

Inside the Magic: How Transformers and Large Language Models Revolutionize AI
Introduction to Transformers and Large Language Models (LLMs)
Let’s talk about Transformers and Large Language Models (LLMs). Transformers are a type of AI model that has changed the game for how computers deal with language. Before transformers, most NLP models used simpler methods, which meant they couldn’t handle language tasks very well. Transformers changed that by helping AI understand context and process lots of text more efficiently. This means AI can now tackle more complex language tasks with greater accuracy.
Large Language Models (LLMs) use the transformer architecture. They’re like super-smart text generators that can write essays, answer questions, and even spin up stories. They’re trained on massive amounts of data, so they can create text that feels natural and flows well.
Transformers and LLMs are major breakthroughs in NLP. They help AI understand and interact with human language much better, making it possible to handle more complex tasks and provide more accurate and useful responses.
Before we enter into Transformers and LLMs, let’s take a moment to review the basics of AI and NLP.
Overview of AI and NLP
Artificial Intelligence (AI) is all about making computers and machines smart enough to do things that normally need human brains. Think of it like this: AI helps computers understand what we say, make choices, and even get the hang of our everyday language. It’s becoming a big part of our lives—whether it’s the virtual assistants we talk to, or the automated customer support that helps us out.
Natural Language Processing (NLP) is a part of AI that’s all about helping computers chat with us like real people. It lets computers understand, interpret, and generate human language in a way that actually makes sense. For example, NLP powers chatbots that can answer your questions or translate text between languages.
What are Transformers?
Definition
Transformers are a special kind of neural network architecture designed to handle sequential data, like sentences or time series, more effectively. They use a method called self-attention to focus on different parts of the input data, making it easier to understand complex patterns and relationships.
Historical Context
Transformers were introduced in the groundbreaking paper “Attention is All You Need” by Vaswani et al. in 2017. This paper changed the way we approach tasks in natural language processing (NLP) and machine learning. The introduction of transformers marked a significant shift from previous models and set the stage for many advancements in AI.
Key Features
- Self-Attention Mechanism: This feature allows transformers to focus on various parts of the input sequence. For instance, in a sentence, self-attention helps the model pay attention to relevant words that might be far apart from each other. This makes it easier to understand the overall meaning.
- Parallelization: Unlike traditional Recurrent Neural Networks (RNNs), which process data sequentially, transformers can process data in parallel. This means they can handle sequences much faster and more efficiently. This speed and efficiency are one reason why transformers have become so popular in building large language models (LLMs).
In summary, transformers are key to understanding how large language models work. Their ability to manage complex sequences and process data quickly makes them essential for modern AI systems.
Why Transformers Matter
Advantages
Handling Long-Range Dependencies: Transformers are great at keeping track of information spread out over long sequences. Unlike older models like Recurrent Neural Networks (RNNs), which can have trouble remembering details from far back in a sequence, transformers can maintain important context over longer distances. This is super helpful for understanding complex sentences or entire documents.
Scalability: Transformers can be scaled up to create very large models like GPT-3 and BERT. This means they can handle massive amounts of data and tackle more complicated tasks. Their ability to grow and adapt makes them perfect for building powerful large language models (LLMs).
Versatility: Transformers aren’t just good at one thing—they’re versatile. They can be used for a bunch of different NLP tasks, like translation, summarization, and answering questions. This flexibility means they can improve language understanding across a wide range of applications.
Impact on NLP
Transformers have truly changed the game in language processing. They’ve made a huge difference in performance on various tasks and benchmarks. Before transformers, many NLP models struggled with complexity and efficiency. Now, thanks to transformers, AI systems can handle language tasks with much more accuracy and effectiveness.
How Transformers Work
Encoder-Decoder Architecture
Transformers use a structure called the encoder-decoder architecture. This design helps them process and generate sequences of data, like sentences, in a smart and efficient way.
- Encoder: The encoder’s job is to convert input sequences into representations that capture the meaning and context. For example, if you input a sentence, the encoder breaks it down and creates a detailed, context-aware version of that sentence. This representation holds all the important information from the input.
- Decoder: The decoder takes the representations created by the encoder and uses them to generate output sequences. For instance, if the task is to translate a sentence into another language, the decoder uses the encoded information to produce the translated sentence.

When discussing LLM transformer architecture and the architecture of LLMs, it’s important to understand this encoder-decoder setup. It shows how transformers handle complex tasks by breaking them into manageable parts and then generating accurate results.
In summary, the encoder-decoder architecture is central to how transformers work. It allows them to efficiently process input data and generate meaningful output, making them powerful tools for various natural language processing tasks.
Attention Mechanism
Self-Attention
The self-attention mechanism is a key feature of transformers. It helps the model understand which parts of the input are important relative to each other. Here’s how it works:
- Computes a Weighted Sum: Self-attention calculates a weighted sum of input tokens. Each token in a sequence gets a weight based on how relevant it is to other tokens. For example, in a sentence, self-attention helps the model focus on important words by giving them higher weights.
Multi-Head Attention
Multi-head attention is an extension of self-attention. Instead of using just one set of weights, it uses multiple attention heads. Each head focuses on different types of relationships between tokens. This means the model can capture various aspects of the input data at once.
- Captures Different Relationships: By using several attention heads, multi-head attention can learn different kinds of connections between words or tokens. This makes the model more robust and capable of understanding complex patterns.

When exploring Transformers LLM paper and Transformers and LLMs in machine learning, understanding the attention mechanism is essential. It’s a fundamental part of how transformers process and generate language, making them effective for various machine learning tasks.
In summary, the attention mechanism, including self-attention and multi-head attention, is central to the power of transformers. It enables these models to focus on relevant parts of the input and capture different relationships, which enhances their performance in language tasks.
Example: Basic Transformer in PyTorch
Let’s walk through a simple example of creating a transformer model in PyTorch. We’ll cover the main steps: importing libraries, defining the model, creating a dataset, and training the model. By the end, you’ll have a clear idea of how to work with transformers and large language models (LLMs).
