

How to Use SAM 2 for Video Segmentation
Introduction
If you’ve ever wondered how videos are analyzed and understood, you’re in the right place. This blog post will take you through the importance of video segmentation, explore its impact on various industries, and introduce you to the latest advancement, SAM 2. Get ready for an in-depth look at these technologies in a way that’s easy to follow and engaging.
Overview of Video Segmentation
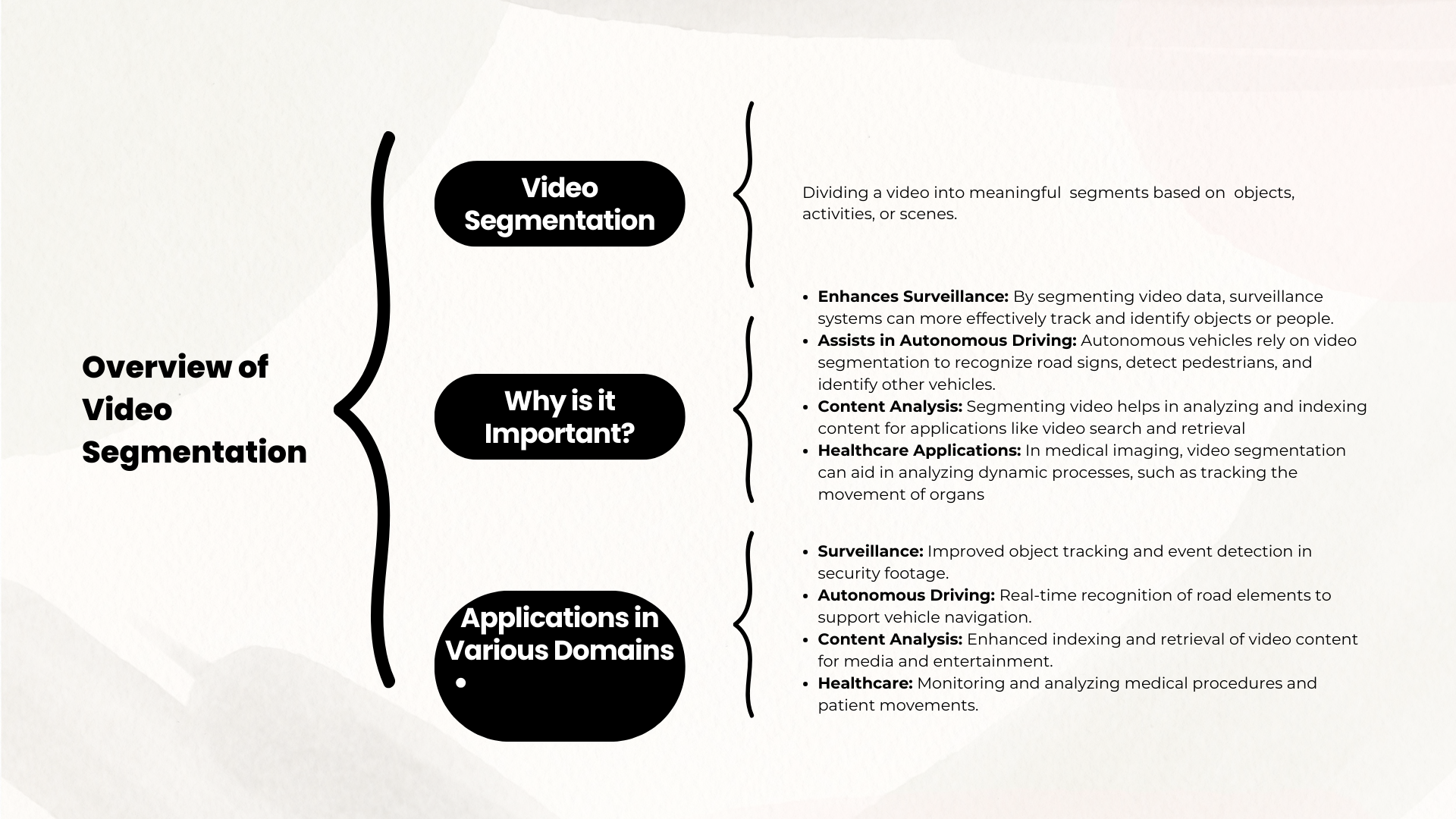
What is Video Segmentation?
Video segmentation is the process of dividing a video into smaller parts. These segments can be based on various factors such as objects, activities, or scenes within the video. This is hust like breaking a video into manageable chunks to make it easier to analyze and interpret. This process helps in understanding and processing the content more effectively.
Why is Video Segmentation Important?
Video segmentation is crucial in several areas. It improves surveillance systems by making it easier to monitor and track objects or people. For autonomous driving, it helps vehicles recognize and respond to road signs, pedestrians, and other vehicles, which is important for safe navigation. By segmenting video data, we can extract valuable information more efficiently, which is beneficial in various applications.
Applications of Video Segmentation
In Surveillance
In surveillance, video segmentation enhances security by allowing for more detailed monitoring and analysis of footage. Breaking down video into specific segments means that security systems can more easily detect unusual activities or identify suspicious behavior. This leads to better incident response and improved overall security.
In Autonomous Driving
For autonomous vehicles, video segmentation is necessary for real-time decision-making. It helps the vehicle’s AI system recognize and interpret road signs, pedestrians, and other vehicles quickly and accurately. This segmentation allows the vehicle to navigate safely and make timely decisions based on its surroundings.
