

The Complete Guide to Python String Methods and Operations
We’re going to walk through Python strings together, step by step. I’ve been coding for years, and strings still trip people up sometimes. Let me show you how they actually work.
What Are Strings, Really?
When you text someone, you type letters, numbers, spaces, maybe some emoji. That’s what a string is in Python – just text that your program can work with.
my_message = "Hey, want to grab coffee at 3pm?"
Those quotation marks tell Python “This is text, don’t try to run it as code.” You can use single quotes too:
another_message = 'Python makes my brain happy!'
Both work the same way. I usually pick double quotes, but it doesn’t matter. Pick one and stick with it.
Creating Your First Strings
When you make a string, you’re giving Python some text to remember. Like writing sticky notes:
# Different ways to make strings
name = "Maria"
city = 'Austin'
sentence = "I really love this city"
empty_note = "" # Like a blank sticky note
Each variable is like a labeled box where you keep your text. The box called “name” has “Maria” in it.
Multi-line Strings – For Longer Text
Sometimes you need more space, like when you’re writing an email or a story. Python lets you spread text across multiple lines with triple quotes:
long_story = """Last weekend, I went hiking in the mountains.
The view from the top was incredible.
I definitely want to go back soon."""
print(long_story)
This prints:
Last weekend, I went hiking in the mountains.
The view from the top was incredible.
I definitely want to go back soon.
It’s like having a bigger piece of paper instead of cramming everything onto one line.
Basic String Operations – Your First Moves
Sticking Strings Together (Concatenation)
Want to combine two pieces of text? Just use the + sign. This creates a new string by joining the pieces in order:
first_name = "Alex"
last_name = "Johnson"
full_name = first_name + " " + last_name
print(full_name)
What happens here:
- Python takes “Alex” (the value of first_name)
- Adds a space ” “
- Adds “Johnson” (the value of last_name)
- Creates a new string “Alex Johnson”
Output: Alex Johnson
Notice that space in the middle? Without it, you’d get “AlexJohnson” – probably not what you want. The space is just another string we’re joining in.
Repeating Text
Need to say something multiple times? Use the * symbol. This tells Python to repeat the string a certain number of times:
excited = "Wow"
really_excited = excited * 4
print(really_excited)
Here’s what Python does:
- Takes the string “Wow”
- Repeats it 4 times
- Joins all the copies together
Output: WowWowWowWow
You can use any positive integer. excited * 0 gives you an empty string, and excited * 1 gives you the original string.
How Long Is My String?
The len() function tells you exactly how many characters are in your string. Every character counts – letters, numbers, spaces, punctuation marks, even invisible characters like tabs:
tweet = "Learning Python is fun"
character_count = len(tweet)
print(f"This tweet has {character_count} characters")
Let’s count manually: L-e-a-r-n-i-n-g-[space]-P-y-t-h-o-n-[space]-i-s-[space]-f-u-n
That’s 22 characters total.
Output: This tweet has 22 characters
Getting Individual Characters (Indexing)
Your string is like a line of mailboxes, numbered from 0. You can peek into any mailbox by using its number in square brackets:
word = "Python"
print(f"First letter: {word[0]}")
print(f"Second letter: {word[1]}")
print(f"Last letter: {word[-1]}")
Here’s how the indexing works:
- Position 0: P
- Position 1: y
- Position 2: t
- Position 3: h
- Position 4: o
- Position 5: n
Python starts counting from 0, not 1. Using negative numbers counts backward: -1 is the last character, -2 is second-to-last, and so on.
Output:
First letter: P
Second letter: y
Last letter: n
Slicing – Cutting Pieces
Want just part of your string? Slicing lets you extract a substring using the format [start:stop]. Python includes the start position but stops before the stop position:
sentence = "I love programming"
first_word = sentence[0:1] # Gets characters from 0 up to (but not including) 1
second_word = sentence[2:6] # Gets characters from 2 up to (but not including) 6
everything_after = sentence[7:] # Gets characters from 7 to the end
print(f"First: {first_word}")
print(f"Second: {second_word}")
print(f"Rest: {everything_after}")
Let’s trace through this:
sentence[0:1]: Position 0 only → “I”sentence[2:6]: Positions 2, 3, 4, 5 → “love”sentence[7:]: From position 7 to the end → “programming”
Output:
First: I
Second: love
Rest: programming
Case Conversion Methods – Changing Letter Sizes
upper() – Converting to Uppercase
The upper() method creates a new string where every letter is converted to uppercase. Numbers, spaces, and punctuation marks stay the same:
quiet_voice = "hello world"
loud_voice = quiet_voice.upper()
print(loud_voice)
print(f"Original is still: {quiet_voice}")
What happens:
- Python goes through each character in “hello world”
- For each letter, it converts it to uppercase
- Non-letter characters remain unchanged
- A new string “HELLO WORLD” is created
Output:
HELLO WORLD
Original is still: hello world
Notice the original string didn’t change. Strings in Python are immutable – you can’t modify them, only create new ones.
lower() – Converting to Lowercase
The lower() method does the opposite of upper() – it converts all letters to lowercase:
shouting = "I AM SO EXCITED ABOUT THIS!"
normal_voice = shouting.lower()
print(normal_voice)
Python processes each character:
- I → i
- A → a
- M → m
- Spaces and punctuation stay the same
Output: i am so excited about this!
title() – Converting to Title Case
The title() method capitalizes the first letter of each word. Python considers a word to be any sequence of letters that comes after a non-letter character:
book_name = "the adventures of tom sawyer"
proper_title = book_name.title()
print(proper_title)
How it works:
- Finds the start of each word (after spaces or at the beginning)
- Capitalizes the first letter of each word
- Makes the rest lowercase
Output: The Adventures Of Tom Sawyer
capitalize() – Capitalizing Only First Letter
The capitalize() method makes the first character uppercase and all other letters lowercase:
sentence = "python is useful"
proper_sentence = sentence.capitalize()
print(proper_sentence)
mixed_case = "pYTHoN iS uSeFuL"
also_proper = mixed_case.capitalize()
print(also_proper)
For both strings, only the very first character becomes uppercase, everything else becomes lowercase.
Output:
Python is useful
Python is useful
swapcase() – Flipping All Cases
The swapcase() method flips the case of every letter – uppercase becomes lowercase and vice versa:
mixed = "Hello World"
swapped = mixed.swapcase()
print(swapped)
Character by character transformation:
- H → h (uppercase to lowercase)
- e → E (lowercase to uppercase)
- l → L
- l → L
- o → O
- (space stays space)
- W → w
- o → O
- r → R
- l → L
- d → D
Output: hELLO wORLD
casefold() – Aggressive Lowercase
The casefold() method is like lower() but more thorough. It handles special characters from other languages that have complex case rules:
german_word = "Straße"
regular_lower = german_word.lower()
case_folded = german_word.casefold()
print(f"Regular lower: {regular_lower}")
print(f"Case folded: {case_folded}")
The German ß character has special rules. Regular lower() might not handle it, but casefold() converts it to “ss”.
