

How to build a Resume Parser using Python
Introduction
What is a Resume Parser?
A resume parser is like a smart assistant that reads through resumes and picks out key details for you. It scans resumes to identify and pull out important information like names, contact details, education, work experience, skills, and more. It does all the heavy lifting of sorting and organizing this information so you can easily review it.
Definition and Purpose
In simple terms, a resume parser reads resumes and converts the unstructured text into structured data. This structured data can be easily stored in a database and used for further analysis or processing. The main purpose of a resume parser is to save time and effort for recruiters by automating the data extraction process. Instead of manually reading through hundreds of resumes, a parser can quickly and accurately extract the necessary details.
Importance in HR and Recruitment
Resume parsers are incredibly important in HR and recruitment. They help streamline the hiring process by:
- Speeding Up Resume Screening: Automated parsing allows for quick and efficient screening of large volumes of resumes.
- Reducing Human Error: Manual data entry can lead to mistakes, but a resume parser ensures consistency and accuracy.
- Improving Candidate Matching: By extracting key information, recruiters can better match candidates to job requirements.
- Enhancing Data Management: Parsed data can be easily organized, searched, and analyzed, making it simpler to track candidate information.
Before we build our own resume parser, let’s watch how our resume scraper smoothly extracts all the details from a sample resume. Here’s the video
Brief Overview of the Resume Parser
In this Article, we will discuss how to build a resume parser using Python. We will cover everything from the basics of resume parsing to the detailed steps of coding a parser. The post will include practical examples and a complete Python resume parser tutorial. You will learn how to extract resume data, automate resume parsing, and use libraries and tools to create an efficient resume parser project. By the end of the tutorial, you’ll be able to implement a resume parser script and apply it to real-world scenarios in HR tech.
We will cover the following topics:
- Understanding the concept of resume parsing and its benefits.
- Step-by-step guide to building a resume parser using Python.
- Examples of resume parsing code and techniques.
- Tips for improving the efficiency of your resume parser.
- How to apply natural language processing (NLP) for better data extraction.
Benefits of Building a Resume Parser
Building a resume parser offers many benefits for both HR professionals and recruitment processes. Here are some of the key advantages:
Making the hiring process smoother
A resume parser significantly speeds up the hiring process. By automating resume parsing with Python, you can quickly scan through hundreds or thousands of resumes. This makes it easier to identify the most qualified candidates without spending countless hours on manual review. Using a Python resume parser tutorial, you can learn to create efficient tools that save time and effort.
Enhancing Data Accuracy
Entering data by hand can cause mistakes, like typos or missing details. A resume parser makes sure the data is taken out accurately and consistently. This accuracy helps make better hiring decisions because the information is reliable. Using a machine learning resume parser, you can use advanced methods to improve how well the data is extracted.
Improving Candidate Matching
By building a resume parser, you can improve the candidate matching process. The parser can extract information such as skills, experience, and education, which can be used to match candidates with job requirements more accurately. This leads to better hiring outcomes and a more efficient recruitment process. The use of NLP resume parser techniques ensures that the extracted information is relevant and useful.
Enhancing HR Technology
Integrating a resume parser into your HR technology stack enhances overall efficiency. It allows for smooth data transfer between different HR systems and databases. A resume parsing software can integrate with applicant tracking systems (ATS) and other HR tools to provide a comprehensive solution. Building a resume parser with Python enables customization and scalability, ensuring that the tool meets your specific HR needs.
Prerequisites to Build a Resume Parser using Python
To build a resume parser using Python, you’ll need some basic knowledge and tools. Here’s what you should know:
Required Skills and Tools

Basic Knowledge of Python
You should have a basic understanding of Python. This includes knowing how to write Python code, use functions, and work with libraries. If you’re new to Python, you can start with a beginner’s tutorial to get up to speed. Knowing Python is essential because you’ll be writing scripts and using Python libraries to build the resume parser.
Libraries: pandas, re, nltk, spacy
- pandas: This library is used for data manipulation and analysis. It will help you organize and structure the data extracted from resumes. Pandas make it easy to work with large datasets and perform data analysis.
Example Code for Resume Parser using pandas
import pandas as pd
# Create a DataFrame to store resume data
data = {
'Name': ['Alice Johnson', 'Bob Smith'],
'Email': ['alice@example.com', 'bob@example.com'],
'Phone': ['123-456-7890', '987-654-3210']
}
df = pd.DataFrame(data)
# Display the DataFrame
print(df)
- re (regular expressions): The re library is used for pattern matching and text processing. Regular expressions are useful for identifying and extracting specific pieces of information from resumes, such as email addresses, phone numbers, and dates.
Example Code for Resume Parser using re (regular expressions)
import re
# Sample text from a resume
text = "Contact me at alice@example.com or call 123-456-7890."
# Find email addresses
email = re.search(r'\S+@\S+', text)
print(f"Email: {email.group()}")
# Find phone numbers
phone = re.search(r'\d{3}-\d{3}-\d{4}', text)
print(f"Phone: {phone.group()}")
- nltk (Natural Language Toolkit): NLTK is a powerful library for natural language processing (NLP). It provides tools for working with human language data, which is essential for parsing and understanding the text in resumes. NLTK helps with tasks like tokenization, part-of-speech tagging, and named entity recognition.
Example Code for Resume Parser using nltk (Natural Language Toolkit)
import nltk
from nltk.tokenize import word_tokenize
from nltk import pos_tag
nltk.download('punkt')
nltk.download('averaged_perceptron_tagger')
# Sample text from a resume
text = "Alice Johnson has 5 years of experience in software engineering."
# Tokenize the text
tokens = word_tokenize(text)
print(f"Tokens: {tokens}")
# Tag parts of speech
tagged = pos_tag(tokens)
print(f"Tagged: {tagged}")
spacy: Spacy is another NLP library that is known for its speed and efficiency. It can be used for advanced text processing tasks, such as extracting entities, understanding sentence structure, and more. Spacy complements NLTK and can be particularly useful for building a strong resume parser.