Introduction to SAM 2
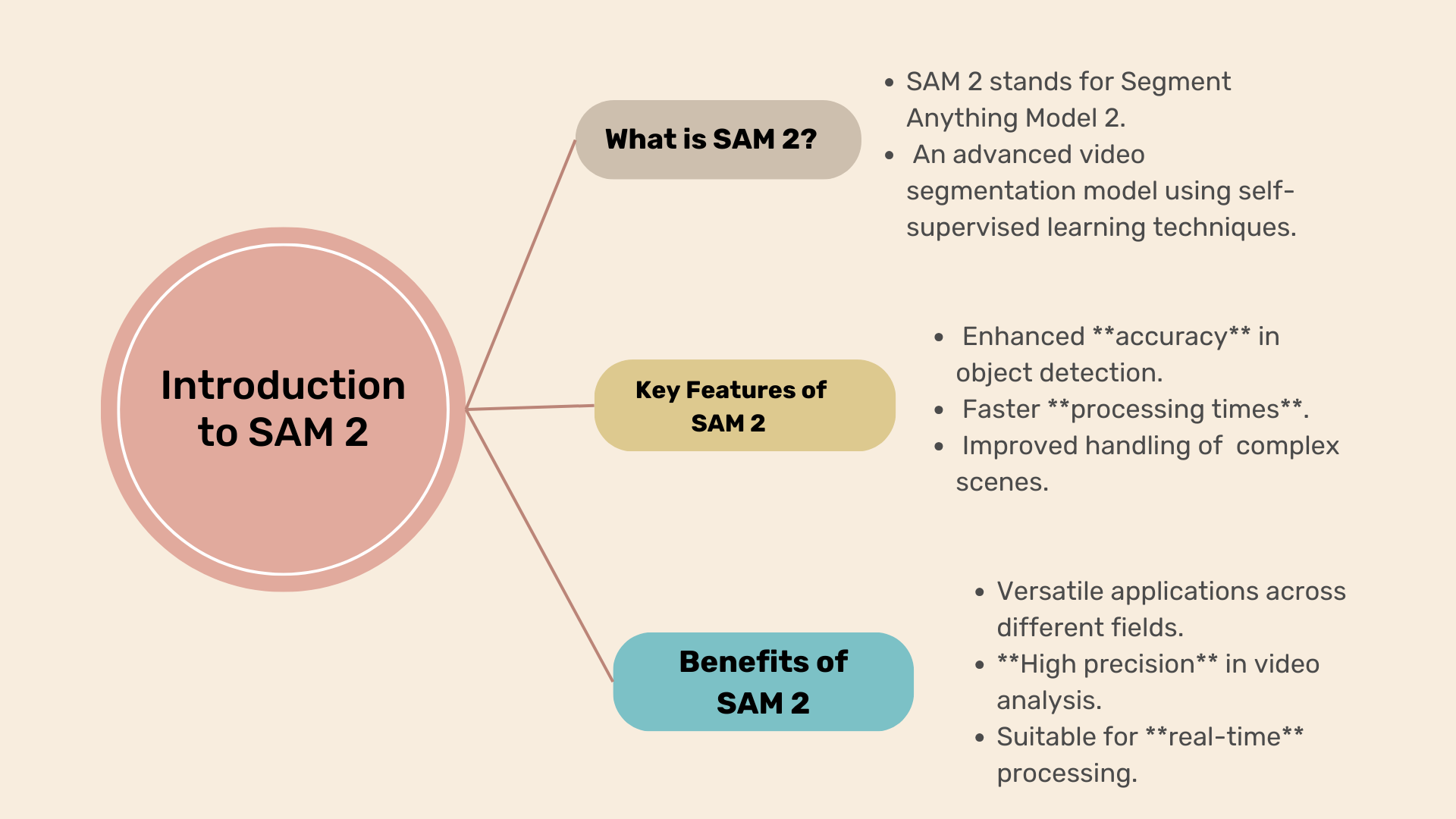
What is SAM (Segment Anything Model)?
SAM (Segment Anything Model) represents a significant leap forward in video and image segmentation technology. SAM is designed to offer advanced tools and methods for segmenting a wide variety of objects with high accuracy. This model makes the task of segmenting video and image data more effective and efficient.
Key Features and Improvements in SAM 2
SAM 2 introduces several enhancements over the previous version. Here are some key improvements:
- Enhanced Accuracy: SAM 2 provides better precision in detecting and segmenting objects, making it more reliable for various applications.
- Faster Processing Times: The new version processes video and image data more quickly, which is crucial for real-time applications.
- Handling Complex Scenes: SAM 2 can manage and segment more intricate and challenging scenes with greater ease, expanding its usefulness in different scenarios.
With these advancements, SAM 2 is set to transform how we approach video segmentation, offering powerful tools for both analysis and real-time processing.
Understanding SAM-2 Architecture
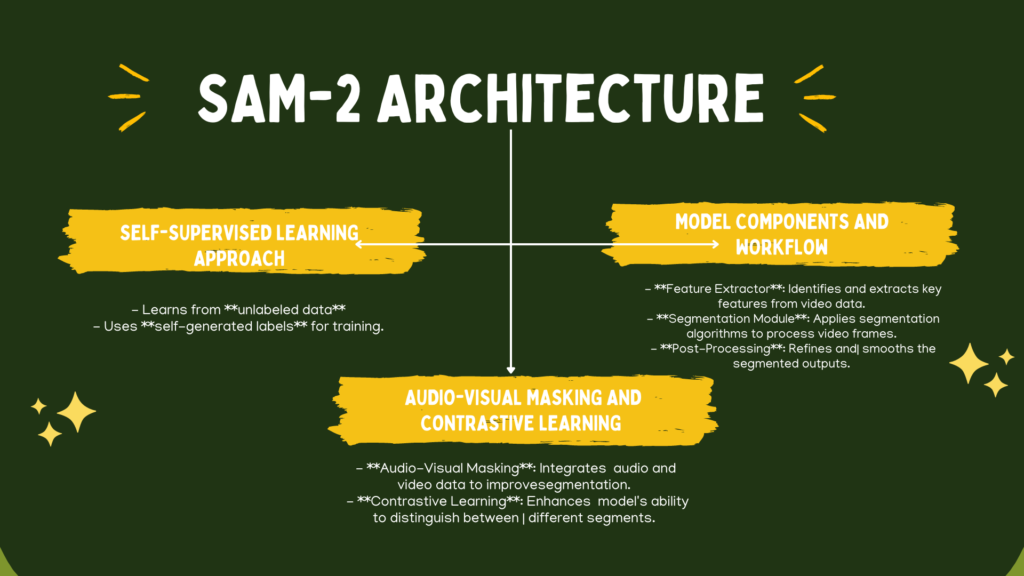
SAM-2 (Self-supervised Audio-visual Masking) represents a significant advancement in video analysis by using cutting-edge learning techniques. To grasp how SAM-2 works, let’s break down its core components.