Output:
Regular lower: straße
Case folded: strasse
Whitespace Handling Methods – Cleaning Up Spaces
strip() – Removing Whitespace from Both Ends
The strip() method removes whitespace characters (spaces, tabs, newlines) from the beginning and end of a string, but leaves whitespace in the middle alone:
messy_text = " Hello World "
clean_text = messy_text.strip()
print(f"Before: '{messy_text}'")
print(f"After: '{clean_text}'")
print(f"Length before: {len(messy_text)}")
print(f"Length after: {len(clean_text)}")
What strip() does:
- Looks at the beginning of the string
- Removes any whitespace characters it finds
- Looks at the end of the string
- Removes any whitespace characters from there too
- Leaves everything in the middle untouched
Output:
Before: ' Hello World '
After: 'Hello World'
Length before: 17
Length after: 11
lstrip() and rstrip() – One-Sided Cleaning
These methods clean only one side of your string:
text = " Hello World "
left_cleaned = text.lstrip() # Remove from left only
right_cleaned = text.rstrip() # Remove from right only
print(f"Original: '{text}'")
print(f"Left cleaned: '{left_cleaned}'")
print(f"Right cleaned: '{right_cleaned}'")
lstrip() (left strip) removes whitespace from the beginning:
- ” Hello World ” becomes “Hello World “
rstrip() (right strip) removes whitespace from the end:
- ” Hello World ” becomes ” Hello World”
Output:
Original: ' Hello World '
Left cleaned: 'Hello World '
Right cleaned: ' Hello World'
Removing Specific Characters
You can tell strip() to remove specific characters instead of just whitespace:
website = "www.example.com"
without_www = website.lstrip("w.")
print(f"Original: {website}")
print(f"Without www.: {without_www}")
phone = "++1-555-123-4567++"
clean_phone = phone.strip("+")
print(f"Phone: {phone}")
print(f"Clean: {clean_phone}")
lstrip("w.") removes any combination of ‘w’ and ‘.’ characters from the left:
- First it removes ‘w’ characters: “www.example.com” → “.example.com”
- Then it removes ‘.’ characters: “.example.com” → “example.com”
Output:
Original: www.example.com
Without www.: example.com
Phone: ++1-555-123-4567++
Clean: 1-555-123-4567
Search and Check Methods – Finding Things in Text
in and not in – Simple Membership Testing
These operators check if one string exists inside another string. They return True or False:
sentence = "I love to code in Python"
print("Python" in sentence) # True
print("Java" in sentence) # False
print("Ruby" not in sentence) # True
print("love" in sentence) # True
print("Love" in sentence) # False (case matters!)
How it works:
- Python scans through the entire sentence
- Looks for an exact match of the search string
- Returns True if found anywhere, False otherwise
- Case-sensitive: “Python” ≠ “python”
Output:
True
False
True
True
False
find() – Locating Text Position
The find() method tells you exactly where a substring starts within your string. If it can’t find the substring, it returns -1:
text = "Hello, welcome to Python programming"
python_position = text.find("Python")
welcome_position = text.find("welcome")
missing_position = text.find("Java")
print(f"'Python' starts at position: {python_position}")
print(f"'welcome' starts at position: {welcome_position}")
print(f"'Java' position: {missing_position}")
Let’s trace through finding “Python”:
- Position 0-5: “Hello,”
- Position 6-7: ” w”
- Position 8-17: “elcome to “
- Position 18-23: “Python” ← Found it!
Output:
'Python' starts at position: 18
'welcome' starts at position: 7
'Java' position: -1
index() – Like find() but Stricter
The index() method works exactly like find(), but instead of returning -1 when the substring isn’t found, it raises a ValueError:
text = "Hello World"
world_position = text.index("World")
print(f"'World' is at position: {world_position}")
# This would crash your program:
try:
error_position = text.index("Python")
except ValueError:
print("'Python' not found - index() threw an error")
When to use which:
- Use
find()when you’re not sure if the text exists - Use
index()when you know the text is there and want your program to crash if it’s not
Output:
'World' is at position: 6
'Python' not found - index() threw an error
rfind() and rindex() – Searching from the Right
These methods work like find() and index(), but they start searching from the right side of the string:
text = "banana"
first_a = text.find("a") # Finds first 'a' from left
last_a = text.rfind("a") # Finds first 'a' from right (which is the last one)
print(f"String: {text}")
print(f"Positions: 0=b, 1=a, 2=n, 3=a, 4=n, 5=a")
print(f"First 'a' from left: position {first_a}")
print(f"First 'a' from right: position {last_a}")
In “banana”:
find("a")scans left-to-right: position 1 is the first ‘a’rfind("a")scans right-to-left: position 5 is the first ‘a’ it encounters
Output:
String: banana
Positions: 0=b, 1=a, 2=n, 3=a, 4=n, 5=a
First 'a' from left: position 1
First 'a' from right: position 5
count() – Counting Occurrences
The count() method tells you how many times a substring appears in your string. It counts non-overlapping occurrences:
tongue_twister = "She sells seashells by the seashore"
s_count = tongue_twister.count("s")
sea_count = tongue_twister.count("sea")
shell_count = tongue_twister.count("shell")
print(f"Text: {tongue_twister}")
print(f"Letter 's' appears: {s_count} times")
print(f"Word 'sea' appears: {sea_count} times")
print(f"Word 'shell' appears: {shell_count} times")
Let’s count the ‘s’ letters manually: “She sells seashells by the seashore”
That’s 8 occurrences of ‘s’ (including uppercase ‘S’).
Output:
Text: She sells seashells by the seashore
Letter 's' appears: 8 times
Word 'sea' appears: 3 times
Word 'shell' appears: 1 times
String Checking Methods – Asking Yes/No Questions
startswith() and endswith() – Checking Beginnings and Endings
These methods check if your string begins or ends with specific text. Very useful for file extensions, URLs, or data validation:
filename = "document.pdf"
email = "john@email.com"
url = "https://www.example.com"
print(f"'{filename}' is a PDF: {filename.endswith('.pdf')}")
print(f"'{filename}' starts with 'doc': {filename.startswith('doc')}")
print(f"'{email}' is Gmail: {email.endswith('@gmail.com')}")
print(f"'{url}' is secure: {url.startswith('https://')}")
How startswith() works:
- Takes the beginning of your string
- Compares it character-by-character with the test string
- Returns True if they match exactly
How endswith() works:
- Takes the ending of your string
- Compares it character-by-character with the test string
- Returns True if they match exactly
Output:
'document.pdf' is a PDF: True
'document.pdf' starts with 'doc': True
'john@email.com' is Gmail: False
'https://www.example.com' is secure: True
isdigit() – Testing for Numbers Only
The isdigit() method returns True only if every character in the string is a digit (0-9) and there’s at least one character:
age = "25"
name = "John"
mixed = "25abc"
empty = ""
with_space = "2 5"
print(f"'{age}' is all digits: {age.isdigit()}")
print(f"'{name}' is all digits: {name.isdigit()}")
print(f"'{mixed}' is all digits: {mixed.isdigit()}")
print(f"'{empty}' is all digits: {empty.isdigit()}")
print(f"'{with_space}' is all digits: {with_space.isdigit()}")
Character-by-character analysis:
- “25”: ‘2’ is digit ✓, ‘5’ is digit ✓ → True
- “John”: ‘J’ is not digit ✗ → False
- “25abc”: ‘2’ is digit ✓, ‘5’ is digit ✓, ‘a’ is not digit ✗ → False
- “”: Empty string → False
- “2 5”: ‘2’ is digit ✓, ‘ ‘ is not digit ✗ → False
Output:
'25' is all digits: True
'John' is all digits: False
'25abc' is all digits: False
'' is all digits: False
'2 5' is all digits: False
isalpha() – Testing for Letters Only
The isalpha() method returns True only if every character is a letter (a-z, A-Z) and there’s at least one character:
name = "Sarah"
mixed = "Sarah123"
with_space = "Sarah Jane"