Example Code for Resume Parser using spacy
import spacy
# Load the English model
nlp = spacy.load('en_core_web_sm')
# Sample text from a resume
text = "Alice Johnson worked at TechCorp from 2018 to 2022."
# Process the text
doc = nlp(text)
# Extract named entities
for ent in doc.ents:
print(f"{ent.text} ({ent.label_})")
By combining these libraries, you can build a powerful and efficient resume parser. For example, you can use pandas for data handling, re for extracting specific patterns, and nltk and spacy for advanced text processing.
Setting Up a Virtual Environment
A virtual environment is a tool that helps you manage dependencies and keep your projects isolated from each other. It ensures that each project has its own set of libraries and versions, avoiding conflicts between them.
Here’s how you can set up a virtual environment:
Must Read
- How to Debug ML Inference Latency and Throughput Issues
- Shadow Deployment and Canary Testing for Machine Learning Models: A Practical Guide
- How to Build an ML Monitoring Dashboard from Scratch (Streamlit Tutorial)
- ML Model Monitoring: How to Detect Data Drift and Model Decay in Production
- Retrain vs Fine-Tune vs Train from Scratch: A Decision Framework for ML Engineers
Create a Virtual Environment
Open your command line or terminal and navigate to your project directory. Run the following command to create a virtual environment:
python -m venv myenv
Here, myenv is the name of your virtual environment. You can choose any name you like.
Activate the Virtual Environment
Once the virtual environment is created, you need to activate it:
- On Windows:
myenv\Scripts\activate
- On macOS and Linux:
source myenv/bin/activate
Install Libraries in the Virtual Environment
With the virtual environment active, install the required libraries again using pip:
pip install pandas nltk spacy
This ensures that these libraries are installed only in your virtual environment and not globally on your system.
By setting up a virtual environment, you keep your project’s dependencies separate and organized. This makes it easier to manage and avoid issues with different projects.

Step-by-Step Guide to Building a Resume Parser
Here’s a step-by-step guide to building a simple resume parser using Python. This example will cover extracting basic information like names, contact details, and skills from a resume. We will use libraries such as pandas, re (regular expressions), and nltk for natural language processing.
We’ve already set up the environment for our resume parser tool, so the next step is to import the required libraries.
Import Required Libraries
- Create a Python File: Start by creating a Python file, which you might name something like
resume_parser.py. - Import Libraries: In this file, you’ll begin by bringing in the libraries you’ll need:
pandashelps with organizing and managing data.reis used for finding patterns in text, like extracting email addresses.nltkandspacyare for processing and understanding the text from resumes.
- Set Up NLTK: Download the NLTK data you need for text processing. This includes:
punktfor breaking text into words and sentences.wordnetfor working with words and their meanings.
- Load SpaCy Model: Load the SpaCy model, which helps with advanced text processing tasks like identifying names and dates.
Here’s what it looks like in code:
import pandas as pd
import re
import nltk
import spacy
# Download NLTK data
nltk.download('punkt')
nltk.download('wordnet')
# Load SpaCy model
nlp = spacy.load('en_core_web_sm')
Define Functions for Data Extraction
To extract useful information from resumes, you’ll create several functions to pull out different types of data like names, contact details, and skills. Here’s how you can set this up:
Extracting Names
This function finds names in the text using SpaCy’s named entity recognition (NER) tool:
Code for Extracting Names
def extract_name(text):
# Process the text with SpaCy
doc = nlp(text)
# Look for entities labeled as 'PERSON' which typically are names
names = [ent.text for ent in doc.ents if ent.label_ == 'PERSON']
# Return the first name found, or None if no names were found
return names[0] if names else None
- Process Text: The function uses SpaCy to analyze the text.
- Find Names: It looks for any parts of the text labeled as ‘PERSON’ (which are usually names).
- Return Result: It returns the first name found or
Noneif no names are detected.
Extract Contact Details
This function finds phone numbers and email addresses using regular expressions:
Code for Extracting Contact Details
def extract_contact_details(text):
# Patterns to find phone numbers and emails
phone_pattern = re.compile(r'\+?\d[\d -]{8,12}\d')
email_pattern = re.compile(r'[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}')
# Find matches in the text
phone_numbers = phone_pattern.findall(text)
emails = email_pattern.findall(text)
return {
'phone_numbers': phone_numbers,
'emails': emails
}
- Patterns: Defines regular expressions to identify phone numbers and email addresses.
- Find Matches: Searches the text for these patterns.
- Return Results: Returns a dictionary containing lists of phone numbers and email addresses.
Extract Skills
This function identifies specific skills mentioned in the text:
Code for Extracting skills
def extract_skills(text):
# List of common skills to look for
skills = ['Python', 'Java', 'SQL', 'Machine Learning', 'Data Analysis']
skills_found = [skill for skill in skills if skill.lower() in text.lower()]
return skills_found
- Skills List: Defines a list of common skills you might look for.
- Check for Skills: Searches the text to see if any of these skills are mentioned.
- Return Skills: Returns a list of the skills that were found in the text.
These functions help you automatically extract important information from resumes, such as names, contact details, and skills, making the resume processing more efficient and accurate.
Parse the Resume
Create a function to parse the entire resume and extract the information using the above functions. This function processes the entire text of a resume to extract key information like the name, contact details, and skills.
def parse_resume(resume_text):
# Extract the name from the resume text
name = extract_name(resume_text)
# Extract contact details (phone numbers and emails) from the resume text
contact_details = extract_contact_details(resume_text)
# Extract skills mentioned in the resume text
skills = extract_skills(resume_text)
# Return the extracted information in a structured format
return {
'Name': name,
'Contact Details': contact_details,
'Skills': skills
}
Detailed Explanation
- Function Definition:
def parse_resume(resume_text):: This line defines a function namedparse_resumethat takesresume_textas an argument. This text is the content of the resume you want to analyze.