Overview of SAM-2’s Self-Supervised Learning Approach
Self-supervised learning (SSL) is a type of machine learning where a model learns from data without needing human-labeled examples. Instead of relying on manually added labels, the model creates its own learning signals by setting up small tasks (called pretext tasks) to discover patterns. This allows the model to understand and represent data in a meaningful way, just like how humans learn by recognizing patterns without always being explicitly taught. While SSL is similar to unsupervised learning, it stands out because it generates its own labels, making it more effective in learning useful features.
What is Self-Supervised Learning?
In traditional supervised learning, a model is trained on a dataset where each example is paired with a label or annotation. Self-supervised learning, however, doesn’t require these explicit labels. Instead, it generates its own labels from the data.
For SAM-2, this means learning directly from the video and audio without needing human-labeled data. For example, the model might try to guess missing or hidden parts of a video or audio clip by using the visible and audible parts as clues. By doing this repeatedly, SAM-2 teaches itself important patterns and features, making it more accurate and efficient over time.
Benefits of Self-Supervised Learning in SAM-2
- Less Manual Work: SAM-2 learns from the data on its own, so there’s no need for people to manually label everything. This saves time and effort.
- Better Pattern Recognition: By analyzing the structure of the data, SAM-2 can discover hidden patterns and connections that traditional learning methods might miss.
- More Flexibility: Since SAM-2 isn’t limited to specific labels, it can adapt to different types of data and tasks, making it useful in many situations.
Audio-Visual Masking and Contrastive Learning
SAM-2 employs two advanced techniques—audio-visual masking and contrastive learning—to enhance its performance. Let’s explore these concepts:
Audio-Visual Masking
What It Means: This technique hides parts of the audio or video and trains SAM-2 to guess what’s missing.
How It Works: SAM-2 removes sections of the sound or video and tries to fill in the gaps using the remaining information. For example, if part of the audio is missing, the model looks at the video to figure out what was said.
Why It Helps: This training method makes SAM-2 better at understanding incomplete or noisy data, so it can still perform well even when the input isn’t perfect.
Contrastive Learning
Contrastive learning is a method where the model learns to distinguish between similar and dissimilar data points. In SAM-2, this technique is used to enhance the alignment between audio and visual features.
- How It Works: SAM-2 creates pairs of data points—some are similar (e.g., two frames of the same object) and some are different (e.g., frames of different objects). The model learns to bring similar pairs closer together in feature space and push dissimilar pairs further apart.
- Benefits: Contrastive learning helps SAM-2 to develop a more nuanced understanding of the relationships between audio and visual elements, improving its ability to segment and analyze complex video content.
By combining self-supervised learning with audio-visual masking and contrastive learning, SAM-2 achieves a high level of performance and flexibility in video and audio analysis. These techniques allow SAM-2 to learn from data effectively and adapt to a wide range of scenarios.
Prerequisites
Before you start using SAM-2 (Self-supervised Audio-visual Masking), it’s important to ensure you have the right software and hardware in place. Here’s a detailed guide to help you get everything set up.
Software and Hardware Requirements
Hardware Requirements
To ensure smooth performance, your computer needs enough processing power. Here’s what to look for in each component:
CPU (Processor)
A modern multi-core processor is important for handling SAM-2’s computations. For the best experience, go for:
- Intel i7 or higher
- AMD Ryzen 7 or higher
These processors can handle complex tasks efficiently, preventing lag and slow processing.
GPU (Graphics Card)
If you’re working with large datasets or video processing, a dedicated GPU is a must. A powerful GPU speeds up deep learning tasks and ensures smooth performance. Recommended options:
- NVIDIA RTX 3080 or RTX 3090
- At least 8GB of VRAM to handle heavy workloads.
A strong GPU helps process data faster and prevents slowdowns during training or inference.
RAM (Memory)
SAM-2 requires enough memory to run efficiently.
- Minimum: 16GB RAM – Good for standard use.
- Recommended: 32GB RAM or more – Ideal for working with very large datasets to avoid slow performance.
Storage (Hard Drive)
You’ll need enough space for installing SAM-2, storing datasets, and saving outputs.
- SSD (Solid-State Drive) recommended for faster read/write speeds.
- At least 512GB of storage to ensure you don’t run out of space.
Having the right hardware ensures SAM-2 runs efficiently, processes data quickly, and handles complex tasks without lag.
Software Requirements
To use SAM-2, you’ll need to install specific software and libraries. Here’s what you’ll need:
- Operating System: SAM-2 is compatible with Windows 10, macOS, and Linux. Make sure your operating system is up to date to avoid compatibility issues.
- Python: SAM-2 is built with Python, so you’ll need Python 3.7 or higher installed on your system. Python can be downloaded from the official website.
- Deep Learning Frameworks: SAM-2 relies on deep learning frameworks such as TensorFlow or PyTorch. Ensure you have the latest version of these frameworks installed. You can install them using pip, Python’s package manager.
- Additional Libraries: SAM-2 may require additional Python libraries for data handling and processing. Common libraries include NumPy, Pandas, and OpenCV. These can also be installed via pip.
Necessary Libraries and Tools
To work with SAM-2, you’ll need several key libraries and tools:
- SAM-2: This is the core model for video segmentation. Ensure you have the correct version and that it’s properly configured for your project.
- OpenCV: An open-source computer vision library that provides tools for capturing video, processing images, and more.
- Matplotlib: A plotting library that helps visualize results, such as segmented images or video frames.