accented = "José"
empty = ""
print(f"'{name}' is all letters: {name.isalpha()}")
print(f"'{mixed}' is all letters: {mixed.isalpha()}")
print(f"'{with_space}' is all letters: {with_space.isalpha()}")
print(f"'{accented}' is all letters: {accented.isalpha()}")
print(f"'{empty}' is all letters: {empty.isalpha()}")
Character-by-character analysis:
- “Sarah”: All characters (S, a, r, a, h) are letters → True
- “Sarah123”: Letters S,a,r,a,h are OK, but 1,2,3 are digits → False
- “Sarah Jane”: Letters are OK, but space is not a letter → False
- “José”: All characters including accented ‘é’ are letters → True
Output:
'Sarah' is all letters: True
'Sarah123' is all letters: False
'Sarah Jane' is all letters: False
'José' is all letters: True
'' is all letters: False
isalnum() – Testing for Letters and Numbers Only
The isalnum() method returns True if every character is either a letter or a digit, with at least one character total:
username1 = "user123"
username2 = "user_123" # Contains underscore
password = "abc123"
with_space = "abc 123" # Contains space
empty = ""
print(f"'{username1}' is alphanumeric: {username1.isalnum()}")
print(f"'{username2}' is alphanumeric: {username2.isalnum()}")
print(f"'{password}' is alphanumeric: {password.isalnum()}")
print(f"'{with_space}' is alphanumeric: {with_space.isalnum()}")
print(f"'{empty}' is alphanumeric: {empty.isalnum()}")
Analysis:
- “user123”: u,s,e,r are letters ✓, 1,2,3 are digits ✓ → True
- “user_123”: u,s,e,r are letters ✓, _ is neither letter nor digit ✗ → False
- “abc123”: a,b,c are letters ✓, 1,2,3 are digits ✓ → True
- “abc 123”: Letters and digits are OK, but space fails the test → False
Output:
'user123' is alphanumeric: True
'user_123' is alphanumeric: False
'abc123' is alphanumeric: True
'abc 123' is alphanumeric: False
'' is alphanumeric: False
islower() and isupper() – Checking Case
These methods check if all letters in the string are lowercase or uppercase respectively. Non-letter characters are ignored:
text1 = "hello world"
text2 = "HELLO WORLD"
text3 = "Hello World"
text4 = "hello123"
text5 = "123"
print(f"'{text1}' is all lowercase: {text1.islower()}")
print(f"'{text2}' is all uppercase: {text2.isupper()}")
print(f"'{text3}' is all lowercase: {text3.islower()}")
print(f"'{text4}' is all lowercase: {text4.islower()}")
print(f"'{text5}' is all lowercase: {text5.islower()}")
How it works:
- Find all letter characters in the string
- If at least one letter exists and ALL letters are lowercase →
islower()returns True - If at least one letter exists and ALL letters are uppercase →
isupper()returns True - Numbers, spaces, punctuation don’t affect the result
Output:
'hello world' is all lowercase: True
'HELLO WORLD' is all uppercase: True
'Hello World' is all lowercase: False
'hello123' is all lowercase: True
'123' is all lowercase: False
isspace() – Testing for Whitespace Only
The isspace() method returns True if the string contains only whitespace characters (spaces, tabs, newlines) and is not empty:
spaces = " "
tab_and_newline = "\t\n "
not_space = "hello "
empty = ""
single_space = " "
print(f"'{spaces}' is only whitespace: {spaces.isspace()}")
print(f"Tab and newline combo is whitespace: {tab_and_newline.isspace()}")
print(f"'{not_space}' is only whitespace: {not_space.isspace()}")
print(f"'{empty}' is only whitespace: {empty.isspace()}")
print(f"'{single_space}' is only whitespace: {single_space.isspace()}")
Whitespace characters include:
- Regular space: ” “
- Tab: “\t”
- Newline: “\n”
- Carriage return: “\r”
- And several others
Output:
' ' is only whitespace: True
Tab and newline combo is whitespace: True
'hello ' is only whitespace: False
'' is only whitespace: False
' ' is only whitespace: True
istitle() – Checking Title Case
The istitle() method returns True if the string is in title case – meaning the first letter of each word is uppercase and all other letters are lowercase:
title1 = "The Great Gatsby"
title2 = "the great gatsby"
title3 = "THE GREAT GATSBY"
title4 = "The great Gatsby"
title5 = "123 Main Street"
print(f"'{title1}' is title case: {title1.istitle()}")
print(f"'{title2}' is title case: {title2.istitle()}")
print(f"'{title3}' is title case: {title3.istitle()}")
print(f"'{title4}' is title case: {title4.istitle()}")
print(f"'{title5}' is title case: {title5.istitle()}")
Rules for title case:
- First letter of each word must be uppercase
- All other letters in the word must be lowercase
- Words are separated by non-letter characters
Analysis:
- “The Great Gatsby”: T-he, G-reat, G-atsby all follow the pattern → True
- “the great gatsby”: First letters are not uppercase → False
- “THE GREAT GATSBY”: Non-first letters are not lowercase → False
- “The great Gatsby”: “great” doesn’t start with uppercase → False
Output:
'The Great Gatsby' is title case: True
'the great gatsby' is title case: False
'THE GREAT GATSBY' is title case: False
'The great Gatsby' is title case: False
'123 Main Street' is title case: True
Splitting and Joining – Breaking Apart and Putting Together
split() – Breaking Text into a List
The split() method cuts your string into pieces and returns them as a list. By default, it splits on any whitespace (spaces, tabs, newlines):
sentence = "I love to code in Python"
words = sentence.split()
print(f"Original: {sentence}")
print(f"Split result: {words}")
print(f"Type of result: {type(words)}")
print(f"Number of words: {len(words)}")
What happens step by step:
- Python finds all whitespace characters in the string
- Uses them as cutting points
- Takes everything between the cutting points
- Puts each piece into a list
- Removes the whitespace characters
Output:
Original: I love to code in Python
Split result: ['I', 'love', 'to', 'code', 'in', 'Python']
Type of result: <class 'list'>
Number of words: 6
You can also split on specific characters:
email = "john.doe@company.com"
at_split = email.split("@")
dot_split = email.split(".")
print(f"Email: {email}")
print(f"Split on @: {at_split}")
print(f"Split on .: {dot_split}")
csv_data = "apple,banana,orange,grape"
fruits = csv_data.split(",")
print(f"CSV data: {csv_data}")
print(f"Individual fruits: {fruits}")
When you specify a separator:
email.split("@")cuts at every @ symbolcsv_data.split(",")cuts at every comma
Output:
Email: john.doe@company.com
Split on @: ['john.doe', 'company.com']
Split on .: ['john', 'doe@company', 'com']
CSV data: apple,banana,orange,grape
Individual fruits: ['apple', 'banana', 'orange', 'grape']
rsplit() – Splitting from the Right
The rsplit() method works like split(), but starts from the right side. This matters when you limit the number of splits:
path = "home/user/documents/file.txt"
normal_split = path.split("/", 2) # Split only twice, from left
right_split = path.rsplit("/", 1) # Split only once, from right
print(f"Original path: {path}")
print(f"Normal split (2 times): {normal_split}")
print(f"Right split (1 time): {right_split}")
# Practical use - separating filename from directory
directory = right_split[0]
filename = right_split[1]
print(f"Directory: {directory}")
print(f"Filename: {filename}")
Comparison:
split("/", 2)from left: “home” / “user” / “documents/file.txt”rsplit("/", 1)from right: “home/user/documents” / “file.txt”
Output:
Original path: home/user/documents/file.txt
Normal split (2 times): ['home', 'user', 'documents/file.txt']
Right split (1 time): ['home/user/documents', 'file.txt']
Directory: home/user/documents
Filename: file.txt
splitlines() – Splitting on Line Breaks
The splitlines() method splits a string wherever there are line breaks (\n, \r\n, etc.):
multi_line = """First line
Second line
Third line
Fourth line"""
lines = multi_line.splitlines()
print("Individual lines:")
for i, line in enumerate(lines, 1):
print(f"Line {i}: '{line}'")
print(f"\nTotal lines: {len(lines)}")
What splitlines() recognizes as line breaks:
- \n (Unix/Linux/Mac)
- \r\n (Windows)
- \r (Old Mac)
Output:
Individual lines:
Line 1: 'First line'
Line 2: 'Second line'
Line 3: 'Third line'
Line 4: 'Fourth line'
Total lines: 4
join() – Putting Pieces Back Together
The join() method is the opposite of split(). It takes a list of strings and glues them together using a separator:
words = ['Python', 'is', 'useful']
space_joined = ' '.join(words)
dash_joined = '-'.join(words)
no_separator = ''.join(words)
print(f"Word list: {words}")
print(f"Joined with spaces: {space_joined}")
print(f"Joined with dashes: {dash_joined}")
print(f"Joined with nothing: {no_separator}")
How join() works:
- Takes the separator string (what’s before .join)
- Places it between each item in the list
- Concatenates everything into one string
Note the syntax: separator.join(list), not list.join(separator)
Output:
Word list: ['Python', 'is', 'useful']
Joined with spaces: Python is useful
Joined with dashes: Python-is-useful
Joined with nothing: Pythonisuseful
More practical examples:
# Creating file paths
path_parts = ['home', 'user', 'documents', 'file.txt']
unix_path = '/'.join(path_parts)
windows_path = '\\'.join(path_parts)
print(f"Unix path: /{unix_path}")
print(f"Windows path: {windows_path}")
# Creating phone numbers
phone_parts = ['555', '123', '4567']
phone_number = '-'.join(phone_parts)
print(f"Phone number: {phone_number}")
Output:
Unix path: /home/user/documents/file.txt
Windows path: home\user\documents\file.txt
Phone number: 555-123-4567
partition() and rpartition() – Three-Way Splits
The partition() method splits a string into exactly three parts: everything before a separator, the separator itself, and everything after. If the separator isn’t found, you get the original string plus two empty strings:
email = "john.doe@company.com"
username, at_symbol, domain = email.partition("@")
print(f"Original email: {email}")
print(f"Username part: '{username}'")
print(f"Separator: '{at_symbol}'")
print(f"Domain part: '{domain}'")
# What happens when separator isn't found
no_at = "invalid.email.com"
part1, separator, part2 = no_at.partition("@")
print(f"\nNo @ symbol found:")
print(f"Part 1: '{part1}'")
print(f"Separator: '{separator}'")
print(f"Part 2: '{part2}'")
How partition() works:
- Finds the first occurrence of the separator
- Splits the string at that point
- Returns exactly three strings: before, separator, after
Output:
Original email: john.doe@company.com
Username part: 'john.doe'
Separator: '@'
Domain part: 'company.com'
No @ symbol found:
Part 1: 'invalid.email.com'
Separator: ''
Part 2: ''
The rpartition() method works the same way but finds the last occurrence of the separator:
url = "https://www.example.com/blog/post.html"
base, separator, page = url.rpartition("/")
print(f"URL: {url}")
print(f"Base URL: '{base}'")
print(f"Separator: '{separator}'")
print(f"Page: '{page}'")
# Compare with regular partition
base2, sep2, page2 = url.partition("/")
print(f"\nUsing partition (finds first /):")
print(f"Part 1: '{base2}'")
print(f"Separator: '{sep2}'")
print(f"Part 2: '{page2}'")
Output:
URL: https://www.example.com/blog/post.html
Base URL: 'https://www.example.com/blog'
Separator: '/'
Page: 'post.html'
Using partition (finds first /):
Part 1: 'https:'
Separator: '/'
Part 2: '/www.example.com/blog/post.html'
Replacement Methods – Changing Text
replace() – Substituting Text
The replace() method creates a new string where all occurrences of one substring are replaced with another. You can optionally limit how many replacements to make:
sentence = "I love cats and cats love me"
new_sentence = sentence.replace("cats", "dogs")
print(f"Original: {sentence}")
print(f"All replaced: {new_sentence}")
# Limit the number of replacements
limited_replace = sentence.replace("cats", "dogs", 1)
print(f"Only first replaced: {limited_replace}")
# Replace with empty string (deletion)
no_cats = sentence.replace("cats", "")
print(f"Cats removed: {no_cats}")
How replace() works:
- Scans through the string from left to right
- Finds each occurrence of the old substring
- Replaces it with the new substring
- Continues until done or limit reached
Output:
Original: I love cats and cats love me
All replaced: I love dogs and dogs love me
Only first replaced: I love dogs and cats love me
Cats removed: I love and love me
Case sensitivity matters:
text = "Python is fun. python is powerful."
replaced = text.replace("python", "Java")
print(f"Original: {text}")
print(f"Replaced: {replaced}")
Only the lowercase “python” gets replaced because “Python” has a capital P.
Output:
Original: Python is fun. python is powerful.
Replaced: Python is fun. Java is powerful.
expandtabs() – Converting Tabs to Spaces
The expandtabs() method replaces tab characters (\t) with spaces. By default, it assumes tab stops every 8 characters:
tabbed_text = "Name\tAge\tCity"
default_expanded = tabbed_text.expandtabs()
custom_expanded = tabbed_text.expandtabs(4)
print(f"Original with tabs: '{tabbed_text}'")
print(f"Default (8 spaces): '{default_expanded}'")
print(f"Custom (4 spaces): '{custom_expanded}'")
# Show the actual character counts
print(f"Default length: {len(default_expanded)}")
print(f"Custom length: {len(custom_expanded)}")
How tab expansion works:
- Each \t is replaced with enough spaces to reach the next tab stop
- Tab stops occur at regular intervals (default 8)
- If text before the tab is shorter than the tab stop, spaces fill to that position
Output:
Original with tabs: 'Name Age City'
Default (8 spaces): 'Name Age City'
Custom (4 spaces): 'Name Age City'
Default length: 16
Custom length: 12
Alignment and Padding Methods – Making Text Look Pretty
center() – Centering Text
The center() method creates a new string of a specified width with the original text centered. You can optionally specify a fill character:
title = "MENU"
centered_default = title.center(20)
centered_with_stars = title.center(20, "*")
centered_with_dashes = title.center(15, "-")
print(f"Original: '{title}'")
print(f"Centered default: '{centered_default}'")
print(f"Centered with stars: '{centered_with_stars}'")
print(f"Centered with dashes: '{centered_with_dashes}'")
How center() calculates positioning:
- Takes the desired width (20 characters)
- Subtracts the length of original text (4 characters)
- Remaining space (16 characters) gets split evenly on both sides
- If odd remainder, extra character goes on the right
Output:
Original: 'MENU'
Centered default: ' MENU '
Centered with stars: '********MENU********'
Centered with dashes: '-----MENU------'
If the original string is already longer than the specified width, center() returns the original string unchanged:
long_title = "This is a very long menu title"
result = long_title.center(10)
print(f"Long title centered: '{result}'")
print(f"Length: {len(result)}")
Output:
Long title centered: 'This is a very long menu title'
Length: 30
ljust() and rjust() – Left and Right Alignment
These methods pad a string to a specified width, aligning the text to the left or right:
items = ["Apple", "Banana", "Orange"]
prices = ["$1.50", "$2.00", "$1.25"]
print("PRICE LIST")
print("-" * 25)
for item, price in zip(items, prices):
# Left-align item names in 15 characters, right-align prices in 8
formatted_item = item.ljust(15)
formatted_price = price.rjust(8)
print(f"{formatted_item}{formatted_price}")
How the alignment works:
ljust(15)makes each item name exactly 15 characters by adding spaces on the rightrjust(8)makes each price exactly 8 characters by adding spaces on the left
Output:
PRICE LIST
-------------------------
Apple $1.50
Banana $2.00
Orange $1.25
You can also specify a fill character:
text = "Hello"
left_padded = text.ljust(10, ".")
right_padded = text.rjust(10, ".")
print(f"Left justified: '{left_padded}'")
print(f"Right justified: '{right_padded}'")
Output:
Left justified: 'Hello.....'