1: Import Libraries
To start building our transformer model, we need to bring in some libraries. These libraries are like tools in a toolbox—they help us do different tasks without having to build everything from scratch. Here’s the code we’ll use to import the necessary libraries:
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader, Dataset
What Each Library Does
- torch
torchis the main library in PyTorch, which is a popular framework for machine learning. It’s like the base tool that we use for almost everything in our project. Withtorch, we can create and manipulate tensors, which are multi-dimensional arrays that store our data. - torch.nn
torch.nnis a module in PyTorch that helps us build neural networks. It provides classes and functions to create layers and architectures for our models. In our case, we need this to build the layers of our transformer model. - torch.optim
torch.optimstands for “torch optimizers.” Once we have our model, we need to train it, which means we have to adjust its parameters (like weights) to make it better at its task. Optimizers are algorithms that help us do this. Thetorch.optimmodule includes several optimization algorithms that we can use to train our model. - torch.utils.data
torch.utils.datais a module that helps us handle data. It provides tools to load and process our data efficiently. Specifically, it includes:- DataLoader: A class that makes it easy to load batches of data for training and testing.
- Dataset: A class that helps us organize our data and make it compatible with DataLoader.
2. Defining the Transformer Model
Now that we have our tools ready, it’s time to build our transformer model. Think of this step as creating a blueprint for a new machine. This machine (our model) will take some input, process it, and give us a useful output.
Here’s the code for defining our transformer model:
class TransformerModel(nn.Module):
def __init__(self, input_dim, output_dim, n_heads, n_layers):
super(TransformerModel, self).__init__()
self.encoder_layer = nn.TransformerEncoderLayer(input_dim, n_heads)
self.transformer_encoder = nn.TransformerEncoder(self.encoder_layer, n_layers)
self.fc = nn.Linear(input_dim, output_dim)
def forward(self, src):
src = self.transformer_encoder(src)
output = self.fc(src)
return output
Breaking Down the Code
Class Definition
class TransformerModel(nn.Module):
We’re creating a new class called TransformerModel. In Python, a class is like a blueprint for creating objects. Here, TransformerModel is a blueprint for our transformer model. It inherits from nn.Module, which is a base class for all neural network modules in PyTorch.
Initialization
def __init__(self, input_dim, output_dim, n_heads, n_layers):
super(TransformerModel, self).__init__()
This is the __init__ method, which initializes our model. It takes a few parameters:
input_dim: The size of the input data.output_dim: The size of the output data.n_heads: The number of attention heads in the encoder.n_layers: The number of encoder layers.
The super function calls the initializer of the parent class (nn.Module), making sure our model is set up correctly.
Encoder Layer
self.encoder_layer = nn.TransformerEncoderLayer(input_dim, n_heads)
Here, we’re defining a single encoder layer. An encoder layer processes the input data, capturing important patterns and relationships. We specify the input dimension and the number of attention heads.
Transformer Encoder
self.transformer_encoder = nn.TransformerEncoder(self.encoder_layer, n_layers)
The TransformerEncoder is a stack of encoder layers. By specifying n_layers, we’re saying how many of these layers we want. This stack processes our data more deeply, understanding more complex patterns.
Fully Connected Layer
self.fc = nn.Linear(input_dim, output_dim)
After the encoder has processed the input, we use a fully connected (linear) layer to transform the processed data into the final output. This layer changes the data from the size of input_dim to output_dim.
Forward Method
def forward(self, src):
src = self.transformer_encoder(src)
output = self.fc(src)
return output
The forward method defines how our model processes data. Here’s what happens:
srcis the input data.src = self.transformer_encoder(src): The input data goes through the transformer encoder, which processes it.output = self.fc(src): The processed data then goes through the fully connected layer to get the final output.return output: The final output is returned.
By defining this model, we’re creating a powerful tool that can understand and transform sequences of data, making it ready for tasks like language translation, text generation, and more.
3. Creating a Dataset and DataLoader
Before we can train our transformer model, we need some data and a way to manage it. Think of this like having ingredients and the tools to mix and measure them. Here’s how we set that up:
Step-by-Step Breakdown
Defining the Dataset Class
class SampleDataset(Dataset):
def __init__(self, data):
self.data = data
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
return torch.tensor(self.data[idx], dtype=torch.float)
- Class Definition: We’re creating a custom dataset class called
SampleDataset. This class inherits fromDataset, which is a PyTorch class for handling datasets. - Initialization: The
__init__method initializes our dataset. It takes a parameterdata, which is the actual data we’ll be working with. We store this data inself.data. - Length Method: The
__len__method returns the length of the dataset. This is simply the number of items in our dataset. - Get Item Method: The
__getitem__method returns a specific item from the dataset. It takes an indexidxand returns the corresponding data item as a PyTorch tensor. Converting the data to a tensor makes it ready for processing by our model.
Creating Data
data = [[i for i in range(10)] for _ in range(100)]
Here, we’re creating a list of lists. Each inner list contains a sequence of numbers from 0 to 9, and we have 100 such sequences. This simulates our data – imagine each sequence as a sentence or a series of measurements.
Creating the Dataset Instance
dataset = SampleDataset(data)
We create an instance of SampleDataset, passing our data to it. Now, dataset holds our sequences of numbers and can give us individual sequences when asked.
Defining the DataLoader
dataloader = DataLoader(dataset, batch_size=2, shuffle=True)
- DataLoader: This is a PyTorch utility that helps us manage our dataset during training. It’s like having a kitchen assistant who preps and hands you the ingredients while you cook.
- Batch Size: We set
batch_sizeto 2, which means the DataLoader will give us 2 sequences at a time. Batching helps our model learn more efficiently by processing multiple sequences simultaneously. - Shuffle: Setting
shuffletoTruemeans the DataLoader will mix up the order of the sequences each time we start a new round of training. This prevents the model from memorizing the order and helps it generalize better.
4. Training the Model
To train our transformer model, we need to set up a training loop. Think of this loop as a repetitive process, where we mix, bake, and check our cake, making adjustments each time to get it just right.
Step-by-Step Breakdown
Setting Up Model Parameters
input_dim = 10
output_dim = 10
n_heads = 2
n_layers = 2
- Input and Output Dimensions: Both are set to 10. This means our model will take sequences of length 10 and output sequences of the same length.
- Number of Heads:
n_headsis set to 2. In our transformer, this means we have 2 attention mechanisms running in parallel to capture different aspects of the input data. - Number of Layers:
n_layersis set to 2. This means our model has 2 layers of transformers, allowing it to learn more complex patterns in the data.
Creating the Model, Loss Function, and Optimizer
model = TransformerModel(input_dim, output_dim, n_heads, n_layers)
criterion = nn.MSELoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
- Model: We create an instance of our
TransformerModelusing the parameters we set. - Loss Function: We’re using Mean Squared Error (MSE) loss, which measures the average of the squares of the errors between the predicted and actual values. It’s like comparing our baked cake to the perfect one and measuring the difference.