Preparing Video Data
To get the most out of SAM-2, you’ll need to prepare your video data properly. This involves collecting and preprocessing the video files and ensuring they are formatted correctly for SAM-2 input. Here’s a step-by-step guide to help you through the process.
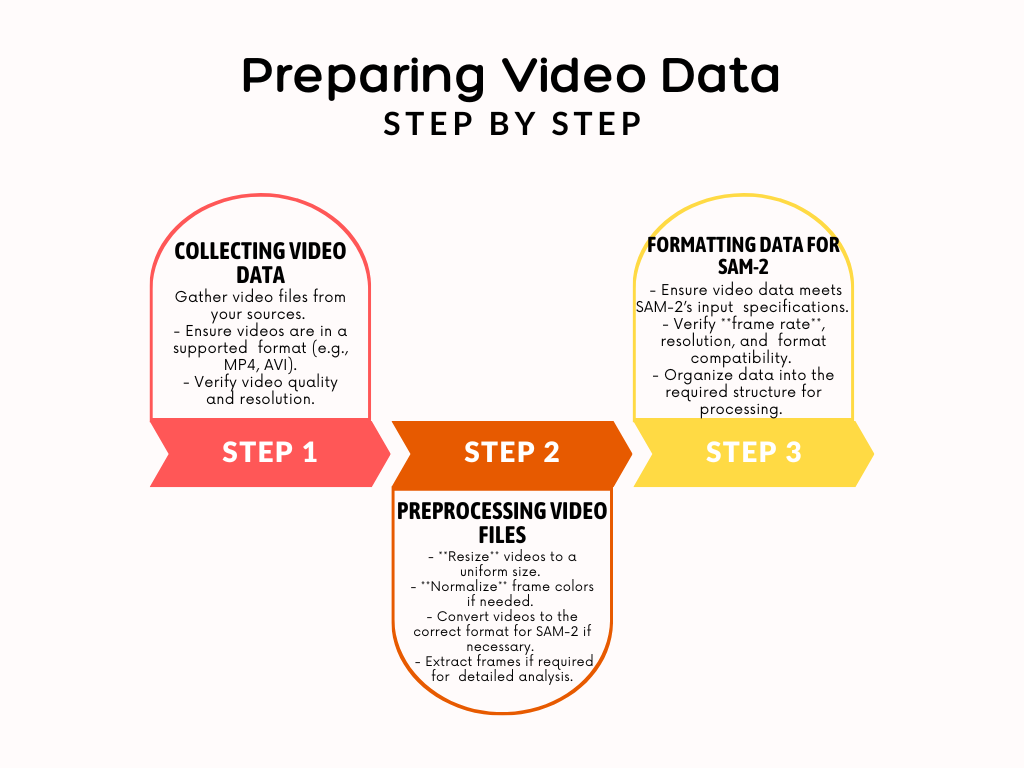
Collecting and Preprocessing Video Data
Collecting Video Data
Before you start, gather all the video files you’ll be working with. These might come from various sources such as:
- Surveillance Cameras: Video footage from security or surveillance systems.
- Public Datasets: Videos from open-access databases for research or development.
- Custom Captures: Videos you record yourself, customized to specific needs or experiments.
Ensure that your video data covers the range of scenarios you’re interested in analyzing. For example, if you’re working on autonomous driving, you might need videos of different driving conditions and environments.
Preprocessing Video Data
Once you have your video files, the next step is to preprocess them to ensure they are in the best format for SAM-2. This process includes:
- Video Quality: Check the quality of your videos. If they are low-resolution or noisy, consider enhancing the quality using video editing software or filtering techniques. High-quality videos lead to better results.
- Trimming and Splitting: Depending on your needs, you might need to trim or split your video files. For instance, if your videos are too long, you can divide them into smaller segments to make processing more manageable.
- Frame Extraction: SAM-2 processes video data frame by frame. You may need to extract individual frames from your video if SAM-2 requires frame-level input. Tools like FFmpeg can be used to convert videos into a series of images.
- Normalizing Data: Ensure that the video data is consistent. This includes checking for uniform frame rates, resolution, and color formats. Consistent data helps SAM-2 perform better and more accurately.
Formatting Data for SAM-2 Input
File Formats
SAM-2 typically requires video data in specific formats. Common formats include:
- MP4: A widely used video format that is generally compatible with many tools.
- AVI: Another common format, though it may produce larger files compared to MP4.
- Image Sequences: If SAM-2 processes video as a series of images, make sure your frames are saved in a format like JPEG or PNG.
Ensure that your files are saved in the correct format as required by SAM-2. You can convert video files to the desired format using tools like FFmpeg or HandBrake.
Organizing Data
Arrange your video files in a well-structured directory. You can create a main folder and organize subfolders based on categories or scenarios. This setup makes it easier to find and access your data when configuring SAM-2.
- Example Directory Structure:
/data
/training
/scenario1
video1.mp4
video2.mp4
/scenario2
video1.mp4
/validation
/scenario1
video1.mp4
Metadata and Annotations
If SAM-2 needs metadata or annotations, make sure to include them. Metadata can include details like the video’s source, recording date, or conditions. Annotations might involve labels for objects or actions within the video, depending on your project requirements.
By following these steps to collect, preprocess, and format your video data, you’ll be ready to use SAM-2 effectively. Proper preparation ensures that your data is in the best shape for accurate and meaningful analysis. next let’s explore the complete code for Real-Time Video Segmentation
Example Code for Real-Time Video Segmentation
Installing Required Libraries
To set up your environment, you need to install the required libraries. Here’s how you can do it:
Installation Commands and Setup
Open your terminal or command prompt and use the following commands to install the necessary libraries:
pip install opencv-python matplotlib
Explanation of the Code
pip install opencv-python:- This command installs the OpenCV library for Python. OpenCV provides powerful tools for computer vision tasks, including video capture, image processing, and object detection.