Right justified: '.....Hello'
zfill() – Adding Zeros to the Left
The zfill() method is specifically designed for numbers. It pads a string with zeros on the left to reach a specified width:
numbers = ["1", "23", "456", "7890"]
for num in numbers:
padded = num.zfill(5)
print(f"Original: {num:>4} → Padded: {padded}")
# Works with negative numbers too
negative = "-42"
padded_negative = negative.zfill(6)
print(f"Negative: {negative} → Padded: {padded_negative}")
How zfill() works:
- If string starts with + or -, the sign stays at the beginning
- Zeros are added after the sign but before the digits
- If string is already long enough, returns original
Output:
Original: 1 → Padded: 00001
Original: 23 → Padded: 00023
Original: 456 → Padded: 00456
Original: 7890 → Padded: 07890
Negative: -42 → Padded: -00042
String Formatting – Making Text Look Professional
format() Method – The Traditional Approach
The format() method lets you create templates with placeholders that get filled in with values. There are several ways to specify placeholders:
name = "Alice"
age = 30
salary = 75000.50
# Positional placeholders (filled in order)
message1 = "Hello, my name is {} and I am {} years old.".format(name, age)
print(message1)
# Numbered placeholders (specify which argument goes where)
message2 = "I am {1} years old and my name is {0}.".format(name, age)
print(message2)
# Named placeholders (use descriptive names)
message3 = "Name: {person}, Age: {years}, Salary: ${money:.2f}".format(
person=name, years=age, money=salary
)
print(message3)
How the placeholders work:
{}gets filled with arguments in order{0},{1}let you specify which argument by position{name}lets you use keyword arguments:.2fformats numbers (2 decimal places for floats)
Output:
Hello, my name is Alice and I am 30 years old.
I am 30 years old and my name is Alice.
Name: Alice, Age: 30, Salary: $75000.50
f-strings – The Modern Way (Python 3.6+)
F-strings (formatted string literals) let you put variables and expressions directly inside strings by prefixing with f:
name = "Bob"
age = 25
height = 5.9
# Basic f-string usage
intro = f"Hi, I'm {name} and I'm {age} years old"
print(intro)
# You can put calculations directly inside
next_year = f"Next year I'll be {age + 1}"
print(next_year)
# Format numbers with precision
precise_height = f"I'm {height:.1f} feet tall"
print(precise_height)
# Conditional expressions work too
status = f"I am {'an adult' if age >= 18 else 'a minor'}"
print(status)
What happens with f-strings:
- Python evaluates everything inside
{} - Converts the result to a string
- Inserts it into the final string
Output:
Hi, I'm Bob and I'm 25 years old
Next year I'll be 26
I'm 5.9 feet tall
I am an adult
Multi-line f-strings work too:
name = "Charlie"
age = 35
city = "Denver"
bio = f"""
Personal Information:
Name: {name}
Age: {age}
City: {city}
Born in: {2024 - age}
"""
print(bio)
Output:
Personal Information:
Name: Charlie
Age: 35
City: Denver
Born in: 1989
Number Formatting in Strings
Both format() and f-strings support detailed number formatting:
number = 1234.5678
percentage = 0.847
large_number = 1234567
print("Different number formats:")
print(f"Original: {number}")
print(f"2 decimals: {number:.2f}")
print(f"No decimals: {number:.0f}")
print(f"With commas: {number:,.2f}")
print(f"Percentage: {percentage:.1%}")
print(f"Scientific: {large_number:.2e}")
print(f"Padded: {number:10.2f}")
print(f"Zero-padded: {number:010.2f}")
Format code breakdown:
.2f: 2 decimal places, floating point.0f: No decimal places,.2f: Add commas as thousands separators.1%: Convert to percentage with 1 decimal.2e: Scientific notation with 2 decimals10.2f: Total width of 10, 2 decimals010.2f: Pad with zeros to width 10
Output:
Different number formats:
Original: 1234.5678
2 decimals: 1234.57
No decimals: 1235
With commas: 1,234.57
Percentage: 84.7%
Scientific: 1.23e+06
Padded: 1234.57
Zero-padded: 0001234.57
Encoding and Decoding – Different Text Formats
Understanding Text Encoding
When computers store text, they convert characters to numbers using an encoding scheme. The most common is UTF-8, which can handle any character from any language:
text = "Hello, 世界" # Mix of English and Chinese
# Convert string to bytes using UTF-8 encoding
utf8_bytes = text.encode('utf-8')
print(f"Original text: {text}")
print(f"UTF-8 bytes: {utf8_bytes}")
print(f"Type of bytes: {type(utf8_bytes)}")
print(f"Length in characters: {len(text)}")
print(f"Length in bytes: {len(utf8_bytes)}")
What happens during encoding:
- Each character gets converted to one or more bytes
- English characters (H, e, l, l, o) take 1 byte each
- Chinese characters (世, 界) take 3 bytes each in UTF-8
- Result is a bytes object, not a string
Output:
Original text: Hello, 世界
UTF-8 bytes: b'Hello, \xe4\xb8\x96\xe7\x95\x8c'
Type of bytes: <class 'bytes'>
Length in characters: 8
Length in bytes: 12
decode() – Converting Bytes Back to Text
The decode() method converts bytes back into a readable string:
# Start with some bytes
utf8_bytes = b'Hello, \xe4\xb8\x96\xe7\x95\x8c'
# Convert back to string
decoded_text = utf8_bytes.decode('utf-8')
print(f"Bytes: {utf8_bytes}")
print(f"Decoded: {decoded_text}")
print(f"Type after decoding: {type(decoded_text)}")
# You must use the same encoding that was used to encode
try:
wrong_decode = utf8_bytes.decode('ascii') # This will fail
except UnicodeDecodeError as e:
print(f"Error with wrong encoding: {e}")
Output:
Bytes: b'Hello, \xe4\xb8\x96\xe7\x95\x8c'
Decoded: Hello, 世界
Type after decoding: <class 'str'>
Error with wrong encoding: 'ascii' codec can't decode byte 0xe4 in position 7: ordinal not in range(128)
Different Encoding Examples
text = "Café naïve résumé" # Text with accented characters
# Try different encodings
encodings = ['utf-8', 'latin-1', 'ascii']
for encoding in encodings:
try:
encoded = text.encode(encoding)
decoded = encoded.decode(encoding)
print(f"{encoding:10}: {encoded} → {decoded}")
except UnicodeEncodeError as e:
print(f"{encoding:10}: Can't encode - {e}")
except UnicodeDecodeError as e:
print(f"{encoding:10}: Can't decode - {e}")
How different encodings handle the same text:
- UTF-8: Can handle any character, variable byte length
- Latin-1: Handles most European characters, 1 byte per character
- ASCII: Only basic English characters, will fail on accents
Output:
utf-8 : b'Caf\xc3\xa9 na\xc3\xafve r\xc3\xa9sum\xc3\xa9' → Café naïve résumé
latin-1 : b'Caf\xe9 na\xefve r\xe9sum\xe9' → Café naïve résumé
ascii : Can't encode - 'ascii' codec can't encode character 'é' in position 3: ordinal not in range(128)
String Translation and Character Mapping
maketrans() and translate() – Advanced Character Replacement
The maketrans() method creates a translation table that maps characters to other characters. The translate() method uses this table to perform fast character substitutions:
# Create a simple cipher where vowels become numbers
vowels = "aeiou"
numbers = "12345"
cipher_table = str.maketrans(vowels, numbers)
text = "Hello world, how are you today?"
secret_text = text.translate(cipher_table)
print(f"Original: {text}")
print(f"Secret: {secret_text}")
print(f"Translation table type: {type(cipher_table)}")
How the translation works:
maketrans(vowels, numbers)creates a mapping: a→1, e→2, i→3, o→4, u→5translate()goes through each character in the text- If character is in the table, replaces it; otherwise leaves it unchanged
Output:
Original: Hello world, how are you today?
Secret: H2ll4 w4rld, h4w 1r2 y45 t4d1y?
Translation table type: <class 'dict'>
Removing Characters with Translation
You can also use maketrans() to remove characters by mapping them to None:
text = "Hello, World! How are you today?"