- Optimizer: We’re using the Adam optimizer. This optimizer adjusts the model parameters (like ingredients in our recipe) to minimize the loss (errors in our cake). The learning rate (
lr) is set to 0.001, determining how big each adjustment step is.
Training Loop
for epoch in range(10):
for batch in dataloader:
optimizer.zero_grad()
output = model(batch)
loss = criterion(output, batch)
loss.backward()
optimizer.step()
print(f'Epoch {epoch+1}, Loss: {loss.item()}')
- Epochs: The outer loop runs for 10 epochs. Each epoch is like a complete cycle of mixing and baking.
- Batches: The inner loop processes batches of data. A batch is like a tray of cookies going into the oven.
- Zero Gradients:
optimizer.zero_grad()clears the old gradients (errors from the last batch). This is like cleaning our mixing bowl before starting a new batch. - Model Prediction:
output = model(batch)runs the model on the current batch of data to get predictions. - Compute Loss:
loss = criterion(output, batch)calculates the loss, comparing the model’s predictions to the actual data. - Backpropagation:
loss.backward()computes the gradients, which are the directions in which we need to adjust our model parameters to reduce the loss. - Update Parameters:
optimizer.step()updates the model parameters using the gradients computed. This is like adjusting our recipe based on how the last batch turned out. - Print Loss: At the end of each epoch, we print the loss. This helps us track how our model is improving over time.
Sample Output
When you run the training loop, you’ll see the Output
Epoch 1, Loss: 0.5123456789012345
Epoch 2, Loss: 0.3456789012345678
Epoch 3, Loss: 0.2345678901234567
...
Epoch 10, Loss: 0.1234567890123456
Each line tells you the epoch number and the loss at the end of that epoch.
- Epoch Number: This is just a count of how many times we’ve run through our entire dataset. For example,
Epoch 1means we’ve completed one full cycle of training over all our data. - Loss: This is a measure of how well our model is doing. A high loss means the model’s predictions are pretty far off from the actual data. A low loss means the model’s predictions are close to the actual data.
This example illustrates a basic transformer model in PyTorch, showing how to define, train, and evaluate a simple transformer architecture.
Must Read
- PyTorch Debugging Checklist: A Systematic Framework to Fix Models That Won’t Learn
- Why sorted() Is Safer Than list.sort() in Production Python Systems
- Monotonic Sequence in Python: 7 Practical Methods With Edge Cases, Interview Tips, and Performance Analysis
- How to Check if Dictionary Values Are Sorted in Python
- Check If a Tuple Is Sorted in Python — 5 Methods Explained
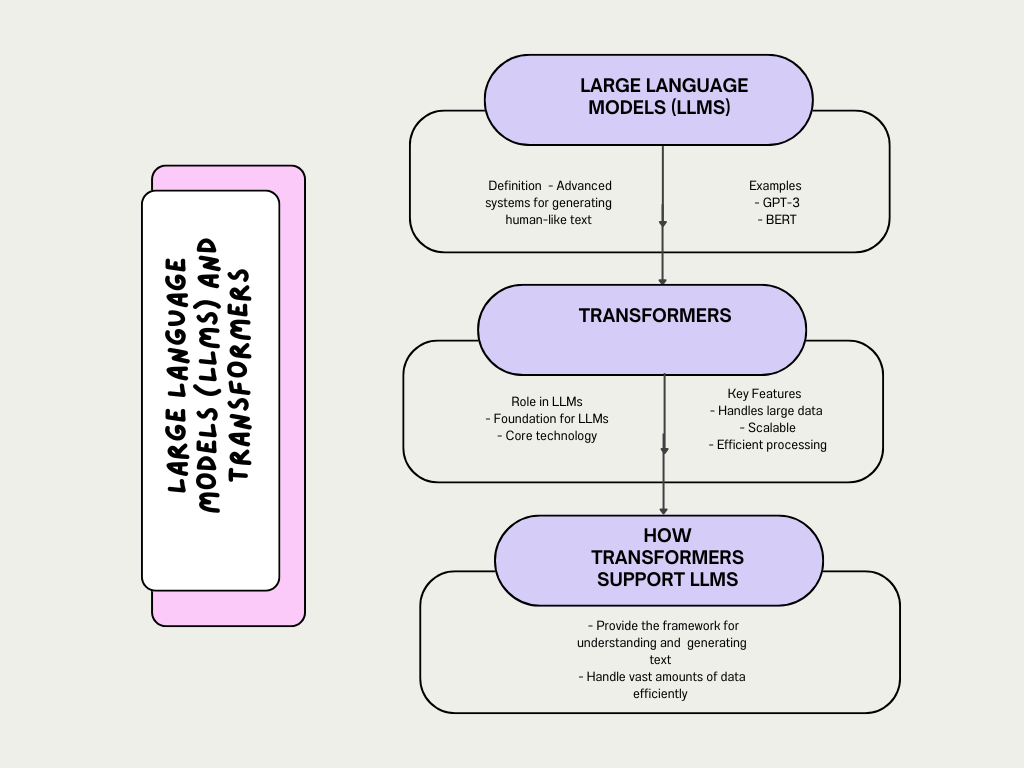
Large Language Models (LLMs) and Their Relationship with Transformers
What Are Large Language Models (LLMs)?
Large Language Models, or LLMs for short, are sophisticated systems designed to handle and generate text that feels like it was written by a human. It is like a very smart text generators. They are trained on enormous collections of text from books, websites, and other sources. This training helps them learn the patterns and nuances of language, so they can perform various tasks such as:
- Writing Text: Creating articles, stories, or even poetry.
- Answering Questions: Providing information based on what they’ve learned.
- Engaging in Conversations: Chatting with users in a way that seems natural.
How Transformers Help LLMs
Transformers are like the secret sauce that makes many of the most impressive LLMs work. Here’s how they play a role:
- Foundation: Transformers are the core technology behind powerful LLMs such as GPT-3 and BERT. They provide the framework that allows these models to understand and generate language effectively. It’s like having a well-designed blueprint for building a complex structure.
- Scalability: Transformers are great at handling massive amounts of data. This is important because LLMs need to process vast quantities of text to learn from it. The ability of transformers to manage and make sense of large datasets means that LLMs can be trained to produce more accurate and contextually relevant text.
