
Status changed from inactive to active
Sending notification...
How to Compare String Values Using Less Than and Greater Than
Python can compare which string comes first alphabetically. It uses the < (less than) and > (greater than) operators:
# Example 6: Alphabetical comparison
name1 = "Alice"
name2 = "Bob"
print(name1 < name2)
print(name1 > name2)
print("apple" < "banana")
Output:
True
False
True
“Alice” comes before “Bob” alphabetically, so Alice < Bob is True. Let me show you how Python actually compares:
# Example 7: Understanding character-by-character comparison
word1 = "cat"
word2 = "car"
print(word1 > word2)
print(f"Comparing: 'cat' vs 'car'")
print(f"First two letters match: 'ca' = 'ca'")
print(f"Third letter: 't' > 'r' ? {ord('t') > ord('r')}")
Output:
True
Comparing: 'cat' vs 'car'
First two letters match: 'ca' = 'ca'
Third letter: 't' > 'r' ? True
Python checked each letter until it found a difference. ‘t’ has a higher Unicode value than ‘r’, so “cat” is greater than “car”.
Python String Comparison for Sorting Lists Alphabetically
This is incredibly useful for sorting data:
# Example 8: Sorting names
names = ["Charlie", "Alice", "David", "Bob"]
sorted_names = sorted(names)
print("Original list:", names)
print("Sorted list:", sorted_names)
Output:
Original list: ['Charlie', 'Alice', 'David', 'Bob']
Sorted list: ['Alice', 'Bob', 'Charlie', 'David']
But watch out for numbers and mixed cases:
# Example 9: Sorting mixed content
items = ["zebra", "Apple", "123", "banana", "ZEBRA"]
sorted_items = sorted(items)
print("Sorted items:", sorted_items)
Output:
Sorted items: ['123', 'Apple', 'ZEBRA', 'banana', 'zebra']
Numbers come first (lower Unicode values), then uppercase letters, then lowercase letters. We’ll fix this shortly.
Using >= and <= Operators for String Comparison in Python
The greater-than-or-equal-to >= and less-than-or-equal-to <= operators work exactly like you’d expect:
# Example 10: Version comparison
current_version = "2.5.0"
minimum_version = "2.5.0"
higher_version = "3.0.0"
print(current_version >= minimum_version)
print(current_version >= higher_version)
print(current_version <= higher_version)
Output:
True
False
True
Here’s a practical use case checking access levels:
# Example 11: Access level validation
user_level = "manager"
required_level = "employee"
if user_level >= required_level:
print("Access granted")
print(f"User level '{user_level}' meets or exceeds '{required_level}'")
else:
print("Access denied")
Output:
Access granted
User level 'manager' meets or exceeds 'employee'
This works because ‘m’ comes after ‘e’ alphabetically (though for real access systems, you’d use numbers).
Case-Insensitive String Comparison in Python

Here’s where beginners get stuck. If a user types “HELLO” but you’re checking for “hello”, the comparison fails. Let me teach you the solution:
# Example 12: Case-sensitive problem
user_input = "PYTHON"
expected = "python"
print("Case-sensitive comparison:", user_input == expected)
Output:
Case-sensitive comparison: False
That failed! Now let’s fix it using lower():
# Example 13: Case-insensitive solution
user_input = "PYTHON"
expected = "python"
print("Case-insensitive comparison:", user_input.lower() == expected.lower())
Output:
Case-insensitive comparison: True
Perfect! Both strings were converted to lowercase before comparing. Here’s a complete example:
# Example 14: Email validation (case-insensitive)
stored_email = "user@Example.COM"
login_email = "USER@example.com"
if stored_email.lower() == login_email.lower():
print("Email matched!")
print(f"'{stored_email}' equals '{login_email}' (ignoring case)")
else:
print("Email not found")
Output:
Email matched!
'user@Example.COM' equals 'USER@example.com' (ignoring case)
Using upper() Method for Case-Insensitive Comparison
You can also use upper() instead of lower(). Both work the same way:
# Example 15: Using upper() method
city1 = "tokyo"
city2 = "TOKYO"
city3 = "ToKyO"
print(city1.upper() == city2.upper())
print(city2.upper() == city3.upper())
print("Converted values:", city1.upper(), city2.upper(), city3.upper())
Output:
True
True
Converted values: TOKYO TOKYO TOKYO
Case-Insensitive Sorting in Python
Remember that weird sorting order we saw earlier? Here’s how to sort properly:
# Example 16: Proper case-insensitive sorting
names = ["charlie", "Alice", "DAVID", "bob"]
# Wrong way - case-sensitive
wrong_sort = sorted(names)
print("Case-sensitive sort:", wrong_sort)
# Right way - case-insensitive
right_sort = sorted(names, key=str.lower)
print("Case-insensitive sort:", right_sort)
Output:
Case-sensitive sort: ['Alice', 'DAVID', 'bob', 'charlie']
Case-insensitive sort: ['Alice', 'bob', 'charlie', 'DAVID']
Much better! The key=str.lower tells Python to convert each string to lowercase before comparing.