# Remove all vowels
remove_vowels_table = str.maketrans("", "", "aeiouAEIOU")
no_vowels = text.translate(remove_vowels_table)
# Remove punctuation
import string
remove_punct_table = str.maketrans("", "", string.punctuation)
no_punctuation = text.translate(remove_punct_table)
print(f"Original: {text}")
print(f"No vowels: {no_vowels}")
print(f"No punctuation: {no_punctuation}")
The three arguments to maketrans():
- Characters to replace (empty string when just removing)
- Replacement characters (empty string when just removing)
- Characters to remove (delete these entirely)
Output:
Original: Hello, World! How are you today?
No vowels: Hll, Wrld! Hw r y tdy?
No punctuation: Hello World How are you today
More Complex Translation Examples
# ROT13 cipher (shift each letter by 13 positions)
import string
lowercase = string.ascii_lowercase
uppercase = string.ascii_uppercase
# Create shifted alphabets
rot13_lower = lowercase[13:] + lowercase[:13]
rot13_upper = uppercase[13:] + uppercase[:13]
# Combine into one translation table
rot13_table = str.maketrans(
lowercase + uppercase,
rot13_lower + rot13_upper
)
message = "Hello World! This is a secret message."
encoded = message.translate(rot13_table)
decoded = encoded.translate(rot13_table) # ROT13 is its own inverse
print(f"Original: {message}")
print(f"ROT13: {encoded}")
print(f"Decoded: {decoded}")
How ROT13 works:
- Each letter shifts 13 positions in the alphabet
- A becomes N, B becomes O, etc.
- Since there are 26 letters, applying ROT13 twice gets you back to the original
Output:
Original: Hello World! This is a secret message.
ROT13: Uryyb Jbeyq! Guvf vf n frperg zrffntr.
Decoded: Hello World! This is a secret message.
Performance Considerations – Writing Efficient String Code
String Concatenation Performance
When you need to build strings from many pieces, the method you choose makes a huge difference in performance:
import time
# Slow way - repeatedly using +=
def slow_concatenation(items):
result = ""
for item in items:
result += f"Item: {item}\n"
return result
# Fast way - build list then join
def fast_concatenation(items):
parts = []
for item in items:
parts.append(f"Item: {item}\n")
return ''.join(parts)
# Test with lots of items
test_items = range(1000)
# Time the slow method
start = time.time()
slow_result = slow_concatenation(test_items)
slow_time = time.time() - start
# Time the fast method
start = time.time()
fast_result = fast_result = fast_concatenation(test_items)
fast_time = time.time() - start
print(f"Slow method took: {slow_time:.4f} seconds")
print(f"Fast method took: {fast_time:.4f} seconds")
print(f"Fast method is {slow_time/fast_time:.1f}x faster")
print(f"Both results are identical: {slow_result == fast_result}")
Why += is slow with strings:
- Strings are immutable in Python
- Each
+=creates a completely new string - For 1000 items, you’re creating 1000 new string objects
join()only creates one final string object
Output (results vary by computer):
Slow method took: 0.0123 seconds
Fast method took: 0.0008 seconds
Fast method is 15.4x faster
Both results are identical: True
Memory-Efficient String Building
For very large strings, consider using io.StringIO:
import io
import sys
def build_with_stringio(items):
buffer = io.StringIO()
for item in items:
buffer.write(f"Processing item {item}\n")
return buffer.getvalue()
# Compare memory usage
test_data = range(10000)
result = build_with_stringio(test_data)
print(f"Built string with {len(result)} characters")
print(f"First 100 characters: {result[:100]}...")
StringIO works like a file in memory:
- You write to it piece by piece
- No intermediate string objects are created
getvalue()returns the final complete string
String Comparison Performance
Different comparison methods have different performance characteristics:
# Case-insensitive comparison methods
text1 = "Hello World"
text2 = "HELLO WORLD"
# Method 1: Convert both to lowercase
def compare_lower(s1, s2):
return s1.lower() == s2.lower()
# Method 2: Use casefold (better for international text)
def compare_casefold(s1, s2):
return s1.casefold() == s2.casefold()
# Method 3: Convert once and store
def compare_preconverted():
lower1 = text1.lower()
lower2 = text2.lower()
return lower1 == lower2
print(f"Method 1 result: {compare_lower(text1, text2)}")
print(f"Method 2 result: {compare_casefold(text1, text2)}")
print(f"Method 3 result: {compare_preconverted()}")
# For international text, casefold is more reliable
international1 = "Straße" # German
international2 = "STRASSE"
print(f"International comparison: {compare_casefold(international1, international2)}")
Output:
Method 1 result: True
Method 2 result: True
Method 3 result: True
International comparison: True
Common Mistakes and How to Avoid Them
Mistake 1: Forgetting Strings Are Immutable
Many beginners expect string methods to change the original string:
# Wrong approach - the original string doesn't change
text = "hello world"
text.upper() # This creates a new string but doesn't save it
print(f"Text is still: {text}")
# Correct approach - assign the result back
text = "hello world"
text = text.upper() # Save the new string
print(f"Now text is: {text}")
# Another common mistake with replace()
message = "I love Python and Python loves me"
message.replace("Python", "Java") # Doesn't change message!
print(f"Message unchanged: {message}")
# Fix it
message = message.replace("Python", "Java")
print(f"Now message is: {message}")
Why this happens:
- Strings in Python cannot be changed after creation
- Methods like
upper(),replace(), etc. return new strings - You must assign the result to a variable to keep it
Output:
Text is still: hello world
Now text is: HELLO WORLD
Message unchanged: I love Python and Python loves me
Now message is: I love Java and Java loves me
Mistake 2: Case-Sensitive Comparisons
Many beginners forget that string comparisons are case-sensitive:
user_input = "YES"
# Wrong - this won't work
if user_input == "yes":
print("User agreed") # This won't print
else:
print("User said something else")
# Right - convert to consistent case
if user_input.lower() == "yes":
print("User agreed") # This will print
# Even better - handle multiple variations
valid_yes = ["yes", "y", "true", "1", "ok"]
if user_input.lower() in valid_yes:
print("User agreed")
Best practices:
- Always convert to lowercase for comparisons
- Consider all possible variations users might type
- Make your program flexible and user-friendly
Output:
User said something else
User agreed
User agreed
Mistake 3: Not Handling Edge Cases
Real-world data is messy. Your code should handle empty strings, None values, and unexpected input:
def safe_string_operation(text):
"""A function that handles edge cases properly"""
# Check for None
if text is None:
return "No text provided"
# Check for empty string
if not text or text.isspace():
return "Empty text provided"
# Check if it's actually a string
if not isinstance(text, str):
text = str(text) # Convert to string
# Now we can safely process it
return text.strip().title()
# Test with various problematic inputs
test_inputs = [
None,
"",
" ",
"hello world",
123,
["not", "a", "string"]
]
for inp in test_inputs:
result = safe_string_operation(inp)
print(f"Input: {repr(inp):20} → Output: {result}")
Edge cases to always consider:
- None values
- Empty strings
- Strings with only whitespace
- Non-string types
- Very long strings
- Strings with special characters
Output:
Input: None → Output: No text provided
Input: '' → Output: Empty text provided
Input: ' ' → Output: Empty text provided
Input: 'hello world' → Output: Hello World
Input: 123 → Output: 123
Input: ['not', 'a', 'string'] → Output: ['Not', 'A', 'String']
Mistake 4: Inefficient String Building
Building strings in loops the wrong way can make your program very slow:
# Wrong way - very slow for large amounts of data
def build_html_wrong(items):
html = "<ul>"
for item in items:
html += f"<li>{item}</li>" # Creates new string each time
html += "</ul>"
return html
# Right way - much faster
def build_html_right(items):
parts = ["<ul>"]
for item in items:
parts.append(f"<li>{item}</li>")
parts.append("</ul>")
return ''.join(parts)
# Test with a reasonable amount of data
test_items = [f"Item {i}" for i in range(100)]
html1 = build_html_wrong(test_items)
html2 = build_html_right(test_items)
print(f"Both methods produce identical results: {html1 == html2}")
print(f"HTML length: {len(html1)} characters")
print(f"First 100 characters: {html1[:100]}...")