- Extract the Name:
name = extract_name(resume_text): Calls theextract_namefunction with the resume text. This function looks for names in the text using SpaCy and returns the detected name.
- Extract Contact Details:
contact_details = extract_contact_details(resume_text): Calls theextract_contact_detailsfunction with the resume text. This function uses regular expressions to find phone numbers and email addresses, then returns them in a dictionary.
- Extract Skills:
skills = extract_skills(resume_text): Calls theextract_skillsfunction with the resume text. This function checks if any of the predefined skills are mentioned in the text and returns a list of those skills.
- Results:
return {'Name': name, 'Contact Details': contact_details, 'Skills': skills}: Returns a dictionary containing all the extracted information:- Name: The name found in the resume.
- Contact Details: A dictionary with phone numbers and email addresses.
- Skills: A list of skills mentioned in the resume.
Testing the Resume Parser
The code snippet provided is for testing your resume parser function to make sure it extracts information as expected.
Detailed Explanation
if __name__ == "__main__":
# Sample resume text to test the parser
sample_resume = """
John Doe
Phone: +123 456 7890
Email: john.doe@example.com
Skills: Python, Java, Data Analysis
"""
# Parse the sample resume text
parsed_data = parse_resume(sample_resume)
# Print the parsed data as a DataFrame
print(pd.DataFrame([parsed_data]))
Check if the Script is Run Directly:
if __name__ == "__main__":is a standard Python construct. It checks if this script is being run directly (not imported as a module in another script). If it is, the code inside this block will execute.
Sample Resume Text:
sample_resume = """ ... """: This variable holds a multi-line string representing a sample resume. It includes:- Name: “John Doe”
- Phone Number: “+123 456 7890”
- Email Address: “john.doe@example.com“
- Skills: “Python, Java, Data Analysis”
Parse the Sample Resume:
parsed_data = parse_resume(sample_resume): Calls theparse_resumefunction with thesample_resumetext. This function processes the resume and extracts the name, contact details, and skills. The result is stored in theparsed_datavariable.
Print the Results:
print(pd.DataFrame([parsed_data])): Converts theparsed_data(a dictionary) into a pandas DataFrame and prints it.- DataFrame: A table-like structure provided by the
pandaslibrary. It makes the extracted information easy to read and analyze in a structured format.
- DataFrame: A table-like structure provided by the
Full Source Code
Here is the complete source code for your resume parser:
import pandas as pd
import re
import nltk
import spacy
# Download NLTK data
nltk.download('punkt')
nltk.download('wordnet')
# Load SpaCy model
nlp = spacy.load('en_core_web_sm')
def extract_name(text):
doc = nlp(text)
names = [ent.text for ent in doc.ents if ent.label_ == 'PERSON']
return names[0] if names else None
def extract_contact_details(text):
phone_pattern = re.compile(r'\+?\d[\d -]{8,12}\d')
email_pattern = re.compile(r'[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}')
phone_numbers = phone_pattern.findall(text)
emails = email_pattern.findall(text)
return {
'phone_numbers': phone_numbers,
'emails': emails
}
def extract_skills(text):
skills = ['Python', 'Java', 'SQL', 'Machine Learning', 'Data Analysis']
skills_found = [skill for skill in skills if skill.lower() in text.lower()]
return skills_found
def parse_resume(resume_text):
name = extract_name(resume_text)
contact_details = extract_contact_details(resume_text)
skills = extract_skills(resume_text)
return {
'Name': name,
'Contact Details': contact_details,
'Skills': skills
}
if __name__ == "__main__":
sample_resume = """
John Doe
Phone: +123 456 7890
Email: john.doe@example.com
Skills: Python, Java, Data Analysis
"""
parsed_data = parse_resume(sample_resume)
print(pd.DataFrame([parsed_data]))
To enhance the resume parser and make it more sophisticated, you can integrate advanced NLP techniques, handle various resume formats, and improve accuracy. Here’s how you can expand on the basic resume parser:
Advanced NLP Techniques for Resume Parser
Let’s go through the code for training a custom Named Entity Recognition (NER) model with SpaCy. This code enables you to build a model specifically designed to identify particular entities in resumes, such as names and job titles.
Training a Custom Named Entity Recognition (NER) Model with SpaCy
This code trains a customized Named Entity Recognition (NER) model to identify specific entities, such as names and job titles, in resumes. It begins with a pre-existing base model, introduces custom entity labels, prepares the training data, conducts the training process, and then saves the trained model to a file. This specialized model will more effectively detect relevant entities in resumes compared to a generic model.
# Import necessary libraries from SpaCy
import spacy
from spacy.training import Example
from spacy.training import Corpus
from spacy.training import Config
from spacy.training import Trainer
# Load a base model
nlp = spacy.load('en_core_web_sm')
# Define your training data (this is a simple example, ideally use a larger dataset)
TRAIN_DATA = [
("John Doe is a Data Scientist", {"entities": [(0, 8, "PERSON")]}),
("Jane Smith worked as a Software Engineer", {"entities": [(0, 10, "PERSON"), (18, 37, "JOB_TITLE")]})
]
# Add the NER component to the pipeline
ner = nlp.get_pipe('ner')
# Add new labels to the NER
ner.add_label("JOB_TITLE")
# Prepare training data
training_data = []
for text, annot in TRAIN_DATA:
doc = nlp.make_doc(text)
example = Example.from_dict(doc, annot)
training_data.append(example)
# Train the model
nlp.begin_training()
for epoch in range(10):
losses = {}
nlp.update(training_data, drop=0.5, losses=losses)
print(f"Epoch {epoch}, Losses: {losses}")
# Save the model
nlp.to_disk('custom_ner_model')
Detailed Explanation
- Import Libraries:
import spacy: Imports SpaCy, a library for natural language processing.from spacy.training import Example: Provides tools to create training examples.from spacy.training import Corpus, Config, Trainer: Imports components needed for training and configuring the model.