- OpenCV is important for handling video streams and performing real-time image manipulations, which are crucial for video segmentation tasks.
pip install matplotlib:- This command installs Matplotlib, a plotting library used to create visualizations in Python. It helps in plotting graphs and displaying images.
- Matplotlib is useful for visualizing the results of segmentation, such as overlaying segmentation masks on video frames or displaying segmented images.
Additional Setup
Once you’ve installed the libraries, make sure that:
- SAM-2: Follow any specific setup instructions provided with SAM-2. This may include configuring paths or setting environment variables.
- Library Compatibility: Ensure that the installed versions of OpenCV and Matplotlib are compatible with SAM-2. Sometimes, library versions may need to match specific requirements.
By following these steps, you’ll have your system ready for working with SAM-2 and performing video segmentation tasks.
Must Read
- Why sorted() Is Safer Than list.sort() in Production Python Systems
- Monotonic Sequence in Python: 7 Practical Methods With Edge Cases, Interview Tips, and Performance Analysis
- How to Check if Dictionary Values Are Sorted in Python
- Check If a Tuple Is Sorted in Python — 5 Methods Explained
- How to Check If a List Is Sorted in Python (Without Using sort()) – 5 Efficient Methods
Loading SAM-2 Model
Loading the SAM-2 model is an important step for performing video segmentation tasks. Here’s a detailed guide on how to obtain and load the SAM-2 model, along with example code to help you get started.
How to Obtain and Load the SAM-2 Model
Obtaining the SAM-2 Model
- Download the Model:
- Official Sources: Visit the official website or repository where SAM-2 is hosted. This could be a research paper’s supplementary materials, a GitHub repository, or a dedicated model distribution site.
- Pretrained Models: Look for pretrained versions of SAM-2. These models are already trained on large datasets and can be used directly for segmentation tasks.
- Save the Model:
- Once downloaded, save the SAM-2 model file to a known location on your computer. This file is typically in a format compatible with the SAM-2 library, such as a
.pthfile for PyTorch models.
- Once downloaded, save the SAM-2 model file to a known location on your computer. This file is typically in a format compatible with the SAM-2 library, such as a
Loading the SAM-2 Model
Here’s an example of how to load the SAM-2 model using Python code:
Example Code for Loading SAM-2
from sam2 import SAMModel
# Load SAM-2 model
model = SAMModel.load_pretrained('path_to_sam2_model')
Explanation of the Code
- Import the SAM-2 Library:
from sam2 import SAMModel
- This imports the
SAMModelclass from thesam2library.SAMModelis the class responsible for managing the SAM-2 model, including loading and using it for segmentation tasks. - It’s important to import the right class to properly interact with the SAM-2 model and use its features.
2. Load the SAM-2 Model
model = SAMModel.load_pretrained('path_to_sam2_model')
SAMModel.load_pretrained: This method is used to load a pretrained version of the SAM-2 model. It reads the model file from the specified path and prepares it for use.'path_to_sam2_model': Replace this placeholder with the actual path to your SAM-2 model file. This should be the path where you saved the model file after downloading it.model: Themodelvariable now stores the SAM-2 instance, making it ready for use. You can use it to perform segmentation tasks or adjust the model’s settings as needed.
Tips for Loading the Model
- Check Compatibility: Ensure that the SAM-2 version you downloaded is compatible with your current setup and the library version you are using.
- Verify File Path: Double-check the file path to make sure it points to the correct location of your SAM-2 model file.
- Error Handling: If you encounter any errors while loading the model, verify that the
sam2library is properly installed and that the model file is not corrupted.
Processing Video Frames
To use SAM-2 effectively, you’ll need to handle video frames properly. This involves two main steps: reading video data and preprocessing frames. Here’s how you can manage each step:
Reading Video Data
To start working with video frames, you first need to extract them from a video file. This is where OpenCV comes in handy. OpenCV is a powerful library that helps with video and image processing tasks.
Example Code for Video Frame Extraction
Here’s a simple example showing how to use OpenCV to extract frames from a video:
import cv2
def read_video(video_path):
# Open the video file
cap = cv2.VideoCapture(video_path)
frames = []
# Loop through the video file frame by frame
while True:
ret, frame = cap.read()
# Check if the frame was successfully read
if not ret:
break
frames.append(frame)
# Release the video capture object
cap.release()
return frames
Explanation of the Code
- Import OpenCV:
import cv2
- This imports the OpenCV library, which provides functions for reading and processing video files.
2. Define the read_video Function:
def read_video(video_path):
- This function takes a video file path as input and returns a list of frames extracted from the video.
3. Open the Video File:
cap = cv2.VideoCapture(video_path)
cv2.VideoCaptureopens the video file specified byvideo_path. It creates a video capture objectcapthat allows reading frames from the video.
4. Read Frames in a Loop:
while True:
ret, frame = cap.read()
if not ret:
break
frames.append(frame)
- The loop reads frames one by one from the video.
retindicates if the frame was successfully read. If not (retisFalse), the loop breaks. Each successfully read frame is added to theframeslist.
5. Release the Video Capture Object:
cap.release()
- Releases the video capture object to free up resources once all frames have been read.
6. Return Frames:
return frames
- The function returns the list of frames extracted from the video.
Preprocessing Frames for SAM-2
Once you have the frames, they need to be preprocessed to fit the requirements of SAM-2. This often involves steps like resizing and normalization.
Necessary Preprocessing Steps
- Resizing: Ensures that all frames have the same dimensions, which is important for consistent input to the SAM-2 model.
- Normalization: Adjusts the pixel values to a standard range or format that SAM-2 expects. This involves scaling the pixel values to the range [0, 1] or [-1, 1].
Example Code for Preprocessing
Here’s a basic example of how you might preprocess frames:
import cv2
import numpy as np
def preprocess_for_sam2(frame):
# Resize frame to a fixed size (e.g., 224x224 pixels)
resized_frame = cv2.resize(frame, (224, 224))
# Normalize pixel values to the range [0, 1]
normalized_frame = resized_frame / 255.0
# Convert to float32 (if required by SAM-2)
processed_frame = np.float32(normalized_frame)
return processed_frame
Explanation of the Code
- Resize the Frame:
resized_frame = cv2.resize(frame, (224, 224))
- This resizes the frame to 224×224 pixels. SAM-2 may require specific input dimensions, so resizing ensures consistency.