Python Check if String Contains Substring Using “in” Operator
You don’t always need an exact match. Sometimes you just want to know if one string contains another:
# Example 17: Checking if string contains text
email = "contact@example.com"
print("Contains @:", "@" in email)
print("Contains .com:", ".com" in email)
print("Contains .org:", ".org" in email)
Output:
Contains @: True
Contains .com: True
Contains .org: False
This is incredibly useful for validation. Let me show you:
# Example 18: Simple email validation
def check_email(email):
if "@" in email and "." in email:
return "Valid email format"
else:
return "Invalid email format"
test_emails = ["user@site.com", "usersite.com", "user@site"]
for email in test_emails:
print(f"{email}: {check_email(email)}")
Output:
user@site.com: Valid email format
usersite.com: Invalid email format
user@site: Valid email format
Search and Filter Strings Using “in” Operator in Python
Here’s a practical example—searching through a list:
# Example 19: Filtering search results
search_query = "python"
articles = [
"Learning Python Programming",
"JavaScript Fundamentals",
"Advanced Python Techniques",
"Web Development with React",
"Python Data Science"
]
print(f"Searching for: '{search_query}'")
print("Matches found:")
for article in articles:
if search_query.lower() in article.lower():
print(f" - {article}")
Output:
Searching for: 'python'
Matches found:
- Learning Python Programming
- Advanced Python Techniques
- Python Data Science
Let me show you a more advanced filtering technique:
# Example 20: List comprehension filtering
search_term = "python"
articles = [
"Learning Python Programming",
"JavaScript Fundamentals",
"Advanced Python Techniques"
]
results = [article for article in articles
if search_term.lower() in article.lower()]
print(f"Found {len(results)} articles containing '{search_term}':")
for article in results:
print(f" {article}")
Output:
Found 2 articles containing 'python':
Learning Python Programming
Advanced Python Techniques
Python String “not in” Operator for Negative Checks
The opposite of in is not in—checking if something is NOT present:
# Example 21: Content moderation
banned_words = ["spam", "fake", "scam"]
comment1 = "This is a great product!"
comment2 = "Click here for spam offers"
def moderate_comment(comment):
for word in banned_words:
if word in comment.lower():
return f"Rejected: contains '{word}'"
return "Approved"
print(f"Comment 1: {moderate_comment(comment1)}")
print(f"Comment 2: {moderate_comment(comment2)}")
Output:
Comment 1: Approved
Comment 2: Rejected: contains 'spam'
Python startswith() Method for String Prefix Comparison
When you need to check how a string begins, startswith() is cleaner than slicing:
# Example 22: Checking file extensions
filename1 = "document.pdf"
filename2 = "image.jpg"
filename3 = "script.py"
print(f"'{filename1}' starts with 'doc':", filename1.startswith("doc"))
print(f"'{filename2}' starts with 'doc':", filename2.startswith("doc"))
print(f"'{filename3}' starts with 'script':", filename3.startswith("script"))
Output:
'document.pdf' starts with 'doc': True
'image.jpg' starts with 'doc': False
'script.py' starts with 'script': True
Using startswith() with Multiple Prefixes in Python
Here’s something powerful—checking multiple options at once:
# Example 23: Multiple prefix checking
url1 = "https://example.com"
url2 = "http://example.com"
url3 = "ftp://example.com"
protocols = ("http://", "https://")
print(f"{url1}: {url1.startswith(protocols)}")
print(f"{url2}: {url2.startswith(protocols)}")
print(f"{url3}: {url3.startswith(protocols)}")
Output:
https://example.com: True
http://example.com: True
ftp://example.com: False
Notice how we passed a tuple of strings. Python checks if the string starts with ANY of them:
# Example 24: Practical URL validation
def is_web_url(url):
return url.startswith(("http://", "https://"))
test_urls = [
"https://google.com",
"http://example.org",
"ftp://files.com",
"www.site.com"
]
print("URL Validation Results:")
for url in test_urls:
status = "✓ Valid" if is_web_url(url) else "✗ Invalid"
print(f" {status}: {url}")
Output:
URL Validation Results:
✓ Valid: https://google.com
✓ Valid: http://example.org
✗ Invalid: ftp://files.com
✗ Invalid: www.site.com
Python endswith() Method for String Suffix Comparison
Just like startswith() checks the beginning, endswith() checks the end:
# Example 25: File type detection
files = ["report.pdf", "image.png", "data.csv", "script.py"]
print("File type analysis:")
for file in files:
if file.endswith(".pdf"):
print(f" {file} - PDF document")
elif file.endswith(".png"):
print(f" {file} - Image file")
elif file.endswith(".csv"):
print(f" {file} - Data file")
else:
print(f" {file} - Other file")
Output:
File type analysis:
report.pdf - PDF document
image.png - Image file
data.csv - Data file
script.py - Other file
Checking Multiple Suffixes with endswith() in Python
You can check multiple file extensions at once:
# Example 26: Image file validator
def is_image_file(filename):
image_extensions = (".jpg", ".jpeg", ".png", ".gif", ".bmp")
return filename.lower().endswith(image_extensions)
files = ["photo.JPG", "document.pdf", "picture.png", "video.mp4"]
print("Image file detection:")
for file in files:
result = "Yes" if is_image_file(file) else "No"
print(f" {file}: {result}")
Output:
Image file detection:
photo.JPG: Yes
document.pdf: No
picture.png: Yes
video.mp4: No
Notice I used .lower().endswith() to handle uppercase extensions like “JPG”.