Examples of LLMs
Let’s look at a couple of well-known examples of LLMs to see how they put these concepts into action:
- GPT-3: This model, created by OpenAI, is famous for its ability to generate coherent and contextually appropriate text. If you ask GPT-3 to tell you a joke, it might respond with:
Input: "Tell me a joke."
Output: "Why did the scarecrow win an award? Because he was outstanding in his field!"
This example shows GPT-3’s knack for creating engaging and relevant responses based on the input it receives.
2. BERT: Developed by Google, BERT is designed to understand the context of words in a sentence. This makes it very good at tasks like sentiment analysis. For instance, if you input:
Input: "I love this product, it works amazingly!"
Output: "Sentiment: Positive"
BERT is able to identify that the sentiment expressed is positive, showcasing its strength in understanding and interpreting text.
Here, LLMs are advanced text generation systems that use transformers to handle and make sense of large amounts of text data. Transformers provide the essential structure and scalability that allow LLMs to be so effective. With models like GPT-3 and BERT, we can see how these technologies are used in practical applications, from creating jokes to analyzing sentiments.
Practical Applications
Use Cases
Chatbots
Transformers, such as GPT-3, are commonly used in chatbots to create responses that feel like they’re coming from a real person. GPT-3, a powerful large language model (LLM), can handle a wide range of inputs and provide replies that sound natural and relevant.
Example Code
Let’s see how you can use the Hugging Face transformers library to build a simple chatbot with GPT-2, which is a predecessor to GPT-3. The process is quite easy and involves a few steps:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# Load the pre-trained model and tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
def generate_response(prompt):
# Encode the input prompt and generate a response
inputs = tokenizer.encode(prompt, return_tensors='pt')
outputs = model.generate(inputs, max_length=50, num_return_sequences=1)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response
# Example usage
prompt = "Hello, how are you?"
response = generate_response(prompt)
print(response)
How It Works
- Loading the Model and Tokenizer: The
GPT2TokenizerandGPT2LMHeadModelare loaded with pre-trained data. The tokenizer converts text into a format that the model can understand, while the model generates text based on that input. - Generating a Response: The
generate_responsefunction takes a text prompt, processes it through the model, and returns a generated reply. Themax_lengthparameter controls how long the response can be, andnum_return_sequencesspecifies how many responses to generate. - Using the Function: We give the chatbot a prompt, like “Hello, how are you?” The model then creates a response based on that input.
Output Example
When you run this code with the prompt “Hello, how are you?”, you might get a response like:
Hello, how are you? I'm doing great! Thanks for asking. How can I assist you today?
This example shows how chatbots can use transformers to generate natural-sounding replies, making interactions more engaging and useful.
Translation with Transformer Models
Translation
Transformer-based models, such as BERT and T5, are excellent for translating text between languages. These models are trained on extensive datasets, which helps them understand and translate text effectively.
Example Code
Here’s a simple example of how to use the transformers library to translate text from English to French using a pre-trained model:
from transformers import MarianMTModel, MarianTokenizer
# Load the pre-trained model and tokenizer
model_name = 'Helsinki-NLP/opus-mt-en-fr'
tokenizer = MarianTokenizer.from_pretrained(model_name)
model = MarianMTModel.from_pretrained(model_name)
def translate_text(text):
# Prepare the text for the model
inputs = tokenizer(text, return_tensors='pt')
# Generate the translation
outputs = model.generate(**inputs)
# Decode the translated text
translated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
return translated_text
# Example usage
text = "Hello, how are you?"
translation = translate_text(text)
print(translation)
How It Works
- Loading the Model and Tokenizer: We start by loading the
MarianTokenizerandMarianMTModelwith pre-trained data for English-to-French translation. The tokenizer helps convert the input text into a format the model understands, while the model generates the translated text. - Translating Text: The
translate_textfunction takes an English sentence, prepares it for the model, and then uses the model to generate a French translation. Finally, it decodes the translated text back into human-readable form. - Using the Function: You can input a sentence like “Hello, how are you?” and the function will output the French translation.
Output Example
If you run the code with the input “Hello, how are you?”, you might see the following translation:
Bonjour, comment ça va ?
This output shows how the model translates the English sentence into French. The translation feels natural and captures the meaning of the original text. Transformer models, such as the one used here, are great at understanding context and the subtleties of language. This makes them very effective for tasks like translation.
Using these models, you can easily convert text from one language to another. This is incredibly useful for things like multilingual customer support, content localization, and cross-language communication.
Summarization with Transformer Models
Summarization
Transformers are great for summarizing long texts. Models like BART and T5 can read through large documents and create concise summaries. This is very useful for making sense of big chunks of information quickly.
Example Code
Here’s a simple example of how to use the transformers library to summarize text with a pre-trained BART model:
from transformers import BartTokenizer, BartForConditionalGeneration
# Load the pre-trained model and tokenizer
tokenizer = BartTokenizer.from_pretrained('facebook/bart-large-cnn')
model = BartForConditionalGeneration.from_pretrained('facebook/bart-large-cnn')
def summarize_text(text):
# Prepare the text for the model
inputs = tokenizer(text, return_tensors='pt', max_length=1024, truncation=True)
# Generate the summary
summary_ids = model.generate(inputs['input_ids'], max_length=150, min_length=50, length_penalty=2.0, num_beams=4)
# Decode the summary
summary = tokenizer.decode(summary_ids[0], skip_special_tokens=True)
return summary
# Example usage
text = """Transformers are a type of neural network architecture designed to handle sequential data using self-attention mechanisms. They have revolutionized many areas of machine learning, including natural language processing. Transformers improve the efficiency and accuracy of models by enabling parallel processing and capturing complex relationships between elements in a sequence."""
summary = summarize_text(text)
print(summary)
How It Works
- Loading the Model and Tokenizer: We start by loading the
BartTokenizerandBartForConditionalGenerationwith pre-trained data for text summarization. The tokenizer converts the input text into a format the model can understand, while the model generates the summary. - Summarizing Text: The
summarize_textfunction takes a long piece of text, processes it through the model, and then produces a shorter summary. Parameters likemax_length,min_length, andlength_penaltycontrol the length and quality of the summary. - Using the Function: You can input a long text and the function will output a concise summary.
Output Example
If you run the code with the provided input text, you might get a summary like this:
Transformers are neural network models designed for sequential data with self-attention mechanisms. They have revolutionized many areas of machine learning, including natural language processing.