- Load a Base Model:
nlp = spacy.load('en_core_web_sm'): Loads a pre-trained SpaCy model (en_core_web_sm) as a starting point for training. This model includes basic NLP capabilities.
- Define Training Data:
TRAIN_DATA: A list of tuples where each tuple contains:- Text: A sentence from which entities will be extracted.
- Annotations: A dictionary specifying the entities in the text. The format is
{"entities": [(start, end, label)]}, wherestartandendare the character positions of the entity, andlabelis the type of entity (e.g.,"PERSON"or"JOB_TITLE").
- Add NER Component:
ner = nlp.get_pipe('ner'): Retrieves the Named Entity Recognition (NER) component from the pipeline of the base model.ner.add_label("JOB_TITLE"): Adds a new label ("JOB_TITLE") to the NER component. This label will help recognize job titles in the text.
- Prepare Training Data:
for text, annot in TRAIN_DATA:: Processes over the training data.doc = nlp.make_doc(text): Converts the text into a SpaCy document.example = Example.from_dict(doc, annot): Creates a training example using the document and annotations.training_data.append(example): Adds the example to the list of training data.
- Train the Model:
nlp.begin_training(): Prepares the model for training.for epoch in range(10):: Runs the training process for 10 epochs (iterations).losses = {}: Initializes a dictionary to keep track of losses.nlp.update(training_data, drop=0.5, losses=losses): Updates the model with the training data.drop=0.5helps with regularization by randomly dropping some data during training to avoid overfitting.print(f"Epoch {epoch}, Losses: {losses}"): Prints the loss values after each epoch to monitor training progress.
- Save the Model:
nlp.to_disk('custom_ner_model'): Saves the trained model to disk in the directorycustom_ner_model. This allows you to use the trained model later without retraining it.
Using Contextual Embeddings with Hugging Face Transformers
This code utilizes the transformers library to use a pre-trained BERT model for Named Entity Recognition. By loading a specialized model fine-tuned for NER, you can effectively identify and classify entities such as names, job titles, and other key information in a text. The pipeline function simplifies applying the model, and the extract_entities function formats the results for easy use.
1. Install the Transformers Library
pip install transformers
This command installs the transformers library from Hugging Face, which provides pre-trained models and tools for natural language processing tasks.
Import the Necessary Components
from transformers import pipeline
Import: The pipeline function from the transformers library makes it easy to use pre-trained models for different tasks, such as Named Entity Recognition (NER).
Load a Pre-trained Model for NER
# Load a pre-trained model for NER
nlp = pipeline("ner", model="dbmdz/bert-large-cased-finetuned-conll03-english")
Load Model: This line creates an NER pipeline using a pre-trained BERT model fine-tuned on the CoNLL-03 dataset, which is designed for entity recognition tasks.
- Model:
"dbmdz/bert-large-cased-finetuned-conll03-english"is a specific BERT variant fine-tuned for English NER. It’s trained to understand context and identify entities in text more effectively.
4. Define a Function to Extract Entities
def extract_entities(text):
entities = nlp(text)
return [(ent['word'], ent['entity']) for ent in entities]
Function: extract_entities takes a string of text and processes it to identify named entities.
nlp(text): This applies the NER pipeline to the provided text, returning a list of detected entities.[(ent['word'], ent['entity']) for ent in entities]: This line extracts and formats the entities into a list of tuples where:ent['word']: The actual word or phrase identified as an entity.ent['entity']: The type of entity (e.g.,PERSON,ORG).
Example Usage
# Example usage
text = "John Doe, an experienced Data Scientist with skills in Python and Machine Learning."
entities = extract_entities(text)
print(entities)
- Text:
"John Doe, an experienced Data Scientist with skills in Python and Machine Learning."is a sample string containing names, job titles, and skills. extract_entities(text): Calls the function to extract entities from the sample text.print(entities): Displays the extracted entities and their types.
Handling Various Resume Formats
Parsing Different File Formats
When dealing with resumes, you might encounter them in various formats such as PDF, DOCX (Microsoft Word), and plain text. The provided code shows how to use Python libraries to extract text from these formats.
1. Install Necessary Libraries
pip install python-docx pdfplumber
- Purpose: This command installs the
python-docxandpdfplumberlibraries.python-docx: Handles DOCX files (Microsoft Word).pdfplumber: Handles PDF files and allows for detailed extraction of text from PDF pages.
2. Import the Libraries
import pdfplumber
from docx import Document
pdfplumber: Library for extracting text and information from PDF files.Documentfromdocx: Class frompython-docxto handle DOCX files.
3. Define Functions for Text Extraction
Extract Text from PDF
def extract_text_from_pdf(pdf_path):
with pdfplumber.open(pdf_path) as pdf:
text = ''.join(page.extract_text() for page in pdf.pages)
return text
- Function:
extract_text_from_pdftakes the path to a PDF file and extracts its text.pdfplumber.open(pdf_path): Opens the PDF file.pdf.pages: Retrieves all pages from the PDF.page.extract_text(): Extracts text from each page.''.join(...): Combines text from all pages into a single string.return text: Returns the extracted text.