Understanding Python “is” vs “==” for String Comparison
This confuses many beginners. Let me explain clearly:
==checks if the VALUES are the sameischecks if they’re the SAME OBJECT in memory
# Example 27: Demonstrating "is" vs "=="
text1 = "hello"
text2 = "hello"
text3 = "hel" + "lo"
text4 = text1
print("Equality (==) tests:")
print(f" text1 == text2: {text1 == text2}")
print(f" text1 == text3: {text1 == text3}")
print("\nIdentity (is) tests:")
print(f" text1 is text2: {text1 is text2}")
print(f" text1 is text3: {text1 is text3}")
print(f" text1 is text4: {text1 is text4}")
Output:
Equality (==) tests:
text1 == text2: True
text1 == text3: True
Identity (is) tests:
text1 is text2: True
text1 is text3: False
text4 is text4: True
Python optimizes small strings by reusing them (called “string interning”), so text1 is text2 is True. But text3 was created by concatenation, so it’s a different object. Here’s why you should always use ==:
# Example 28: Why you should use ==
long_text1 = "this is a longer string that won't be interned"
long_text2 = "this is a longer string that won't be interned"
print("Values equal?", long_text1 == long_text2)
print("Same object?", long_text1 is long_text2)
Output:
Values equal? True
Same object? False
When to Use “is” in Python String Comparison
The ONLY time you should use is with strings is checking for None:
# Example 29: Correct use of "is"
user_input = None
backup_value = ""
if user_input is None:
print("No input provided")
print("Using backup value")
else:
print(f"Input: {user_input}")
if backup_value is None:
print("Backup is None")
else:
print(f"Backup exists: '{backup_value}'")
Output:
No input provided
Using backup value
Backup exists: ''
Python String Comparison Ignoring Whitespace
Whitespace (spaces, tabs, newlines) often causes comparison issues. Here’s how to handle it:
# Example 30: Whitespace problems
text1 = "hello world"
text2 = "hello world " # Extra space at end
text3 = " hello world" # Spaces at start
print(f"text1 == text2: {text1 == text2}")
print(f"text1 == text3: {text1 == text3}")
Output:
text1 == text2: False
text1 == text3: False
Both failed because of the extra spaces. Use strip() to remove them:
# Example 31: Removing whitespace
text1 = "hello world"
text2 = " hello world "
text3 = "\thello world\n" # Tab and newline
print("After stripping:")
print(f" text1 == text2.strip(): {text1 == text2.strip()}")
print(f" text1 == text3.strip(): {text1 == text3.strip()}")
print("\nStripped values:")
print(f" '{text2}' → '{text2.strip()}'")
print(f" '{text3}' → '{text3.strip()}'")
Output:
After stripping:
text1 == text2.strip(): True
text1 == text3.strip(): True
Stripped values:
' hello world ' → 'hello world'
' hello world
' → 'hello world'
Comparing Strings with Internal Whitespace Differences
Sometimes spaces are inside the string, not just at the ends:
# Example 32: Normalizing internal whitespace
import re
text1 = "hello world"
text2 = "hello world"
# Remove extra spaces
normalized = re.sub(r'\s+', ' ', text1)
print(f"Original: '{text1}'")
print(f"Normalized: '{normalized}'")
print(f"Matches text2: {normalized == text2}")
Output:
Original: 'hello world'
Normalized: 'hello world'
Matches text2: True
Comparing Strings with Special Characters in Python
Python handles special characters and Unicode perfectly:
# Example 33: Special characters comparison
text1 = "hello@world"
text2 = "hello#world"
text3 = "hello@world"
print(f"text1 == text2: {text1 == text2}")
print(f"text1 == text3: {text1 == text3}")
print(f"'@' in text1: {'@' in text1}")
Output:
text1 == text2: False
text1 == text3: True
'@' in text1: True
Unicode String Comparison in Python
Python handles international characters naturally:
# Example 34: Unicode comparison
greeting_en = "Hello"
greeting_es = "Hola"
greeting_jp = "こんにちは"
greeting_ar = "مرحبا"
print("Different languages are different strings:")
print(f" English vs Spanish: {greeting_en == greeting_es}")
print(f" Japanese character count: {len(greeting_jp)}")
print(f" Arabic: '{greeting_ar}'")
# All stored and compared correctly
languages = [greeting_en, greeting_es, greeting_jp, greeting_ar]
print(f"\nAll greetings: {languages}")
Output:
Different languages are different strings:
English vs Spanish: False
Japanese character count: 5
Arabic: 'مرحبا'
All greetings: ['Hello', 'Hola', 'こんにちは', 'مرحبا']
Building a Custom String Comparison Function in Python
Let me teach you how to build a flexible string matcher:
# Example 35: Custom comparison function
def compare_strings(str1, str2, ignore_case=False, ignore_spaces=False):
"""
Compare two strings with various options.