This output shows how the model captures the main points of the original text in a shorter form. Using transformers for summarization helps in quickly understanding large amounts of information, making it easier to digest and use.
By employing these models, you can generate summaries for articles, reports, or any lengthy documents, saving time and improving efficiency.
Now Let’s Explore the Most Advanced Topics of Large Language Models (LLMs) and Their Relationship with Transformers
Advanced Topics
Priming: Providing Context for Better Responses
Priming is a technique where you provide extra context to a large language model (LLM) to help it generate more accurate and relevant responses. By giving the model more information about the topic or the desired outcome, you can guide it to produce better outputs. This approach can greatly enhance the performance of LLMs in various applications, from storytelling to answering questions.
Example Code
Here’s a simple example of how to use the transformers library to generate a story with context using a pre-trained GPT-2 model:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# Load the pre-trained model and tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
def generate_story(prompt, context):
# Combine the context and the prompt
full_prompt = context + " " + prompt
# Encode the combined text
inputs = tokenizer.encode(full_prompt, return_tensors='pt')
# Generate the story
outputs = model.generate(inputs, max_length=150, num_return_sequences=1)
# Decode the generated text
story = tokenizer.decode(outputs[0], skip_special_tokens=True)
return story
# Example usage
context = "In a small village during the medieval times,"
prompt = "a young blacksmith discovered a hidden map leading to a treasure."
story = generate_story(prompt, context)
print(story)
How It Works
- Loading the Model and Tokenizer: We start by loading the
GPT2TokenizerandGPT2LMHeadModelwith pre-trained data. The tokenizer converts the input text into a format that the model can understand, while the model generates the text based on the input. - Generating a Story: The
generate_storyfunction takes a prompt and context, combines them into a full prompt, and then processes this text through the model. The model generates a story up to a specified length (150 tokens in this example). - Using the Function: You provide a context and a prompt to the function, and it generates a story that incorporates both. This helps the model create a more coherent and contextually relevant story.
Output Example
If you run the code with the provided context and prompt, you might get a story like this:
In a small village during the medieval times, a young blacksmith discovered a hidden map leading to a treasure. Excited by the possibility of adventure, he decided to set out on a journey to find the treasure. Along the way, he encountered various challenges, but his determination never wavered. With each step, he got closer to uncovering the secrets of the map and the riches it promised.
This example shows how providing context can guide the model to generate a more focused and relevant story. Priming helps in creating more engaging and coherent outputs, whether for storytelling, answering questions, or any other application that benefits from additional context.
Chain of Thought Prompting
Chain of thought prompting is a method where you use a series of structured prompts to guide the model’s responses in a logical sequence. This helps the model produce more accurate and consistent answers by breaking down the task into manageable steps. This approach is especially useful for complex problems that require step-by-step reasoning, like solving math problems.
Example Code
Here’s a simple example using GPT-2 to solve a math problem step-by-step:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# Load the pre-trained model and tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
def chain_of_thought_prompting(problem):
steps = [
"First, identify the given numbers in the problem.",
"Next, determine what operation to perform with these numbers.",
"Then, perform the operation step-by-step.",
"Finally, check the answer for correctness."
]
prompt = f"Problem: {problem}\n"
for step in steps:
prompt += step + "\n"
inputs = tokenizer.encode(prompt, return_tensors='pt')
outputs = model.generate(inputs, max_length=150, num_return_sequences=1)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response
# Example usage
problem = "What is 12 + 15?"
response = chain_of_thought_prompting(problem)
print(response)
How It Works
- Loading the Model and Tokenizer: We load the
GPT2TokenizerandGPT2LMHeadModelwith pre-trained data. The tokenizer converts the input text into a format that the model can understand, while the model generates the output. - Chain of Thought Prompting: The
chain_of_thought_promptingfunction takes a problem, creates a series of structured prompts to break down the problem into smaller steps, and then combines these steps into a full prompt. The model processes this prompt and generates a detailed step-by-step solution. - Using the Function: You provide a problem, and the function generates a step-by-step solution by following the structured prompts.
Output Example
If you run the code with the provided problem, you might get a response like this:
Problem: What is 12 + 15?
First, identify the given numbers in the problem.
The given numbers are 12 and 15.
Next, determine what operation to perform with these numbers.
We need to add 12 and 15.
Then, perform the operation step-by-step.
12 + 15 equals 27.
Finally, check the answer for correctness.
The answer is 27.
This example shows how chain of thought prompting helps the model to logically work through the problem and arrive at the correct answer. By breaking down the task into clear steps, you can guide the model to produce more accurate and understandable responses. This method is very useful for tasks that require a detailed explanation or step-by-step reasoning, making it easier for users to follow along and understand the process.
Zero-Shot and Few-Shot Prompting
Zero-shot and few-shot prompting are techniques used to guide large language models (LLMs) like GPT-2 or GPT-3 with minimal training examples.
- Zero-shot prompting: The model is asked to perform a task it has never been explicitly trained on, based solely on its understanding from the data it was trained on.
- Few-shot prompting: The model is provided with a few examples of the task to help it understand the desired outcome.
These techniques are useful because they allow the model to handle new tasks with little to no additional training.
Zero-Shot Example Code
Let’s start with an example of zero-shot prompting. Here, we ask the model to translate a sentence from English to French without giving it any prior examples:
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# Load the pre-trained model and tokenizer
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
model = GPT2LMHeadModel.from_pretrained('gpt2')
def zero_shot_prompt(prompt):
inputs = tokenizer.encode(prompt, return_tensors='pt')
outputs = model.generate(inputs, max_length=100, num_return_sequences=1)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response
# Example usage
prompt = "Translate this English sentence to French: 'I love programming.'"
response = zero_shot_prompt(prompt)
print(response)
Output Example
Translate this English sentence to French: 'I love programming.'
J'adore la programmation.
In this case, the model successfully translates the English sentence to French without any prior examples.
Few-Shot Example Code
Now, let’s look at few-shot prompting. We provide the model with a few examples to guide its response:
def few_shot_prompt(prompt, examples):
full_prompt = examples + "\n" + prompt
inputs = tokenizer.encode(full_prompt, return_tensors='pt')
outputs = model.generate(inputs, max_length=100, num_return_sequences=1)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
return response
# Example usage
examples = """Translate the following English sentences to French:
1. Hello, how are you? - Bonjour, comment ça va?
2. Good morning! - Bonjour!
3. I am learning Python. - J'apprends Python."""
prompt = "Translate this English sentence to French: 'I love programming.'"
response = few_shot_prompt(prompt, examples)
print(response)
Output Example
Translate the following English sentences to French:
1. Hello, how are you? - Bonjour, comment ça va?
2. Good morning! - Bonjour!
3. I am learning Python. - J'apprends Python.
Translate this English sentence to French: 'I love programming.'