Why the first method is slow:
- Each
+=creates a completely new string - For 100 items, you create 100 string objects
- Memory usage grows quadratically
Output:
Both methods produce identical results: True
HTML length: 1111 characters
First 100 characters: <ul><li>Item 0</li><li>Item 1</li><li>Item 2</li><li>Item 3</li><li>Item 4</li><li>Item 5</li>...
Mistake 5: Incorrect String Splitting
Splitting strings can be tricky when dealing with real-world data:
# Problem: splitting names
full_names = [
"John Smith",
"Mary Jane Watson",
"Dr. Martin Luther King Jr.",
"Madonna", # Single name
"" # Empty string
]
def split_name_wrong(full_name):
"""Naive approach that breaks easily"""
parts = full_name.split()
first_name = parts[0] # This will crash for empty strings
last_name = parts[1] # This will crash for single names
return first_name, last_name
def split_name_right(full_name):
"""Robust approach that handles edge cases"""
if not full_name or full_name.isspace():
return "Unknown", "Person"
parts = full_name.strip().split()
if len(parts) == 0:
return "Unknown", "Person"
elif len(parts) == 1:
return parts[0], ""
else:
first_name = parts[0]
last_name = " ".join(parts[1:]) # Handle multiple middle names
return first_name, last_name
# Test both approaches
for name in full_names:
try:
first, last = split_name_wrong(name)
print(f"Wrong method - '{name}': {first}, {last}")
except IndexError as e:
print(f"Wrong method - '{name}': ERROR - {e}")
first, last = split_name_right(name)
print(f"Right method - '{name}': '{first}', '{last}'")
print()The robust approach handles:
- Empty strings
- Single names (like “Madonna”)
- Multiple middle names
- Extra whitespace
Output:
Wrong method - 'John Smith': John, Smith
Right method - 'John Smith': 'John', 'Smith'
Wrong method - 'Mary Jane Watson': Mary, Jane
Right method - 'Mary Jane Watson': 'Mary', 'Jane Watson'
Wrong method - 'Dr. Martin Luther King Jr.': Dr., Martin
Right method - 'Dr. Martin Luther King Jr.': 'Dr.', 'Martin Luther King Jr.'
Wrong method - 'Madonna': Madonna, ERROR - list index out of range
Right method - 'Madonna': 'Madonna', ''
Wrong method - '': ERROR - list index out of range
Right method - '': 'Unknown', 'Person'Real-World Applications
Example 1: Advanced Email Validator
Let’s build a more sophisticated email validator that checks multiple criteria:
def validate_email_detailed(email):
"""Comprehensive email validation with detailed feedback"""
errors = []
# Basic checks
if not email or email.isspace():
return False, ["Email cannot be empty"]
email = email.strip()
# Check for exactly one @ symbol
at_count = email.count("@")
if at_count == 0:
errors.append("Email must contain @ symbol")
elif at_count > 1:
errors.append("Email can only contain one @ symbol")
else:
# Split into username and domain
username, domain = email.split("@")
# Validate username
if not username:
errors.append("Username (before @) cannot be empty")
elif len(username) > 64:
errors.append("Username too long (max 64 characters)")
elif username.startswith(".") or username.endswith("."):
errors.append("Username cannot start or end with a period")
elif ".." in username:
errors.append("Username cannot contain consecutive periods")
# Validate domain
if not domain:
errors.append("Domain (after @) cannot be empty")
elif "." not in domain:
errors.append("Domain must contain at least one period")
else:
domain_parts = domain.split(".")
if len(domain_parts) < 2:
errors.append("Domain must have at least two parts")
elif any(not part for part in domain_parts):
errors.append("Domain parts cannot be empty")
elif not domain_parts[-1].isalpha():
errors.append("Top-level domain must contain only letters")
elif len(domain_parts[-1]) < 2:
errors.append("Top-level domain too short")
# Additional format checks
if email.startswith("@") or email.endswith("@"):
errors.append("Email cannot start or end with @")
invalid_chars = set(email) - set("abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789@.-_+")
if invalid_chars:
errors.append(f"Contains invalid characters: {', '.join(invalid_chars)}")
return len(errors) == 0, errors
# Test the validator
test_emails = [
"user@example.com", # Valid
"user@domain", # Missing TLD
"user.name@example.co.uk", # Valid with subdomain
"@example.com", # Missing username
"user@", # Missing domain
"user@@example.com", # Double @
"user@exam ple.com", # Space in domain
"user.@example.com", # Ends with period
"a@b.c", # Very short but valid
"" # Empty
]
print("EMAIL VALIDATION RESULTS")
print("=" * 50)
for email in test_emails:
is_valid, error_list = validate_email_detailed(email)
status = "✓ VALID" if is_valid else "✗ INVALID"
print(f"{email:<25} {status}")
if error_list:
for error in error_list:
print(f" → {error}")
print()Output:
EMAIL VALIDATION RESULTS
==================================================
user@example.com ✓ VALID
user@domain ✗ INVALID
→ Domain must contain at least one period
user.name@example.co.uk ✓ VALID
@example.com ✗ INVALID
→ Username (before @) cannot be empty
→ Email cannot start or end with @
user@ ✗ INVALID
→ Domain (after @) cannot be empty
→ Email cannot start or end with @
user@@example.com ✗ INVALID
→ Email can only contain one @ symbol
user@exam ple.com ✗ INVALID
→ Contains invalid characters:
user.@example.com ✗ INVALID
→ Username cannot start or end with a period
a@b.c ✓ VALID
✗ INVALID
→ Email cannot be emptyExample 2: Text Statistics Analyzer
Here’s a comprehensive text analyzer that provides detailed statistics:
def analyze_text_comprehensive(text):
"""Comprehensive text analysis with detailed statistics"""
if not text or text.isspace():
return {"error": "No text to analyze"}
# Basic counts
char_count = len(text)
char_no_spaces = len(text.replace(" ", ""))
words = text.split()
word_count = len(words)
# Sentence counting (rough approximation)
sentence_endings = text.count('.') + text.count('!') + text.count('?')
sentence_count = max(1, sentence_endings) # At least 1 sentence
# Character frequency analysis
char_freq = {}
letter_freq = {}
for char in text:
char_freq[char] = char_freq.get(char, 0) + 1
if char.isalpha():
letter = char.lower()
letter_freq[letter] = letter_freq.get(letter, 0) + 1
# Find most common characters
most_common_char = max(char_freq, key=char_freq.get) if char_freq else None
most_common_letter = max(letter_freq, key=letter_freq.get) if letter_freq else None
# Word length analysis
if words:
word_lengths = [len(word.strip('.,!?";()')) for word in words]
avg_word_length = sum(word_lengths) / len(word_lengths)
max_word_length = max(word_lengths)
min_word_length = min(word_lengths)
else:
avg_word_length = max_word_length = min_word_length = 0
# Readability approximation (words per sentence)
avg_words_per_sentence = word_count / sentence_count if sentence_count > 0 else 0
# Case analysis
uppercase_count = sum(1 for c in text if c.isupper())
lowercase_count = sum(1 for c in text if c.islower())
# Special character counts
digit_count = sum(1 for c in text if c.isdigit())
punctuation_count = sum(1 for c in text if not c.isalnum() and not c.isspace())
# Unique word analysis
unique_words = set(word.lower().strip('.,!?";()') for word in words)
vocabulary_richness = len(unique_words) / word_count if word_count > 0 else 0
return {
'basic_stats': {
'total_characters': char_count,
'characters_without_spaces': char_no_spaces,
'word_count': word_count,
'sentence_count': sentence_count,
'paragraph_count': text.count('\n\n') + 1
},
'character_analysis': {
'uppercase_letters': uppercase_count,
'lowercase_letters': lowercase_count,
'digits': digit_count,
'punctuation': punctuation_count,
'spaces': text.count(' '),
'most_common_character': most_common_char,
'most_common_letter': most_common_letter
},
'word_analysis': {
'average_word_length': round(avg_word_length, 2),
'longest_word_length': max_word_length,
'shortest_word_length': min_word_length,
'unique_words': len(unique_words),
'vocabulary_richness': round(vocabulary_richness, 3)
},
'readability': {
'average_words_per_sentence': round(avg_words_per_sentence, 1),
'complexity': 'Simple' if avg_words_per_sentence < 15 else 'Moderate' if avg_words_per_sentence < 25 else 'Complex'
}
}
# Test with sample text
sample_text = """Python is a powerful programming language that's easy to learn and fun to use.