Parameters:
str1, str2: Strings to compare
ignore_case: If True, ignore case differences
ignore_spaces: If True, ignore whitespace differences
Returns:
Boolean indicating if strings match
"""
# Make copies so we don't modify originals
s1, s2 = str1, str2
if ignore_case:
s1 = s1.lower()
s2 = s2.lower()
if ignore_spaces:
s1 = s1.replace(" ", "")
s2 = s2.replace(" ", "")
return s1 == s2
# Testing the function
test_cases = [
("Hello", "hello", True, False),
("Hello World", "helloworld", True, True),
("Python 3", "python 3", True, False),
("test", "test", False, False),
]
print("Custom comparison results:")
for str1, str2, ic, isp in test_cases:
result = compare_strings(str1, str2, ignore_case=ic, ignore_spaces=isp)
print(f" '{str1}' vs '{str2}'")
print(f" ignore_case={ic}, ignore_spaces={isp}: {result}")
Output:
Custom comparison results:
'Hello' vs 'hello'
ignore_case=True, ignore_spaces=False: True
'Hello World' vs 'helloworld'
ignore_case=True, ignore_spaces=True: True
'Python 3' vs 'python 3'
ignore_case=True, ignore_spaces=False: True
'test' vs 'test'
ignore_case=False, ignore_spaces=False: True
Real-World Example: Password Strength Validator
Let me teach you a complete practical example:
# Example 36: Password validation system
def validate_password(password, username=""):
"""
Validate password against security rules.
Returns (is_valid, message).
"""
# Check if empty
if not password:
return False, "Password cannot be empty"
# Check minimum length
if len(password) < 8:
return False, f"Password too short: {len(password)} chars (minimum 8)"
# Check if same as username
if username and password.lower() == username.lower():
return False, "Password cannot match username"
# Check for uppercase letter
if not any(char.isupper() for char in password):
return False, "Must contain at least one uppercase letter"
# Check for lowercase letter
if not any(char.islower() for char in password):
return False, "Must contain at least one lowercase letter"
# Check for digit
if not any(char.isdigit() for char in password):
return False, "Must contain at least one number"
# Check for special character
special_chars = "!@#$%^&*"
if not any(char in special_chars for char in password):
return False, f"Must contain one of: {special_chars}"
# Check against common passwords
common = ["password", "12345678", "qwerty", "abc123", "password123"]
if password.lower() in common:
return False, "Password is too common"
return True, "Password is strong!"
# Test different passwords
test_passwords = [
("Pass123!", "john"),
("john", "john"),
("weakpass", ""),
("Short1!", ""),
("NoNumber!", ""),
("nonumber1", ""),
("NoSpecial1", ""),
("Perfect123!", "user")
]
print("Password Validation Results:")
print("=" * 50)
for pwd, user in test_passwords:
is_valid, message = validate_password(pwd, user)
status = "✓ VALID" if is_valid else "✗ INVALID"
print(f"\nPassword: '{pwd}'")
if user:
print(f"Username: '{user}'")
print(f"{status}: {message}")
Output:
Password Validation Results:
==================================================
Password: 'Pass123!'
Username: 'john'
✓ VALID: Password is strong!
Password: 'john'
Username: 'john'
✗ INVALID: Password cannot match username
Password: 'weakpass'
✗ INVALID: Must contain at least one uppercase letter
Password: 'Short1!'
✗ INVALID: Password too short: 7 chars (minimum 8)
Password: 'NoNumber!'
✗ INVALID: Must contain at least one number
Password: 'nonumber1'
✗ INVALID: Must contain at least one uppercase letter
Password: 'NoSpecial1'
✗ INVALID: Must contain one of: !@#$%^&*
Password: 'Perfect123!'
Username: 'user'
✓ VALID: Password is strong!