2. Normalize Pixel Values:
normalized_frame = resized_frame / 255.0
- Divides the pixel values by 255 to scale them to the range [0, 1]. This step helps in aligning the pixel values with the expected input range for SAM-2.
3. Convert to Float32:
processed_frame = np.float32(normalized_frame)
- Converts the normalized frame to a
float32type. This might be necessary for compatibility with SAM-2, which often expects floating-point inputs.
4. Return the Processed Frame:
return processed_frame
- The function returns the preprocessed frame, ready for input into SAM-2.
Segmenting Video Frames
To use SAM-2 for video segmentation, you’ll need to perform segmentation on each frame of your video and then handle the segmented results. Let’s walk through each step in detail.
Performing Segmentation
To segment video frames, follow these steps:
- Apply SAM-2 to Each Frame:
- For each frame in your video, you’ll preprocess the frame and then apply SAM-2 to perform segmentation.
Example Code for Segmentation
Here’s a simple example to show how you can use SAM-2 to segment each frame of a video:
def segment_frame(frame, model):
# Preprocess the frame for SAM-2
preprocessed_frame = preprocess_for_sam2(frame)
# Apply SAM-2 model to the preprocessed frame
segmentation = model.segment(preprocessed_frame)
return segmentation
Explanation of the Code
- Preprocess the Frame:
preprocessed_frame = preprocess_for_sam2(frame)
This step ensures the frame is resized and normalized according to the requirements of SAM-2. This preparation is crucial for obtaining accurate segmentation results.
2. Apply SAM-2 Model:
segmentation = model.segment(preprocessed_frame)
The model.segment function applies SAM-2 to the preprocessed frame. It generates a segmentation mask or labels for the objects in the frame.
3. Return the Segmentation:
return segmentation
The function returns the segmented frame, which includes the results of SAM-2’s analysis.
Handling Segmentation Results
Once you have segmented the frames, you’ll need to manage and store these results. This might involve saving them to disk or displaying them in real-time.
Example Code for Processing and Storing Results
Here’s how you can process and store the segmented frames:
def process_video(video_path, model):
# Read the video and extract frames
frames = read_video(video_path)
segmented_frames = []
# Process each frame
for frame in frames:
segmentation = segment_frame(frame, model)
segmented_frames.append(segmentation)
# Optionally display the segmented frame
cv2.imshow('Segmented Frame', segmentation)
cv2.waitKey(1) # Wait for 1 millisecond to display the frame
# Close the display window
cv2.destroyAllWindows()
return segmented_frames
Explanation of the Code
- Read Video and Extract Frames:
frames = read_video(video_path)
This function call extracts all frames from the video file specified by video_path.
2. Process Each Frame:
for frame in frames:
segmentation = segment_frame(frame, model)
segmented_frames.append(segmentation)
This loop processes each frame by calling segment_frame, which applies SAM-2 segmentation. Each segmented frame is then added to the segmented_frames list for later use.
3. Display the Segmented Frame:
cv2.imshow('Segmented Frame', segmentation)
cv2.waitKey(1)
cv2.imshow displays each segmented frame in a window titled ‘Segmented Frame’. cv2.waitKey(1) waits for a brief moment (1 millisecond) to update the display. This is useful for real-time visualization.
4. Close the Display Window:
cv2.destroyAllWindows()
Closes all OpenCV display windows after processing all frames.
5. Return Segmented Frames:
return segmented_frames
The function returns the list of segmented frames, which you can use for further analysis, saving, or visualization.
Post-Processing and Visualization
After segmenting video frames with SAM-2, you may want to refine the results and visualize them. This involves post-processing to smooth out results and visualize the segmented frames. Here’s a detailed guide on how to handle these tasks:
Post-Processing Techniques
Post-processing helps to refine segmentation results, making them more accurate and visually appealing. Here are few Common techniques:
Temporal Smoothing and Consistency
Temporal smoothing helps in reducing jitter and ensuring smooth transitions between frames. This is useful for video data where frame-to-frame consistency is important.
Handling Noisy or Incomplete Segmentations
Sometimes, the segmentation might have noise or incomplete results due to various factors like low quality of video or model limitations. Post-processing can help clean up these issues.
Example Code for Post-Processing
Here’s a basic example of a post-processing function:
def post_process_segmentation(segmented_frames):
# Implement post-processing techniques such as temporal smoothing here
# For simplicity, this example does not include actual processing
return segmented_frames
Explanation of the Code
- Define the
post_process_segmentationFunction:
def post_process_segmentation(segmented_frames):
This function takes a list of segmented frames and applies post-processing techniques to refine them.
2. Implement Post-Processing:
# Implement post-processing techniques such as temporal smoothing here
This placeholder is where you would add your post-processing logic, such as smoothing techniques or methods to handle noisy segments.
3. Return Processed Frames:
return segmented_frames
- The function returns the refined list of segmented frames. You can further use these processed frames for visualization or analysis.
Visualizing Segmentation Results
Visualization allows you to view the segmented frames and verify the results. This can be done in real-time or by saving the results for further analysis.
Displaying Segmented Frames
To display each segmented frame, you can use OpenCV’s imshow function.
Saving Results for Further Analysis
You might also want to save the segmented frames as image files or a video file for later review or analysis.
Example Code for Visualization
Here’s how you can visualize and save the segmented frames:
def visualize_segmentation(segmented_frames):
for frame in segmented_frames:
cv2.imshow('Segmented Frame', frame)
cv2.waitKey(1) # Display each frame for 1 millisecond
cv2.destroyAllWindows() # Close all OpenCV windows
Explanation of the Code
- Define the
visualize_segmentationFunction:
def visualize_segmentation(segmented_frames):
This function takes a list of segmented frames and displays them one by one.