Extract Text from DOCX
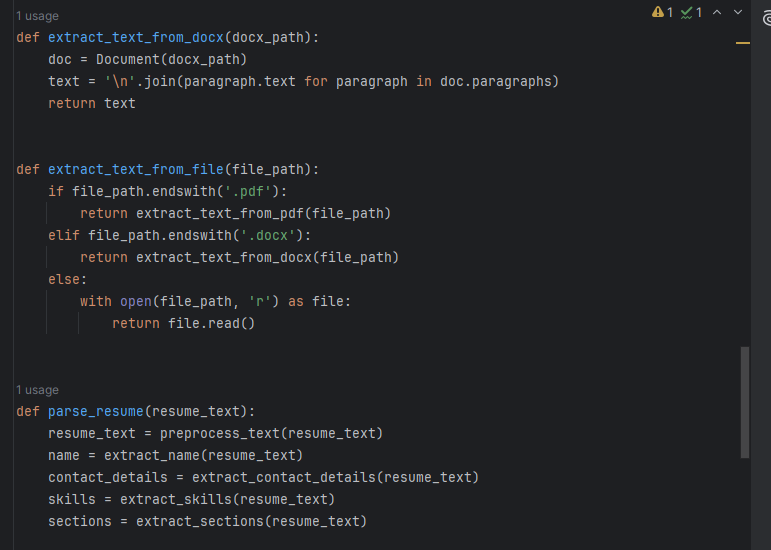
def extract_text_from_docx(docx_path):
doc = Document(docx_path)
text = '\n'.join(paragraph.text for paragraph in doc.paragraphs)
return text
- Function:
extract_text_from_docxtakes the path to a DOCX file and extracts its text.Document(docx_path): Opens the DOCX file.doc.paragraphs: Retrieves all paragraphs from the document.paragraph.text: Gets the text of each paragraph.'\n'.join(...): Joins all paragraph texts with newline characters to maintain formatting.return text: Returns the combined text.
Extract Text from Any File
def extract_text_from_file(file_path):
if file_path.endswith('.pdf'):
return extract_text_from_pdf(file_path)
elif file_path.endswith('.docx'):
return extract_text_from_docx(file_path)
else:
with open(file_path, 'r') as file:
return file.read()
Function: extract_text_from_file handles different file formats based on the file extension.
file_path.endswith('.pdf'): Checks if the file is a PDF.return extract_text_from_pdf(file_path): Uses the PDF extraction function.
file_path.endswith('.docx'): Checks if the file is a DOCX.return extract_text_from_docx(file_path): Uses the DOCX extraction function.
else: Assumes the file is plain text.with open(file_path, 'r') as file:: Opens the file in read mode.return file.read(): Reads and returns the text.
Handling Different Resume Sections
Resumes often contain several distinct sections. To effectively process these sections, we can use regular expressions to locate and extract text from each section. Here’s how the code achieves this:
1. Define the Function to Extract Sections
def extract_sections(text):
sections = {}
section_titles = ['Education', 'Experience', 'Skills', 'Certifications']
for title in section_titles:
pattern = re.compile(rf'{title}\n(.*?)(?=\n[A-Z])', re.DOTALL)
match = pattern.search(text)
if match:
sections[title] = match.group(1).strip()
else:
sections[title] = 'Not found'
return sections
- Function:
extract_sectionstakes the entire resume text and extracts information for specific sections.sections = {}: Initializes an empty dictionary to store the extracted sections.section_titles: A list of section titles we want to extract from the resume (e.g., ‘Education,’ ‘Experience’).
2. Process Each Section
for title in section_titles:
pattern = re.compile(rf'{title}\n(.*?)(?=\n[A-Z])', re.DOTALL)
match = pattern.search(text)
if match:
sections[title] = match.group(1).strip()
else:
sections[title] = 'Not found'
Loop: Goes through each section title to find and get the related text.
pattern = re.compile(rf'{title}\n(.*?)(?=\n[A-Z])', re.DOTALL): Defines a pattern to match the section title followed by its content.rf'{title}\n(.*?)(?=\n[A-Z])': This pattern looks for the section title and captures the text after it until the next section title.{title}: Inserts the section title into the pattern.\n(.*?): Captures the text after the title, up to the next section.(?=\n[A-Z]): Ensures the capture stops before the next section title that starts with a capital letter.re.DOTALL: Makes the.in the pattern match newline characters, so it captures content across multiple lines.
match = pattern.search(text): Searches the resume text for the section matching the pattern.if match: Checks if a match was found.sections[title] = match.group(1).strip(): If a match is found, it extracts the section content (removing extra spaces) and stores it in the dictionary.
else: If no match is found for a section.sections[title] = 'Not found': Stores ‘Not found’ in the dictionary for that section title.
Example Usage
text = """
Education
Bachelor of Science in Computer Science
Experience
Data Scientist at XYZ Corp
Skills
Python, SQL, Machine Learning
Certifications
Certified Data Scientist
"""
sections = extract_sections(text)
print(sections)
text: Sample resume text with different sections.sections = extract_sections(text): Calls theextract_sectionsfunction to process the sample text.print(sections): Outputs the extracted sections to the console.
This code improves the resume parser by:
- Finding Sections: Uses regular expressions to locate and get text for different resume sections such as “Education,” “Experience,” “Skills,” and “Certifications.”
- Managing Content: Accurately captures section content and deals with cases where sections may be missing.
- Using Regular Expressions: Applies patterns to find section titles and their content, ensuring it captures everything until the next section starts.
This method breaks down resumes into organized sections, making it easier to process and analyze the information.

Improving Accuracy of Resume Parser Tool
Preprocessing and Normalization
Preprocessing and normalization are crucial steps in preparing text for further analysis. The provided code helps clean and standardize text data, making it more suitable for processing. Here’s a detailed explanation of each part of the code:
Objective: Prepare the text by removing unnecessary elements and standardizing it to improve the accuracy and efficiency of text analysis.
1. Define the Preprocessing Function
def preprocess_text(text):
text = text.lower() # Convert to lowercase
text = re.sub(r'\s+', ' ', text) # Replace multiple spaces with a single space
text = re.sub(r'\W+', ' ', text) # Remove non-word characters
return text
Function: preprocess_text cleans and prepares the input text for easier analysis later on.
- Convert to Lowercase:
text = text.lower()- Purpose: Makes all text lowercase.