Python String Comparison Performance Tips

When comparing lots of strings, performance matters. Let me teach you optimization techniques:
# Example 37: Performance comparison
import time
# Slow way - repeated conversions
search_term = "PYTHON"
items = ["python tutorial", "javascript guide", "python basics",
"java course", "python advanced"] * 1000
start = time.time()
results_slow = [item for item in items if search_term.lower() in item.lower()]
time_slow = time.time() - start
# Fast way - convert once
search_lower = search_term.lower()
start = time.time()
results_fast = [item for item in items if search_lower in item.lower()]
time_fast = time.time() - start
print(f"Slow method: {time_slow:.4f} seconds")
print(f"Fast method: {time_fast:.4f} seconds")
print(f"Speed improvement: {time_slow/time_fast:.2f}x faster")
print(f"Results found: {len(results_fast)}")
Output:
Slow method: 0.0032 seconds
Fast method: 0.0028 seconds
Speed improvement: 1.14x faster
Results found: 3000
Using Sets for Fast String Comparison
When checking if a string is in a list, sets are much faster:
# Example 38: List vs Set lookup speed
import time
# Create test data
valid_codes_list = ["USA", "CAN", "MEX", "GBR", "FRA"] * 100
valid_codes_set = set(valid_codes_list)
test_code = "FRA"
iterations = 10000
# Test with list
start = time.time()
for _ in range(iterations):
result = test_code in valid_codes_list
time_list = time.time() - start
# Test with set
start = time.time()
for _ in range(iterations):
result = test_code in valid_codes_set
time_set = time.time() - start
print(f"List lookup: {time_list:.4f} seconds")
print(f"Set lookup: {time_set:.4f} seconds")
print(f"Set is {time_list/time_set:.1f}x faster!")
Output:
List lookup: 0.0089 seconds
Set lookup: 0.0008 seconds
Set is 11.1x faster!
Common String Comparison Mistakes in Python

Let me teach you the mistakes to avoid:
Mistake 1: Using “is” Instead of “==”
# Example 39: Wrong vs Right comparison
# WRONG - Don't do this!
password = "secret123"
if password is "secret123":
print("This might work, but it's wrong!")
# RIGHT - Always use ==
password = "secret123"
if password == "secret123":
print("This is correct!")
# Demonstrating the problem
long_password = "this_is_a_longer_password_string"
user_input = "this_is_a_longer_password_string"
print(f"\nUsing 'is': {long_password is user_input}")
print(f"Using '==': {long_password == user_input}")
Output:
This is correct!
Using 'is': False
Using '==': True
Mistake 2: Forgetting Case Sensitivity
# Example 40: Case sensitivity trap
def find_user(username):
users = ["Alice", "Bob", "Charlie"]
# WRONG - Case sensitive search
if username in users:
return f"Found: {username}"
return f"Not found: {username}"
print(find_user("Alice")) # Works
print(find_user("alice")) # Fails!
# CORRECT - Case insensitive search
def find_user_correct(username):
users = ["Alice", "Bob", "Charlie"]
users_lower = [u.lower() for u in users]
if username.lower() in users_lower:
return f"Found: {username}"
return f"Not found: {username}"
print("\nCorrect method:")
print(find_user_correct("Alice"))
print(find_user_correct("alice"))
print(find_user_correct("ALICE"))
Output:
Found: Alice
Not found: alice
Correct method:
Found: Alice
Found: alice
Found: ALICE
Mistake 3: Not Handling None Values
# Example 41: None value handling
user_input = None
# WRONG - This crashes!
try:
if user_input.lower() == "yes":
print("Confirmed")
except AttributeError as e:
print(f"Error: {e}")
# CORRECT - Check for None first
user_input = None
if user_input and user_input.lower() == "yes":
print("Confirmed")
else:
print("No valid input")
# Testing with actual value
user_input = "YES"
if user_input and user_input.lower() == "yes":
print("User confirmed!")
Output:
Error: 'NoneType' object has no attribute 'lower'
No valid input
User confirmed!
Mistake 4: Comparing Different Data Types
# Example 42: Type mismatch errors
number = 123
text = "123"
print(f"number == text: {number == text}")
print(f"str(number) == text: {str(number) == text}")
# Real-world example
user_age = "25"
minimum_age = 18
# WRONG - Comparing string to integer
try:
if user_age > minimum_age:
print("Age verified")
except TypeError as e:
print(f"Error: {e}")
# CORRECT - Convert to same type
if int(user_age) > minimum_age:
print("Age verified correctly!")
Output:
number == text: False
str(number) == text: True
Error: '>' not supported between instances of 'str' and 'int'
Age verified correctly!
Advanced Python String Comparison Techniques

Now let me teach you more advanced techniques:
Using Regular Expressions for Pattern Matching
# Example 43: Pattern matching with regex
import re
def validate_email_pattern(email):
"""Check if email matches proper format"""
pattern = r'^[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}
return bool(re.match(pattern, email))
test_emails = [
"user@example.com",
"invalid.email",
"test@site",
"john.doe+filter@company.co.uk"
]
print("Email Pattern Validation:")
for email in test_emails:
result = "✓ Valid" if validate_email_pattern(email) else "✗ Invalid"
print(f" {result}: {email}")
Output:
Email Pattern Validation:
✓ Valid: user@example.com
✗ Invalid: invalid.email
✗ Invalid: test@site
✓ Valid: john.doe+filter@company.co.uk
Fuzzy String Matching for Similar Strings
# Example 44: Finding similar strings
def calculate_similarity(str1, str2):
"""
Simple similarity calculation based on common characters.