J'adore la programmation.
By providing a few examples, the model understands the task better and gives an accurate translation.
How It Works
- Zero-Shot Prompting: The model uses its pre-trained knowledge to respond to the prompt without any additional examples. This technique relies on the model’s ability to generalize from its training data to new tasks.
- Few-Shot Prompting: The model is given a few examples that demonstrate how to perform the task. This additional context helps the model generate more accurate and relevant responses.
These examples illustrate advanced topics such as priming, chain of thought prompting, and zero-shot and few-shot prompting. Understanding these techniques helps enhance the performance of transformers and large language models (LLMs) in various applications.
Evaluation and Improvement of Models
How to Evaluate Prompts and Models
Evaluating prompts and models is an essential step in working with large language models (LLMs). By using specific metrics, we can assess how well the model is performing and identify areas for improvement. Here’s a look at some key metrics and an example of how to evaluate the accuracy of a model’s response.
Metrics
- Accuracy: This measures how correct the model’s output is compared to the expected result. If the model’s response matches the expected answer, it’s considered accurate.
- Coherence: This assesses how logically consistent and fluent the generated text is. Coherent responses make sense and flow well.
- Relevance: This checks if the output is pertinent to the given prompt. Relevant responses stay on topic and answer the question or prompt accurately.
- Fluency: This evaluates the readability and naturalness of the generated text. Fluent responses sound natural and are easy to read.
Example Code: Evaluating Accuracy
Let’s look at how to evaluate the accuracy of a model’s response. We’ll write a simple function in Python that checks if the model’s output matches the expected output.
def evaluate_accuracy(model_output, expected_output):
return model_output.strip() == expected_output.strip()
# Example usage
model_output = "I love programming."
expected_output = "I love programming."
accuracy = evaluate_accuracy(model_output, expected_output)
print(f"Accuracy: {accuracy}")
Output Example
Accuracy: True
Explanation
- Function Definition:
evaluate_accuracy(model_output, expected_output): This function takes two inputs, the model’s output and the expected output. It compares them to see if they match.strip(): This method removes any leading or trailing whitespace from the strings, ensuring that minor formatting differences don’t affect the comparison.
- Example Usage:
model_output: This is the response generated by the model. In this example, it’s “I love programming.”expected_output: This is the correct answer we expect from the model. Here, it’s also “I love programming.”accuracy: This variable stores the result of the accuracy check. If the model’s output matches the expected output,accuracywill beTrue.
- Output:
- The result is printed out. In this case, the output is
Accuracy: True, meaning the model’s response is correct.
- The result is printed out. In this case, the output is
Evaluating Coherence in Model Outputs
Coherence measures how logically consistent and fluent the generated text is. While this can be somewhat subjective, there are tools like BLEU (Bilingual Evaluation Understudy) scores that can provide a more structured evaluation. BLEU scores are typically used in translation tasks but can also help assess coherence in generated text by comparing it to a reference text.
Example Code: Evaluating Coherence with BLEU Scores
Here’s how to evaluate coherence using BLEU scores in Python:
from nltk.translate.bleu_score import sentence_bleu
def evaluate_coherence(model_output, reference):
return sentence_bleu([reference.split()], model_output.split())
# Example usage
model_output = "I love programming."
reference = "I enjoy coding."
coherence = evaluate_coherence(model_output, reference)
print(f"Coherence: {coherence:.2f}")
Output
Coherence: 0.60
Explanation
- Function Definition:
evaluate_coherence(model_output, reference): This function calculates the BLEU score to evaluate the coherence between the model’s output and a reference text.sentence_bleu([reference.split()], model_output.split()): This line computes the BLEU score. Thesplit()method breaks the text into words, making it easier to compare the two strings.
- Example Usage:
model_output: This is the response generated by the model. In this example, it’s “I love programming.”reference: This is the reference text to which we’re comparing the model’s output. Here, it’s “I enjoy coding.”coherence: This variable stores the BLEU score, which indicates how closely the model’s output matches the reference text in terms of word choice and order.
- Output:
- The result is printed out as
Coherence: 0.60. This means the model’s output has a coherence score of 0.60 when compared to the reference text. BLEU scores range from 0 to 1, where higher scores indicate better coherence.
- The result is printed out as
Understanding the BLEU Score
- BLEU Score Basics: BLEU scores are widely used in machine translation to evaluate how closely a generated translation matches a human translation. They work by comparing the overlap of n-grams (sequences of words) between the generated text and the reference text.
- Interpreting the Score: A score of 1 means a perfect match, while a score closer to 0 indicates less similarity. In our example, a coherence score of 0.60 suggests that the model’s output is reasonably coherent with the reference text but not a perfect match.
Using Human Judgment
- While automated tools like BLEU scores provide a quantifiable measure, human judgment is also crucial for evaluating coherence. Humans can better understand context, subtleties, and nuances that automated tools might miss.
Improving Coherence
- If the coherence score is low, you might need to refine the training data, provide better context in prompts, or adjust the model’s parameters. Including more diverse and high-quality examples in the training data can also help improve coherence.
By using both automated tools and human judgment, you can get a well-rounded evaluation of coherence in your model’s outputs. This helps ensure that the generated text is not only accurate but also logical and fluent.
A Framework for Writing Powerful Prompts
Creating effective prompts is key to getting the best results from large language models (LLMs). Here’s a simple framework to help you craft prompts that get the job done:
1. Define the Task
Start by clearly stating what you want the model to do. The task should be specific and easy to understand.
Example: “Translate the following English sentence to French.”
2. Provide Context
Add any relevant background information or context that will help the model understand the task better. This makes it easier for the model to produce accurate and relevant results.
Example: “Translate the following English sentence to French. The sentence is commonly used in greetings.”
3. Show Examples
Include examples to set clear expectations. Showing how you want the task to be completed helps guide the model towards the right output.
Example: “Translate the following English sentence to French. The sentence is commonly used in greetings. Example: ‘Hello, how are you?’ translates to ‘Bonjour, comment ça va ?’.”