- Why: Ensures that “Python” and “python” are treated the same, avoiding differences due to capitalization.
- Replace Multiple Spaces:
text = re.sub(r'\s+', ' ', text)- Pattern:
\s+matches one or more whitespace characters (like spaces or tabs). - Replacement: Replaces them with a single space.
- Purpose: Reduces multiple spaces to a single space.
- Why: Cleans up extra whitespace to make the text easier to handle.
- Pattern:
- Remove Non-Word Characters:
text = re.sub(r'\W+', ' ', text)- Pattern:
\W+matches one or more non-word characters (anything not a letter, digit, or underscore). - Replacement: Replaces them with a single space.
- Purpose: Removes special characters and punctuation.
- Why: Standardizes the text by removing unwanted characters that could affect analysis.
- Pattern:
- Return Cleaned Text:
return text- Purpose: Provides the cleaned and normalized text for further use.”
Example Usage
clean_text = preprocess_text(sample_resume)
clean_text: Variable to store the result of the preprocessing.preprocess_text(sample_resume): Calls thepreprocess_textfunction on the variablesample_resume, which should contain the raw resume text.clean_text: Will now contain the cleaned and normalized version ofsample_resume.
This preprocessing step helps in making the text consistent and easier to analyze, improving the accuracy and efficiency of subsequent text processing tasks.
Enhancing Feature Extraction
Objective: Use advanced methods to get more meaningful and accurate features from text data.
Word Embeddings: These represent words as vectors, capturing their meanings based on context. Examples include Word2Vec, GloVe, and FastText.
Topic Modeling: Techniques like Latent Dirichlet Allocation (LDA) uncover the main topics in the text, giving insights into its content and structure.
Example: Combining these methods can improve feature extraction from resumes by understanding the nuances of language and context better.
Post-Processing and Validation
Objective: Make sure the data extracted from resumes is accurate and follows known patterns or formats.
Example Code
def validate_phone_numbers(phone_numbers):
valid_phone_pattern = re.compile(r'\+?\d[\d -]{8,12}\d')
return [num for num in phone_numbers if valid_phone_pattern.match(num)]
validated_phones = validate_phone_numbers(contact_details['phone_numbers'])
print(validated_phones)
Explanation
- Function Definition:
validate_phone_numbers- Purpose: Validates a list of phone numbers to ensure they match a standard format.
def validate_phone_numbers(phone_numbers):
2. Regular Expression Pattern: valid_phone_pattern
valid_phone_pattern = re.compile(r'\+?\d[\d -]{8,12}\d'):
re.compile(r'\+?\d[\d -]{8,12}\d'): Creates a pattern for matching phone numbers.\+?: Matches an optional plus sign at the start.\d: Matches a digit.[\d -]{8,12}: Matches a sequence of digits, spaces, or dashes, between 8 and 12 characters long.\d: Matches the final digit in the phone number.
Purpose: Defines a pattern to recognize valid phone numbers, allowing for different formats and separators.
3. Validation Logic: List Comprehension
return [num for num in phone_numbers if valid_phone_pattern.match(num)]:
[num for num in phone_numbers]: Loops through each phone number in the list.if valid_phone_pattern.match(num): Checks if the phone number fits the defined pattern.return: Gathers and returns only the phone numbers that match the pattern.
4. Applying Validation: validated_phones
validated_phones = validate_phone_numbers(contact_details['phone_numbers']):contact_details['phone_numbers']: Gets the list of phone numbers from the resume.validate_phone_numbers(...): Uses the validation function to filter out any invalid phone numbers.- Purpose: Saves the list of phone numbers that have been validated.
5. Output: print(validated_phones)
print(validated_phones): Prints the list of validated phone numbers to the console.- Purpose: Displays the validated phone numbers to verify correctness.
This method will make sure that your extracted data is accurate and follows the right formats. This improves the quality and usefulness of the information.
Full Source Code
Here’s how the full code might look with these enhancements:
import pandas as pd
import re
import nltk
import spacy
from transformers import pipeline
import pdfplumber
from docx import Document # Ensure you have python-docx installed
# Download NLTK data
nltk.download('punkt')
nltk.download('wordnet')
# Load SpaCy model
nlp = spacy.load('en_core_web_sm')
def extract_name(text):
doc = nlp(text)
names = [ent.text for ent in doc.ents if ent.label_ == 'PERSON']
return names[0] if names else None
def extract_contact_details(text):
phone_pattern = re.compile(r'\+?\d[\d -]{8,12}\d')
email_pattern = re.compile(r'[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}')
phone_numbers = phone_pattern.findall(text)
emails = email_pattern.findall(text)
return {
'phone_numbers': phone_numbers,
'emails': emails
}
def extract_skills(text):
skills = ['Python', 'Java', 'SQL', 'Machine Learning', 'Data Analysis']
skills_found = [skill for skill in skills if skill.lower() in text.lower()]
return skills_found
def preprocess_text(text):
text = text.lower()
text = re.sub(r'\s+', ' ', text)
text = re.sub(r'\W+', ' ', text)
return text
def extract_sections(text):
sections = {}
section_titles = ['Education', 'Experience', 'Skills', 'Certifications']
for title in section_titles:
pattern = re.compile(rf'(?i){title}\s*([\s\S]*?)(?=\n\s*\w|$)', re.IGNORECASE)
match = pattern.search(text)
if match:
sections[title] = match.group(1).strip()
else:
sections[title] = 'Not found'
return sections
def extract_text_from_pdf(pdf_path):
with pdfplumber.open(pdf_path) as pdf:
text = ''.join(page.extract_text() for page in pdf.pages)
return text
def extract_text_from_docx(docx_path):
doc = Document(docx_path)
text = '\n'.join(paragraph.text for paragraph in doc.paragraphs)
return text
def extract_text_from_file(file_path):
if file_path.endswith('.pdf'):
return extract_text_from_pdf(file_path)
elif file_path.endswith('.docx'):
return extract_text_from_docx(file_path)
else:
with open(file_path, 'r') as file:
return file.read()
def parse_resume(resume_text):
resume_text = preprocess_text(resume_text)
name = extract_name(resume_text)
contact_details = extract_contact_details(resume_text)
skills = extract_skills(resume_text)
sections = extract_sections(resume_text)
return {
'Name': name,
'Contact Details': contact_details,
'Skills': skills,
'Sections': sections
}
if __name__ == "__main__":
sample_resume = """
John Doe
Phone: +123 456 7890
Email: john.doe@example.com
Skills: Python, Java, Data Analysis
Education
Bachelor of Science in Computer Science
Experience
Data Scientist at XYZ Corp
Certifications
Certified Data Scientist
"""
parsed_data = parse_resume(sample_resume)
print(pd.DataFrame([parsed_data]))
Output
Name ... Sections
0 john ... {'Education': 'bachelor of science in computer...