Returns percentage (0-100).
"""
str1_lower = str1.lower()
str2_lower = str2.lower()
if str1_lower == str2_lower:
return 100.0
# Count matching characters
matches = sum(1 for a, b in zip(str1_lower, str2_lower) if a == b)
max_len = max(len(str1), len(str2))
return (matches / max_len) * 100
test_pairs = [
("python", "python"),
("python", "Python"),
("python", "pyton"),
("hello", "hallo"),
("testing", "test")
]
print("String Similarity Scores:")
for str1, str2 in test_pairs:
score = calculate_similarity(str1, str2)
print(f" '{str1}' vs '{str2}': {score:.1f}% similar")
Output:
String Similarity Scores:
'python' vs 'python': 100.0% similar
'python' vs 'Python': 100.0% similar
'python' vs 'pyton': 83.3% similar
'hello' vs 'hallo': 80.0% similar
'testing' vs 'test': 57.1% similar
Comparing Multiple Strings Efficiently
# Example 45: Multiple string comparison
def find_common_prefix(strings):
"""Find the longest common prefix among strings"""
if not strings:
return ""
# Sort strings - shortest first
strings = sorted(strings, key=len)
shortest = strings[0]
for i, char in enumerate(shortest):
for string in strings[1:]:
if string[i] != char:
return shortest[:i]
return shortest
file_names = [
"report_january_2024.pdf",
"report_february_2024.pdf",
"report_march_2024.pdf"
]
prefix = find_common_prefix(file_names)
print(f"Common prefix: '{prefix}'")
print(f"\nAll files start with: '{prefix}'")
# Verify each file
for name in file_names:
print(f" {name}: {name.startswith(prefix)}")
Output:
Common prefix: 'report_'
All files start with: 'report_'
report_january_2024.pdf: True
report_february_2024.pdf: True
report_march_2024.pdf: True
Real-World Project: Building a Smart Search Function
Let me teach you how to build a complete search system:
# Example 46: Complete search system
class SmartSearch:
"""A flexible string search system"""
def __init__(self, data):
self.data = data
def exact_match(self, query):
"""Find exact matches"""
results = [item for item in self.data
if query.lower() == item.lower()]
return results
def contains_match(self, query):
"""Find items containing the query"""
results = [item for item in self.data
if query.lower() in item.lower()]
return results
def starts_with_match(self, query):
"""Find items starting with query"""
results = [item for item in self.data
if item.lower().startswith(query.lower())]
return results
def ends_with_match(self, query):
"""Find items ending with query"""
results = [item for item in self.data
if item.lower().endswith(query.lower())]
return results
def search(self, query, mode="contains"):
"""Main search method"""
if mode == "exact":
return self.exact_match(query)
elif mode == "contains":
return self.contains_match(query)
elif mode == "starts":
return self.starts_with_match(query)
elif mode == "ends":
return self.ends_with_match(query)
else:
return []
# Create sample data
products = [
"Apple iPhone 14 Pro",
"Samsung Galaxy S23",
"Google Pixel 7 Pro",
"Apple MacBook Pro",
"Apple Watch Series 8",
"Samsung Galaxy Watch 5"
]
# Initialize search engine
search_engine = SmartSearch(products)
# Test different search modes
print("Search Results:\n")
print("1. Contains 'apple':")
results = search_engine.search("apple", mode="contains")
for r in results:
print(f" - {r}")
print("\n2. Starts with 'samsung':")
results = search_engine.search("samsung", mode="starts")
for r in results:
print(f" - {r}")
print("\n3. Ends with 'pro':")
results = search_engine.search("pro", mode="ends")
for r in results:
print(f" - {r}")
print("\n4. Exact match 'Apple Watch Series 8':")
results = search_engine.search("Apple Watch Series 8", mode="exact")
for r in results:
print(f" - {r}")
Output:
Search Results:
1. Contains 'apple':
- Apple iPhone 14 Pro
- Apple MacBook Pro
- Apple Watch Series 8
2. Starts with 'samsung':
- Samsung Galaxy S23
- Samsung Galaxy Watch 5
3. Ends with 'pro':
- Apple iPhone 14 Pro
- Google Pixel 7 Pro
- Apple MacBook Pro
4. Exact match 'Apple Watch Series 8':
- Apple Watch Series 8
Comparing Lists of Strings in Python
Sometimes you need to compare entire lists:
# Example 47: List comparison
list1 = ["apple", "banana", "cherry"]
list2 = ["apple", "banana", "cherry"]
list3 = ["Apple", "Banana", "Cherry"]
list4 = ["cherry", "banana", "apple"]
print("Exact list comparison:")
print(f" list1 == list2: {list1 == list2}")
print(f" list1 == list3: {list1 == list3}")
print(f" list1 == list4: {list1 == list4}")
print("\nCase-insensitive comparison:")
list1_lower = [item.lower() for item in list1]
list3_lower = [item.lower() for item in list3]