2. Display Each Frame:
for frame in segmented_frames:
cv2.imshow('Segmented Frame', frame)
cv2.waitKey(1)
The loop iterates through each segmented frame. cv2.imshow displays the frame in a window titled ‘Segmented Frame’. cv2.waitKey(1) waits for 1 millisecond before showing the next frame, allowing for real-time visualization.
3. Close All OpenCV Windows:
cv2.destroyAllWindows()
Closes all OpenCV display windows once all frames have been shown.
Post-Processing: Refine segmented frames with techniques like temporal smoothing and noise reduction.
Visualization: Use OpenCV to display each segmented frame in real-time and optionally save them for further analysis.
Evaluating SAM-2 Performance
After training SAM-2 for video segmentation, it’s crucial to evaluate its performance to ensure it meets your expectations. This involves using specific metrics to assess how well the model is performing and analyzing its results to make any necessary improvements. Here’s a step-by-step guide to help you with this process:
Metrics for Evaluating Video Segmentation Performance
To gauge the effectiveness of SAM-2’s video segmentation, you’ll need to use several key metrics. These metrics provide insights into how accurately the model is segmenting the video data.
Key Metrics for Video Segmentation
- Intersection over Union (IoU):
- Definition: IoU measures how much the predicted segmentation overlaps with the actual (ground truth) segmentation. It’s calculated by comparing the area of overlap to the total combined area of both segments.
- Why It Matters: A higher IoU means the model’s predictions are more accurate. If IoU is high, the predicted segment closely matches the actual object, showing that the model is performing well.
- Precision:
- Definition: Precision measures how many of the segments the model predicts as positive are actually correct. It focuses on how accurate the model is when it says something is a positive segment.
- Why It Matters: High precision means that the model is good at correctly identifying the segments it labels as positive, reducing false positives.
- Recall:
- Definition: Recall measures how many of the actual positive segments the model correctly identifies. It shows how well the model detects all the relevant segments.
- Why It’s Important: A higher recall means the model is less likely to miss important segments, reducing false negatives (missed detections).
- F1 Score:
- Definition: The F1 Score combines precision and recall into a single metric by calculating their harmonic mean. It helps balance both accuracy and completeness.
- Why It Matters: A higher F1 Score means the model performs well in both identifying relevant segments (recall) and avoiding false positives (precision). This is especially useful when working with imbalanced datasets.
- Mean Average Precision (mAP):
- Definition: mAP calculates the average precision at different recall levels, giving a more complete picture of the model’s accuracy. It is especially useful for evaluating performance across multiple classes or categories.
- Why It Matters: A higher mAP means the model consistently performs well across different types of objects or segments, making it a reliable measure of overall accuracy.
Analyzing SAM-2’s Results and Fine-Tuning
Once you have your performance metrics, it’s time to analyze SAM-2’s results and make any necessary adjustments.
Analyzing Results
- Review Performance Metrics: Examine the IoU, precision, recall, F1 Score, and mAP values to understand how well SAM-2 is performing. Look for areas where the model excels and where it is lacking.
- Visual Inspection: In addition to numerical metrics, visually inspect the segmented video outputs. This helps in identifying any specific issues or patterns that metrics alone might not reveal.
- Error Analysis: Identify any common errors or patterns in the incorrect segmentations. For instance, if the model frequently misidentifies certain objects or areas, it may indicate a need for more training data or better annotations.
Fine-Tuning SAM-2
- Adjust Hyperparameters: Based on the performance analysis, tweak hyperparameters such as learning rate, batch size, and the number of epochs. Small adjustments can often lead to significant improvements in performance.
- Refine Data: If the model is struggling with specific segments or types of data, consider adding more examples of those cases to your training dataset. Data augmentation techniques can also help improve model performance.
- Reconfigure Model Settings: If necessary, revisit the configuration settings for SAM-2. This might include adjusting input formats, data augmentation strategies, or evaluation criteria to better align with your segmentation goals.
- Retrain the Model: After making adjustments, retrain SAM-2 on your dataset. This iterative process helps in fine-tuning the model’s performance and ensuring it meets your needs.
- Validate Improvements: After fine-tuning, re-evaluate SAM-2 using the same metrics and analysis techniques. Compare the new results with previous ones to ensure that the adjustments have led to improvements.
Benefits of SAM-2
- More Accurate Results: SAM-2 learns directly from data without needing a lot of labeled examples. This helps it better recognize and separate objects and sounds in a video.
- Combines Audio and Video: Many models process audio and video separately, but SAM-2 blends both to get a deeper understanding of what’s happening. This leads to better analysis since both sound and visuals work together.
- Works in Different Situations: SAM-2 can handle noisy backgrounds, fast-moving scenes, and different audio conditions without losing accuracy. It adjusts its methods to keep performance high.
- Less Manual Work: Since SAM-2 learns on its own, it doesn’t need people to label data manually. This makes it faster and easier to train, saving time and effort.
Challenges and Considerations of SAM-2
When working with SAM-2 for video segmentation, you might encounter several challenges. Here’s how to tackle them:
Handling Fast-Moving Objects
Fast-moving objects can be tricky for segmentation due to motion blur and rapid changes between frames. To improve accuracy, consider the following techniques:
- Motion Compensation: Stabilize video frames to reduce motion blur. This involves aligning frames based on their movement before applying SAM-2, which helps the model segment fast-moving objects more accurately.
- Higher Frame Rate: Use videos with higher frame rates to minimize motion blur. If you’re working with a lower frame rate, you might interpolate additional frames to enhance detail.
- Model Adaptation: Fine-tune SAM-2 with datasets that feature fast-moving objects. Training the model on such data helps it better handle rapid motion.
Managing Large Video Files
Processing large video files can be challenging due to their size. To handle this efficiently:
- Chunk Processing: Break the video into smaller chunks. Process each chunk separately to manage memory and reduce processing load. This avoids overwhelming your system with too much data at once.