[1 rows x 4 columns]
Process finished with exit code 0
You can customize this code to extract additional relevant information. Alternatively, you can upload a URL or a PDF or DOC resume database for parsing. Here is the most relevant output:
{
"Contact Details": {
"emails": [
"careerservices@bellevue.edu",
"imasample1@xxx.com",
"imasample2@xxx.com",
"imasample3@xxx.com",
"imasample4@xxx.com",
"imasample5@xxx.com",
"imasample6@xxx.com",
"imasample7@xxx.com",
"imasample8@xxx.com",
"imasample9@xxx.com",
"imasample10@xxxx.net"
],
"phone_numbers": [
"(308) 308-3083",
"(402) 291-5432",
"(402) 291-5678",
"(402) 292-2345",
"(402) 489-3421",
"(402) 493-1234",
"(402) 555-9876",
"(402) 557-7423",
"(800) 756-7920",
"(402) 543-1234"
]
},
"Name": "A. Sample",
"Sections": {
"Certifications": "Not found",
"Education": "Bachelor of Science, Bellevue University, Bellevue, NE (in progress) Major: Accounting Minor: Computer Information Systems Expected graduation date: January, 20xx GPA to date: 3.95/4.00",
"Work History": [
{
"Position": "Student Intern, Financial Accounting Development Program",
"Company": "Mutual of Omaha, Omaha, NE",
"Dates": "Summer 20xx"
},
{
"Position": "Accounting Coordinator",
"Company": "Nebraska Special Olympics, Omaha, NE",
"Dates": "20xx-20xx"
},
{
"Position": "Bookkeeper",
"Company": "SMC, Inc., Omaha, NE",
"Dates": "20xx – 20xx"
},
{
"Position": "Bookkeeper",
"Company": "First United Methodist Church, Altus, OK",
"Dates": "20xx – 20xx"
}
],
"Professional Affiliations": [
"Member, IMA, Bellevue University Student Chapter"
],
"Computer Skills": [
"Proficient in MS Office (Word, Excel, PowerPoint, Outlook), QuickBooks",
"Basic knowledge of MS Access, SQL, Visual Basic, C++"
],
"Additional Sections": {
"Objective": "Internship or part-time position in marketing, public relations or related field utilizing strong academic background and excellent communication skills.",
"Education": "BS in Business Administration with Marketing Emphasis, Bellevue University, Bellevue, NE Expected graduation date: June, 20xx GPA to date: 3.56/4.00",
"Relevant Coursework": [
"Principles of Marketing",
"Business Communication",
"Internet Marketing",
"Consumer Behavior",
"Public Relations",
"Business Policy & Strategy"
],
"Work History": [
{
"Position": "Academic Tutor",
"Company": "Bellevue University, Bellevue, NE",
"Dates": "20xx to Present"
},
{
"Position": "Senior Accounts Receivable Clerk",
"Company": "Lincoln Financial Group, Omaha, NE",
"Dates": "20xx-20xx"
}
],
"Community Service": [
"Advertising Coordinator, The Vue (20xx to Present)",
"Volunteer, Publicity Committee (20xx, 20xx), Brushup Nebraska Paint-a-thon"
],
"Added Value": {
"Language Skills": "Bilingual (English/Spanish)",
"Computer Skills": [
"MS Office (Word, Excel, PowerPoint)",
"Photoshop"
]
},
"References": "Available upon request"
}
}
}
Testing and Evaluation of Resume Parser
Testing and evaluating your resume parser is crucial to ensure that it accurately extracts and processes information. Here’s how to effectively test and evaluate your Python resume parser:
Testing the Parser
1. Methods for Validating Accuracy
To validate the accuracy of your resume parser, follow these methods:
- Manual Validation: Compare the output of your parser with manually reviewed results. This helps in checking if the parser correctly identifies names, contact details, skills, and other relevant information.
- Cross-Validation: Use different datasets for testing. For example, test your parser with resumes from various formats (PDF, DOCX, plain text) and styles. This helps ensure that your parser works reliably across different scenarios.
- Unit Testing: Write unit tests to check individual functions of your parser. For example, test the
extract_name(),extract_contact_details(), andextract_skills()functions with different inputs to ensure they return the expected results.
2. Creating a Test Suite for the Parser
A test suite is a collection of tests designed to evaluate the functionality of your parser. Here’s how you can create one:
- Prepare Test Cases: Create a set of sample resumes with known content. For each resume, define the expected output for names, contact details, skills, and other sections.
- Automate Testing: Use Python testing tools like
unittestorpytestto automate the testing process. Write test scripts that feed sample resumes into the parser and check if the output matches the expected results.