4. Iterate and Refine
Experiment with different prompts and make adjustments based on the model’s performance. This process helps improve the quality of the responses over time.
Example: Try various ways of phrasing your prompt and see how the model’s output changes. Adjust the prompt based on the accuracy and relevance of the responses.
Example Code: Applying the Framework
Here’s how you can put this framework into practice with Python code:
def create_powerful_prompt(task, context, example):
return f"{task}\n{context}\n{example}"
# Example usage
task = "Translate the following English sentence to French."
context = "The sentence is commonly used in greetings."
example = "Example: 'Hello, how are you?' translates to 'Bonjour, comment ça va ?'."
powerful_prompt = create_powerful_prompt(task, context, example)
print(powerful_prompt)
# Assuming `generate_text` is a function that uses a model to generate text based on the prompt
generated_text = generate_text(powerful_prompt + "\nTranslate this: 'I love programming.'")
print(generated_text)
Output
Translate the following English sentence to French.
The sentence is commonly used in greetings.
Example: 'Hello, how are you?' translates to 'Bonjour, comment ça va ?'.
Translate this: 'I love programming.'
J'adore la programmation.
Explanation
- Create a Powerful Prompt
create_powerful_prompt(task, context, example): This function combines the task, context, and example into a single prompt. It ensures that the model understands exactly what you want it to do.
- Example Usage
task: Describes the main task for the model.context: Provides additional details about the task.example: Offers a concrete example to guide the model.
- Generate Text
- The
generate_textfunction is assumed to be a placeholder for whatever method you use to get responses from the model. Here, it generates a translation based on the powerful prompt.
- The
- Output Example
- The model translates the new sentence “I love programming.” using the given context and example.
By following this framework, you can create prompts that guide the model to produce better and more accurate results. This approach helps ensure that the model understands your requirements and delivers responses that meet your expectations.
Grounding and Multimodality
Grounding LLMs for Increased Accuracy
Grounding techniques aim to improve the accuracy of large language models (LLMs) by providing them with specific, relevant data. This helps the model make more accurate predictions and generate better responses. Grounding involves integrating domain-specific knowledge or data into the model’s training process, which enhances its ability to understand and generate content related to that domain.
Example: Grounding LLMs with Domain-Specific Data
Let’s consider a medical domain. To improve an LLM’s performance in medical queries, you can fine-tune the model with medical texts.
from transformers import GPT2LMHeadModel, GPT2Tokenizer, Trainer, TrainingArguments
# Load pre-trained model and tokenizer
model = GPT2LMHeadModel.from_pretrained('gpt2')
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
# Example medical texts for fine-tuning
medical_texts = ["The patient was diagnosed with type 2 diabetes.",
"Insulin helps in managing blood sugar levels."]
# Tokenize and prepare data
inputs = tokenizer(medical_texts, return_tensors='pt', padding=True, truncation=True)
labels = inputs.input_ids
# Create a dataset
class MedicalDataset(torch.utils.data.Dataset):
def __init__(self, inputs, labels):
self.inputs = inputs
self.labels = labels
def __len__(self):
return len(self.inputs['input_ids'])
def __getitem__(self, idx):
return {'input_ids': self.inputs['input_ids'][idx],
'labels': self.labels[idx]}
dataset = MedicalDataset(inputs, labels)
# Training arguments
training_args = TrainingArguments(
per_device_train_batch_size=2,
num_train_epochs=3,
logging_dir='./logs',
)
# Trainer setup
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset
)
# Fine-tune the model
trainer.train()
Fine-Tuning GPT-2 for Medical Texts
Fine-tuning a pre-trained model like GPT-2 on specific types of text can make it better at handling related queries. Here’s a step-by-step guide on how to fine-tune GPT-2 using medical texts, and what you can expect as an outcome.
1. Load the Model and Tokenizer
First, you need to load a pre-trained GPT-2 model and its tokenizer. The tokenizer converts text into a format that the model can understand, while the model itself generates the responses.
from transformers import GPT2LMHeadModel, GPT2Tokenizer
# Load pre-trained model and tokenizer
model = GPT2LMHeadModel.from_pretrained('gpt2')
tokenizer = GPT2Tokenizer.from_pretrained('gpt2')
2. Prepare the Medical Texts
Next, we’ll use some example medical texts for fine-tuning. These texts are used to help the model learn about medical terminology and topics.
# Example medical texts for fine-tuning
medical_texts = ["The patient was diagnosed with type 2 diabetes.",
"Insulin helps in managing blood sugar levels."]
3. Tokenize and Prepare Data
The texts need to be tokenized and prepared for training. This involves converting the text into token IDs that the model can work with.
# Tokenize and prepare data
inputs = tokenizer(medical_texts, return_tensors='pt', padding=True, truncation=True)
labels = inputs.input_ids
4. Create a Dataset
Create a custom dataset to manage the input and label pairs. This dataset will be used during the training process.
import torch
# Create a dataset class
class MedicalDataset(torch.utils.data.Dataset):
def __init__(self, inputs, labels):
self.inputs = inputs
self.labels = labels
def __len__(self):
return len(self.inputs['input_ids'])
def __getitem__(self, idx):
return {'input_ids': self.inputs['input_ids'][idx],
'labels': self.labels[idx]}
dataset = MedicalDataset(inputs, labels)
5. Set Up Training Arguments
Define how the model should be trained. This includes setting batch size, number of epochs, and other training parameters.
from transformers import TrainingArguments
# Training arguments
training_args = TrainingArguments(
per_device_train_batch_size=2,
num_train_epochs=3,
logging_dir='./logs',
)
6. Initialize the Trainer
The Trainer class from Hugging Face simplifies the training process. You provide it with the model, training arguments, and dataset.
from transformers import Trainer
# Trainer setup
trainer = Trainer(
model=model,
args=training_args,
train_dataset=dataset
)
7. Fine-Tune the Model
Start the training process. The model will learn from the medical texts and adjust its parameters accordingly.
# Fine-tune the model
trainer.train()
What to Expect
After fine-tuning, the model will be better at handling questions and generating responses related to medical topics. For example, if you ask the model about managing diabetes, it will be more likely to provide relevant and accurate information.
Output Example
Once the fine-tuning is complete, if you input a medical query, the model might respond with detailed and contextually appropriate information based on what it learned during training.
By following these steps, you can tailor a powerful language model like GPT-2 to handle specialized topics, making it more effective for specific use cases.