- Frame Skipping: Skip frames at regular intervals to lessen the total number of frames processed. This is useful when you don’t need to analyze every frame but still want to capture the overall content.
- Parallel Processing: Use multiple threads or processes to handle different parts of the video simultaneously. This speeds up the processing by distributing the workload.
Temporal Consistency Issues
Ensuring consistency across frames is crucial for accurate object tracking. To maintain consistency:
- Temporal Smoothing: Apply smoothing techniques to reduce jitter and inconsistencies between frames. This involves averaging results over several frames to create a more stable segmentation.
- Object Tracking Algorithms: Integrate tracking algorithms like Kalman filters or optical flow with SAM-2. These methods help in keeping track of objects across frames, improving consistency in segmentation.
- Regularization Techniques: Use regularization to penalize abrupt changes in segmentation results. This encourages smoother transitions between frames and enhances overall tracking.
Conclusion
Key Takeaways
In this blog post, we talked about SAM-2 and how it helps with video segmentation. Here’s a quick summary:
What is SAM-2?
SAM-2 (Segment Anything Model 2) is an advanced tool that makes video segmentation more accurate and efficient. It uses smart techniques like self-supervised learning and audio-visual masking to improve results.
What is Video Segmentation?
Video segmentation means dividing a video into different parts, such as objects, actions, or scenes. This is important for tasks like security monitoring, self-driving cars, and video editing.
Challenges and How SAM-2 Solves Them
Video segmentation isn’t always easy. Some common problems include:
- Fast-moving objects that blur or disappear
- Large video files that take up too much space
- Keeping objects consistent across different frames
SAM-2 tackles these challenges using methods like motion tracking and smoothing out frames to keep things steady.
What’s Next for Video Segmentation?
The future of video segmentation looks exciting! Here are some possible improvements:
Smarter Algorithms: Future versions of SAM-2 might get even better at recognizing objects and handling complex scenes.
Faster Processing: As video quality improves, models need to work faster without using too much computer power. New updates will focus on speed and efficiency.
Better AI Integration: SAM-2 could be combined with other AI and machine learning tools to make automatic decisions in real time—useful for things like live surveillance and self-driving cars.
Real-Time Video Segmentation: As computers get stronger, analyzing videos instantly will become easier, helping industries that need fast and accurate results.
Mixing Video with Other Data: Future models might combine video with audio and sensor data for a deeper understanding of what’s happening. This could improve things like speech recognition and action detection in videos.
SAM-2 is already a powerful tool, but there’s still room for growth. As technology evolves, video segmentation will only get better!
References and Further Reading
Documentation and Resources
1. Links to SAM-2 Documentation
To fully understand and utilize SAM-2, it’s essential to refer to its official documentation. This resource will provide you with detailed information on how to install, configure, and use SAM-2 effectively.
- Official SAM-2 Documentation: Visit the SAM-2 official documentation for comprehensive guidelines and examples on how to implement and optimize SAM-2 for video segmentation. This documentation covers installation instructions, API references, and best practices.
2. Relevant Research Papers and Articles
For a deeper dive into the technology behind SAM-2 and its underlying principles, exploring research papers and academic articles is beneficial:
- “Segment Anything: Towards Universal Image Segmentation”: This paper introduces the core concepts and innovations of SAM models. Read the paper here.
- “Self-Supervised Learning for Video Analysis”: Explore how self-supervised learning techniques, such as those used in SAM-2, contribute to video analysis. Read the paper here.
- “Advanced Video Segmentation Techniques and Applications”: An overview of modern techniques in video segmentation and their applications in various fields. Read the paper here.
Additional Tools and Libraries
To complement SAM-2, several other libraries and frameworks can enhance your video segmentation workflow:
1. OpenCV
- Overview: OpenCV is a popular library for computer vision tasks, including video processing and segmentation. It provides a range of tools for handling video frames, performing image transformations, and more.
- Official Website: OpenCV
2. TensorFlow and PyTorch
- Overview: Both TensorFlow and PyTorch are widely used deep learning frameworks that offer extensive support for building and training custom video segmentation models. They provide tools and libraries for implementing advanced segmentation algorithms and integrating them with SAM-2.
- TensorFlow: TensorFlow
- PyTorch: PyTorch
FAQs
1. What is SAM-2 and how does it work for video segmentation?
SAM-2, or Segment Anything Model 2, is an advanced model designed for high-precision video segmentation. It uses self-supervised learning techniques to segment video frames into meaningful parts, such as objects or scenes. SAM-2 processes each frame of the video, applies its segmentation algorithms, and provides segmented outputs based on the trained model.
2. How do I get started with SAM-2?
To get started with SAM-2, follow these steps:
- Install SAM-2: Obtain the SAM-2 package and install it using pip or another package manager.
- Set Up Your Environment: Ensure you have the necessary libraries, such as OpenCV, installed in your development environment.
- Load the Model: Use the provided functions to load the pre-trained SAM-2 model.
- Process Video Frames: Read and preprocess your video data, then apply SAM-2 to segment each frame.
- Evaluate Results: Review the segmented outputs and fine-tune the model if needed.
3. How do I handle large video files with SAM-2?
For large video files:
- Chunk Processing: Break the video into smaller segments and process each chunk separately.
- Frame Skipping: Skip frames to reduce the number of frames processed if full detail is not required.
- Efficient Storage: Use efficient storage and loading methods to manage large files without overwhelming system memory.
4. Can SAM-2 be used in real-time video applications?
SAM-2 can be adapted for real-time applications by optimizing processing speed and integrating it with efficient video capture and display systems. However, real-time performance will depend on system capabilities and video resolution.

![Linear Algebra for Data Science: The Complete Guide [Part 1]](https://emitechlogic.com/wp-content/uploads/2024/10/Linear-Algebra-for-Data-Science-768x768.webp "Linear Algebra for Data Science: The Complete Guide [Part 1]")




Leave a Reply