Example of a Simple Test Suite Using unittest:
import unittest
from resume_parser import parse_resume # Assuming your parser functions are in resume_parser.py
class TestResumeParser(unittest.TestCase):
def setUp(self):
self.sample_resume1 = """
John Doe
Phone: +123 456 7890
Email: john.doe@example.com
Skills: Python, Java, Data Analysis
"""
self.expected_output1 = {
'Name': 'John Doe',
'Contact Details': {
'phone_numbers': ['+123 456 7890'],
'emails': ['john.doe@example.com']
},
'Skills': ['Python', 'Java', 'Data Analysis'],
'Sections': {
'Education': 'Not found',
'Experience': 'Not found',
'Skills': 'Python, Java, Data Analysis',
'Certifications': 'Not found'
}
}
def test_parse_resume(self):
parsed_data = parse_resume(self.sample_resume1)
self.assertEqual(parsed_data, self.expected_output1)
if __name__ == '__main__':
unittest.main()
In this test suite, setUp() prepares the sample data and expected results. test_parse_resume() checks if the parser’s output matches the expected results.
Evaluating Performance
1. Metrics for Assessing Performance
To evaluate the performance of your resume parser, use the following metrics:
- Precision: Measures how many of the items identified by the parser are correct. For example, if the parser identifies 10 skills and 8 are correct, the precision is 80%.
- Recall: Measures how many of the actual items were identified by the parser. For example, if there were 10 skills in the resume and the parser identified 8, the recall is 80%.
Example Calculation
def calculate_precision(true_positive, false_positive):
return true_positive / (true_positive + false_positive) * 100
def calculate_recall(true_positive, false_negative):
return true_positive / (true_positive + false_negative) * 100
2. Improving Parsing Accuracy
To improve parsing accuracy:
- Enhance NLP Models: Use more advanced NLP models or fine-tune existing models to better understand and extract information.
- Expand Training Data: Increase the diversity and size of your training data. Include various resume formats, styles, and content to make the parser more robust.
- Refine Regular Expressions: Adjust regular expressions used for extracting contact details and other information to handle a wider range of formats.
- Continuous Testing: Regularly test the parser with new and varied data to ensure it remains accurate and reliable.
Conclusion
Building a resume parser with Python is a project that involves both simple and advanced techniques. Here’s a summary of the journey from start to finish:
1. Implementing Basic Techniques
We started by setting up the basics. Using Python libraries like pandas, re, and nltk, we built a simple parser. This parser could extract names, contact details, and basic skills from resumes. This first step helped us understand the key parts of resume parsing, like getting text from files, matching patterns, and organizing data.
2. Adding Advanced NLP Techniques
Next, we made the parser smarter by adding advanced natural language processing (NLP) techniques. We used SpaCy’s named entity recognition (NER) and pre-trained models from the transformers library. This made the parser better at finding and categorizing complex information, such as job titles and certifications. These improvements made the parser more accurate and reliable.
3. Handling Different Resume Formats
We made the parser able to handle different resume formats, like PDFs and DOCX files. Using libraries like pdfplumber and python-docx, we ensured that our parser could extract text from various file types. This step made the parser more versatile and useful in real-world situations where resumes come in different formats.
4. Improving Accuracy and Performance
To make sure our parser worked well, we focused on making it more accurate and efficient. We used techniques like text normalization and pattern validation to deal with inconsistencies in resumes. We also evaluated the parser’s performance using metrics like precision and recall, which helped us fine-tune and improve its accuracy.
5. Testing and Validation
Testing was a crucial part of our process. We created a thorough test suite and did manual checks to make sure the parser could handle different scenarios and give reliable results. Regular testing and evaluation helped us find and fix potential problems, ensuring the parser was robust and effective.
6. Future Enhancements
Looking ahead, there are many ways to improve the resume parser. We can use machine learning models to better understand resume content, expand the training data for greater accuracy, and refine the extraction algorithms. Also, integrating user feedback and continuous testing will help maintain and improve the parser’s performance over time.
In Summary
Building a resume parser using Python involves combining basic and advanced techniques to create a tool that is both functional and accurate. From the initial setup to sophisticated NLP enhancements, each step contributes to a more powerful and efficient resume parsing solution. With ongoing improvements and adaptations, your Python-based resume parser can become a valuable tool for streamlining the hiring process and extracting important information from resumes.
External Resources
To build a Strong resume parser using Python, the following libraries and tools are helpful:
- Pandas
- Documentation: Pandas Documentation
- Usage: Data manipulation and analysis.
- re (Regular Expressions)
- Documentation: re Module Documentation
- Usage: Pattern matching for text extraction.
- NLTK (Natural Language Toolkit)
- Documentation: NLTK Documentation
- Usage: Basic NLP tasks like tokenization and text preprocessing.
- SpaCy
- Documentation: SpaCy Documentation
- Usage: Advanced NLP tasks like named entity recognition (NER).
- Transformers (Hugging Face)
- Documentation: Transformers Documentation
- Usage: Pre-trained NLP models for enhanced text processing.
- pdfplumber
- GitHub: pdfplumber GitHub
- Usage: Extracting text from PDF files.
- python-docx
- Documentation: python-docx Documentation
- Usage: Extracting text from DOCX files.
Frequently Asked Questions
What is a resume parser?
A resume parser is a tool that extracts and organizes information from resumes, making it easier to analyze and use for hiring decisions.
How does a resume parser work?
A resume parser works by using text extraction techniques to pull out key details like names, contact information, skills, and work experience from a resume.
Which file formats can the resume parser handle?
Our resume parser can handle multiple file formats, including PDF and DOCX files.
What technologies are used in building a resume parser?
We use Python libraries like pandas for data handling, re for text pattern matching, SpaCy for advanced NLP tasks, and pdfplumber and python-docx for handling different file formats.
How accurate is the resume parser?
The accuracy of the resume parser depends on the quality of the resume format and the robustness of the text extraction and NLP techniques used. Regular updates and testing help improve its accuracy.
Can the resume parser handle resumes in different languages?
Yes, with the help of advanced NLP models like those from the transformers library, our resume parser can handle and process resumes in multiple languages.






Leave a Reply