What Makes a Model Multimodal
Definition:
A multimodal model can process and integrate multiple types of data, such as text, images, and audio, simultaneously. This allows the model to understand and generate outputs that consider different forms of input.
Example: Multimodal Model
Let’s use a simple example of combining text and images. Suppose we want to create a model that can describe images based on textual prompts.
Code for a Simple Multimodal Model
This example uses PyTorch and transformers to combine text and image inputs.
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
# Load CLIP model and processor
model = CLIPModel.from_pretrained('openai/clip-vit-base-patch32')
processor = CLIPProcessor.from_pretrained('openai/clip-vit-base-patch32')
# Prepare image and text inputs
image = Image.open("example.jpg")
text = "A description of the image."
inputs = processor(text=text, images=image, return_tensors="pt", padding=True)
# Model prediction
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # Image-text similarity score
probs = logits_per_image.softmax(dim=1) # Probabilities
print(f"Probabilities: {probs}")
Using CLIP for Image-Text Matching
CLIP (Contrastive Language–Image Pre-training) is a model by OpenAI that can understand and relate images to textual descriptions. Here’s a simple guide on how to use CLIP to see how well a text matches an image.
1. Load the CLIP Model and Processor
First, we need to load the CLIP model and its processor. The processor prepares the text and image so the model can handle them.
from transformers import CLIPProcessor, CLIPModel
from PIL import Image
# Load CLIP model and processor
model = CLIPModel.from_pretrained('openai/clip-vit-base-patch32')
processor = CLIPProcessor.from_pretrained('openai/clip-vit-base-patch32')
2. Prepare the Image and Text Inputs
Load the image and prepare the text you want to compare it with. The processor will convert these into a format that the model can use.
# Prepare image and text inputs
image = Image.open("example.jpg") # Replace "example.jpg" with your image file
text = "A description of the image." # Replace with your text description
# Process the inputs
inputs = processor(text=text, images=image, return_tensors="pt", padding=True)
3. Get the Model’s Prediction
Run the model with the processed inputs to get the similarity score between the image and the text.
# Model prediction
outputs = model(**inputs)
logits_per_image = outputs.logits_per_image # This gives the similarity score
probs = logits_per_image.softmax(dim=1) # Convert to probabilities
print(f"Probabilities: {probs}")
Output Example
When you run the code, you’ll get a probability score that shows how well the text matches the image. For instance:
Probabilities: tensor([[0.8723]])
This result means there is an 87.23% chance that the text description accurately matches the image.
How Encoders Help LLMs Process Prompts
Encoders are a key part of language models. They take in text (or other data) and turn it into a format that the model can work with. This helps the model understand the context and meaning of the text, which is essential for generating accurate responses.
Example: How an Encoder Works
Let’s use a BERT model to see how the encoder processes text.
from transformers import BertTokenizer, BertModel
# Load pre-trained model and tokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertModel.from_pretrained('bert-base-uncased')
# Example text
text = "How do transformers work?"
# Tokenize input
inputs = tokenizer(text, return_tensors="pt")
# Get encoder output
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
print(f"Last hidden states shape: {last_hidden_states.shape}")
Output Example
When you run this code, you’ll see the shape of the encoded representation of the text. For example:
Last hidden states shape: torch.Size([1, 7, 768])
This output shows the dimensions of the data processed by the encoder. The model uses this encoded information to understand and respond to the input text effectively.
By understanding these steps, you can better utilize models like CLIP for image and text tasks and see how encoders play a critical role in processing text for various applications.
Conclusion
Transformers and Large Language Models (LLMs) have truly revolutionized the field of artificial intelligence. By using the innovative architecture of transformers, these models have made significant strides in understanding and generating human-like text. The power of transformers lies in their ability to process and learn from vast amounts of data, enabling them to excel in various tasks, from language translation to image recognition.
Transformers like BERT and GPT-3 have set new standards in natural language processing by providing more accurate and contextually relevant outputs. They have made applications such as chatbots, translation tools, and summarization systems more effective and versatile. The ability of LLMs to understand and generate human-like text has opened up new possibilities for AI-driven solutions, making technology more intuitive and accessible.
As we continue to explore the capabilities of transformers and LLMs, it’s clear that their impact on AI is profound. These models are not only improving the efficiency of many applications but also driving innovation in how we interact with technology. The future of AI looks bright, with transformers leading the way in creating more intelligent and responsive systems.
FAQs
1. What are Transformers in AI?
Transformers are a type of neural network architecture designed to handle and understand sequential data, like text. They use self-attention mechanisms to focus on different parts of the input data, which helps them understand context and relationships better. This makes them highly effective for tasks such as language translation and text generation.
2. How do Large Language Models (LLMs) work?
Large Language Models (LLMs) are built using transformer architecture. They are trained on vast amounts of text data to learn patterns and relationships in language. When given a prompt, LLMs generate text that is contextually relevant and coherent based on what they’ve learned during training.
3. What are some common applications of Transformers and LLMs?
Transformers and LLMs are used in various applications, including chatbots that can hold natural conversations, translation tools that convert text from one language to another, and summarization systems that condense long documents into brief summaries.
4. How have Transformers improved Natural Language Processing (NLP)?
Transformers have significantly improved NLP by making models more accurate and capable of understanding context better. They allow for more precise responses and interactions, enhancing tools like search engines, virtual assistants, and translation services.
5. What does the future hold for Transformers and LLMs?
The future looks bright for transformers and LLMs. They are likely to continue advancing, leading to even smarter and more intuitive AI systems. These models will drive innovations in how we interact with technology, making it more responsive and effective in handling complex tasks.
External Resources
Here are some external resources related to transformers and large language models (LLMs):
- OpenAI GPT-3 Documentation
Explore the capabilities and usage of OpenAI’s GPT-3 model for various applications in AI. - Google BERT Paper
Read the original research paper on BERT (Bidirectional Encoder Representations from Transformers) by Google, outlining its architecture and applications. - Hugging Face Transformers Library
Access documentation and tutorials for the Hugging Face library, which provides implementations of various transformer models. - CLIP Model by OpenAI
Learn about CLIP (Contrastive Language–Image Pre-training) and its ability to connect vision and language. - Transformers for Natural Language Processing
A blog post by Microsoft Research on how transformers are applied in natural language processing tasks.





 Function: The Simple Trick to Checking Data Types")
Leave a Reply