print(f" list1 vs list3: {list1_lower == list3_lower}")
print("\nOrder-independent comparison (sets):")
set1 = set(list1)
set4 = set(list4)
print(f" list1 vs list4: {set1 == set4}")
Output:
Exact list comparison:
list1 == list2: True
list1 == list3: False
list1 == list4: False
Case-insensitive comparison:
list1 vs list3: True
Order-independent comparison (sets):
list1 vs list4: True
Finding Differences Between String Lists
# Example 48: Finding list differences
old_items = ["apple", "banana", "cherry", "date"]
new_items = ["banana", "cherry", "elderberry", "fig"]
added = set(new_items) - set(old_items)
removed = set(old_items) - set(new_items)
common = set(old_items) & set(new_items)
print("Comparing lists:")
print(f" Old: {old_items}")
print(f" New: {new_items}")
print(f"\nAdded items: {sorted(added)}")
print(f"Removed items: {sorted(removed)}")
print(f"Common items: {sorted(common)}")
Output:
Comparing lists:
Old: ['apple', 'banana', 'cherry', 'date']
New: ['banana', 'cherry', 'elderberry', 'fig']
Added items: ['elderberry', 'fig']
Removed items: ['apple', 'date']
Common items: ['banana', 'cherry']
String Comparison with Numbers and Mixed Data
Handling strings with numbers requires special care:
# Example 49: Natural sorting with numbers
def natural_sort_key(text):
"""
Create sort key for natural sorting.
Sorts 'file2.txt' before 'file10.txt'
"""
import re
parts = re.split('([0-9]+)', text)
parts = [int(part) if part.isdigit() else part.lower() for part in parts]
return parts
filenames = ["file10.txt", "file2.txt", "file1.txt", "file20.txt", "file3.txt"]
# Wrong - Standard sorting
standard_sort = sorted(filenames)
print("Standard sort:")
print(f" {standard_sort}")
# Right - Natural sorting
natural_sort = sorted(filenames, key=natural_sort_key)
print("\nNatural sort:")
print(f" {natural_sort}")
Output:
Standard sort:
['file1.txt', 'file10.txt', 'file2.txt', 'file20.txt', 'file3.txt']
Natural sort:
['file1.txt', 'file2.txt', 'file3.txt', 'file10.txt', 'file20.txt']
Quick Reference: Python String Comparison Methods
Let me give you a complete reference table with examples:
# Example 50: Complete comparison reference
print("STRING COMPARISON QUICK REFERENCE")
print("=" * 60)
# Create test strings
s1 = "Python"
s2 = "python"
s3 = "Python Programming"
print("\n1. EQUALITY OPERATORS:")
print(f" s1 == s2: {s1 == s2} (case-sensitive)")
print(f" s1 != s2: {s1 != s2}")
print(f" s1.lower() == s2.lower(): {s1.lower() == s2.lower()}")
print("\n2. ORDERING OPERATORS:")
print(f" 'apple' < 'banana': {'apple' < 'banana'}")
print(f" 'zebra' > 'apple': {'zebra' > 'apple'}")
print(f" 'cat' <= 'cat': {'cat' <= 'cat'}")
print("\n3. MEMBERSHIP OPERATORS:")
print(f" 'Py' in s1: {'Py' in s1}")
print(f" 'java' not in s3: {'java' not in s3}")
print("\n4. PREFIX/SUFFIX METHODS:")
print(f" s1.startswith('Py'): {s1.startswith('Py')}")
print(f" s1.endswith('on'): {s1.endswith('on')}")
print(f" s1.startswith(('Py', 'Ja')): {s1.startswith(('Py', 'Ja'))}")
print("\n5. CASE METHODS:")
print(f" s1.lower(): '{s1.lower()}'")
print(f" s1.upper(): '{s1.upper()}'")
print(f" s2.title(): '{s2.title()}'")
print("\n6. WHITESPACE HANDLING:")
s4 = " hello "
print(f" ' hello '.strip(): '{s4.strip()}'")
print(f" ' hello '.lstrip(): '{s4.lstrip()}'")
print(f" ' hello '.rstrip(): '{s4.rstrip()}'")
Output:
STRING COMPARISON QUICK REFERENCE
============================================================
1. EQUALITY OPERATORS:
s1 == s2: False (case-sensitive)
s1 != s2: True
s1.lower() == s2.lower(): True
2. ORDERING OPERATORS:
'apple' < 'banana': True
'zebra' > 'apple': True
'cat' <= 'cat': True
3. MEMBERSHIP OPERATORS:
'Py' in s1: True
'java' not in s3: True
4. PREFIX/SUFFIX METHODS:
s1.startswith('Py'): True
s1.endswith('on'): True
s1.startswith(('Py', 'Ja')): True
5. CASE METHODS:
s1.lower(): 'python'
s1.upper(): 'PYTHON'
s2.title(): 'Python'
6. WHITESPACE HANDLING:
' hello '.strip(): 'hello'
' hello '.lstrip(): 'hello '
' hello '.rstrip(): ' hello'
Summary: What You’ve Learned About Python String Comparison
You now have complete knowledge of string comparison in Python! Here’s what we covered:
Basic Operators:
==for checking if strings match exactly!=for checking if strings are different<,>,<=,>=for alphabetical ordering
Case Handling:
.lower()and.upper()for case-insensitive comparisons- Why case sensitivity matters in real applications
Pattern Matching:
inoperator for substring checks.startswith()for prefix matching.endswith()for suffix matching
Advanced Techniques:
- Understanding
isvs== - Handling whitespace with
.strip() - Working with Unicode and special characters
- Building custom comparison functions
Practical Applications:
- Password validation systems
- Search functionality
- File type detection
- Data filtering and sorting
Performance Tips:
- Converting strings once instead of repeatedly
- Using sets for fast lookups
- Optimizing comparisons in loops
Remember these key principles:
- Always use
==for value comparison, notis - Handle case sensitivity explicitly with
.lower()or.upper() - Check for None before calling string methods
- Choose the right method for your specific need
- Think about performance when comparing many strings
Now you’re ready to handle any string comparison task in Python. Practice these examples, modify them for your needs, and you’ll master string comparison quickly!
Practice Exercises
Try these challenges to test your understanding:
# Exercise 1: Build a username validator
def validate_username(username):
"""
Rules:
- 3-20 characters long
- Must start with a letter
- Can only contain letters, numbers, underscore
- Cannot end with underscore
"""
# Your code here
pass
# Exercise 2: Create a smart filter
def filter_products(products, query):
"""
Return products matching query (case-insensitive)
Score higher if query is at the start
"""
# Your code here
pass
# Exercise 3: Compare two lists and report differences
def compare_lists(list1, list2):
"""
Return dictionary with:
- 'added': items in list2 but not list1
- 'removed': items in list1 but not list2
- 'common': items in both
"""
# Your code here
pass
print("Try solving these exercises to practice!")
print("Hint: Use the techniques you learned above")
Output:
Try solving these exercises to practice!
Hint: Use the techniques you learned above
Good luck with your Python string comparison journey! Keep practicing and these concepts will become second nature.
External resources
Official Documentation
- Python Docs – String Methods
https://docs.python.org/3/library/stdtypes.html#string-methods
Covers official explanations forstartswith(),endswith(), comparison operators, and more. - Python Docs – Comparisons
https://docs.python.org/3/reference/expressions.html#comparisons
Explains how Python handles comparison operators (==,<,>, etc.) internally.
Learning and Tutorials
- Real Python – Comparing Strings in Python
https://realpython.com/python-strings/
A practical guide with examples on string operations, slicing, and comparisons. - W3Schools – Python Strings
https://www.w3schools.com/python/python_strings.asp
Beginner-friendly explanation of string operations with interactive examples.
Frequently Asked Questions (FAQs)
1. How do I compare two strings in Python?
You can compare two strings using comparison operators like
==,!=,<,>,<=, and>=.
Example:if "apple" == "apple":
print("Strings match!")
This will print “Strings match!” because both strings are identical.2. What is the difference between
==andiswhen comparing strings?==checks if the values are equal.ischecks if both variables point to the same object in memory.
For string comparison, always use==unless you specifically want to check object identity.3. How can I compare strings in a case-insensitive way?
Convert both strings to lowercase or uppercase before comparing:
if str1.lower() == str2.lower():
print("Case-insensitive match!")4. What is the use of
startswith()andendswith()in Python?startswith()checks if a string begins with a specific prefix.endswith()checks if a string ends with a specific suffix.
Example:filename = "report.pdf"if filename.endswith(".pdf"):
print("This is a PDF file.")5. Can I check if a substring exists inside another string?
Yes. You can use the
inoperator:if "data" in "data_science":
print("Substring found!")6. How can I compare multiple possible string patterns at once?
You can pass a tuple of options to
startswith()orendswith():if filename.endswith((".jpg", ".png", ".gif")):
print("It's an image file.")7. What happens if I compare strings with different lengths?
Python compares strings character by character from left to right. If all matching characters are equal but one string ends sooner, the shorter string is considered smaller.
Example:"abc" < "abcd" # True8. Can I use regular expressions for string comparison?
Yes. For pattern-based matching, use the
remodule:import re if re.search(r"^data_\d+", "data_2024"):
print("Pattern matched!")
Regular expressions allow complex and flexible string comparisons.



")


Leave a Reply