It was created by Guido van Rossum in 1991. Today, Python is used everywhere:
web development, data science, artificial intelligence, and more!
The beauty of Python lies in its simplicity and readability.
As the Python philosophy states: "Beautiful is better than ugly. Simple is better than complex."""
results = analyze_text_comprehensive(sample_text)
print("COMPREHENSIVE TEXT ANALYSIS")
print("=" * 50)
for category, stats in results.items():
print(f"\n{category.replace('_', ' ').title()}:")
for key, value in stats.items():
formatted_key = key.replace('_', ' ').title()
print(f" {formatted_key}: {value}")Output:
COMPREHENSIVE TEXT ANALYSIS
==================================================
Basic Stats:
Total Characters: 445
Characters Without Spaces: 370
Word Count: 75
Sentence Count: 6
Paragraph Count: 2
Character Analysis:
Uppercase Letters: 10
Lowercase Letters: 313
Digits: 4
Punctuation: 13
Spaces: 75
Most Common Character:
Most Common Letter: e
Word Analysis:
Average Word Length: 4.93
Longest Word Length: 13
Shortest Word Length: 1
Unique Words: 59
Vocabulary Richness: 0.787
Readability:
Average Words Per Sentence: 12.5
Complexity: SimpleExample 3: Advanced Password Generator and Validator
Let’s create a system that both generates secure passwords and validates their strength:
import random
import string
def generate_password(length=12, include_upper=True, include_lower=True,
include_digits=True, include_symbols=True,
exclude_ambiguous=True):
"""Generate a secure password with specified criteria"""
# Build character set based on requirements
chars = ""
if include_lower:
chars += string.ascii_lowercase
if include_upper:
chars += string.ascii_uppercase
if include_digits:
chars += string.digits
if include_symbols:
chars += "!@#$%^&*()_+-=[]{}|;:,.<>?"
# Remove ambiguous characters if requested
if exclude_ambiguous:
ambiguous = "0O1lI|"
chars = ''.join(c for c in chars if c not in ambiguous)
if not chars:
return None, "No character types selected"
# Ensure at least one character from each required type
password_chars = []
if include_lower:
available_lower = [c for c in string.ascii_lowercase if c in chars]
password_chars.append(random.choice(available_lower))
if include_upper:
available_upper = [c for c in string.ascii_uppercase if c in chars]
password_chars.append(random.choice(available_upper))
if include_digits:
available_digits = [c for c in string.digits if c in chars]
password_chars.append(random.choice(available_digits))
if include_symbols:
available_symbols = [c for c in "!@#$%^&*()_+-=[]{}|;:,.<>?" if c in chars]
if available_symbols:
password_chars.append(random.choice(available_symbols))
# Fill remaining length with random characters
remaining_length = length - len(password_chars)
for _ in range(remaining_length):
password_chars.append(random.choice(chars))
# Shuffle to avoid predictable patterns
random.shuffle(password_chars)
return ''.join(password_chars), "Password generated successfully"
def analyze_password_strength(password):
"""Analyze password strength with detailed feedback"""
if not password:
return 0, ["Password cannot be empty"]
score = 0
feedback = []
strengths = []
# Length analysis
length = len(password)
if length >= 12:
score += 25
strengths.append(f"Good length ({length} characters)")
elif length >= 8:
score += 15
feedback.append("Consider using at least 12 characters for better security")
else:
feedback.append("Password too short - use at least 8 characters")
# Character type analysis
has_lower = any(c.islower() for c in password)
has_upper = any(c.isupper() for c in password)
has_digit = any(c.isdigit() for c in password)
has_symbol = any(c in "!@#$%^&*()_+-=[]{}|;:,.<>?~`" for c in password)
char_types = sum([has_lower, has_upper, has_digit, has_symbol])
if char_types >= 4:
score += 25
strengths.append("Uses all character types")
elif char_types >= 3:
score += 15
strengths.append("Uses multiple character types")
else:
missing_types = []
if not has_lower: missing_types.append("lowercase letters")
if not has_upper: missing_types.append("uppercase letters")
if not has_digit: missing_types.append("numbers")
if not has_symbol: missing_types.append("symbols")
feedback.append(f"Add {', '.join(missing_types)}")
# Pattern analysis
has_sequence = False
has_repetition = False
# Check for sequential characters
for i in range(len(password) - 2):
if (ord(password[i+1]) == ord(password[i]) + 1 and
ord(password[i+2]) == ord(password[i]) + 2):
has_sequence = True
break
# Check for repeated characters
for i in range(len(password) - 2):
if password[i] == password[i+1] == password[i+2]:
has_repetition = True
break
if not has_sequence and not has_repetition:
score += 20
strengths.append("No obvious patterns detected")
else:
if has_sequence:
feedback.append("Avoid sequential characters (abc, 123)")
if has_repetition:
feedback.append("Avoid repeated characters (aaa, 111)")
# Uniqueness analysis
unique_chars = len(set(password))
uniqueness_ratio = unique_chars / length
if uniqueness_ratio > 0.8:
score += 15
strengths.append("High character diversity")
elif uniqueness_ratio > 0.6:
score += 10
else:
feedback.append("Use more diverse characters")
# Common password check (simplified)
common_patterns = ['password', '123456', 'qwerty', 'admin', 'letmein']
if any(pattern in password.lower() for pattern in common_patterns):
score -= 20
feedback.append("Avoid common password patterns")
else:
score += 15
strengths.append("No common password patterns detected")
# Determine strength level
if score >= 85:
strength = "Very Strong"
elif score >= 70:
strength = "Strong"
elif score >= 50:
strength = "Moderate"
elif score >= 30:
strength = "Weak"
else:
strength = "Very Weak"
return score, strength, strengths, feedback
# Test the password system
print("PASSWORD GENERATOR AND ANALYZER")
print("=" * 50)
# Generate different types of passwords
password_configs = [
{"length": 8, "include_symbols": False},
{"length": 12},
{"length": 16, "exclude_ambiguous": False},
]
for i, config in enumerate(password_configs, 1):
password, message = generate_password(**config)
print(f"\nPassword {i}: {password}")
if password:
score, strength, strengths, feedback = analyze_password_strength(password)
print(f"Strength: {strength} (Score: {score}/100)")
if strengths:
print("Strengths:")
for strength_point in strengths:
print(f" ✓ {strength_point}")
if feedback:
print("Suggestions:")
for suggestion in feedback:
print(f" → {suggestion}")
# Test with some common weak passwords
print(f"\n{'='*50}")
print("ANALYSIS OF WEAK PASSWORDS")
print("=" * 50)
weak_passwords = ["password", "123456789", "Password1", "P@ssw0rd123!"]
for pwd in weak_passwords:
score, strength, strengths, feedback = analyze_password_strength(pwd)
print(f"\nPassword: '{pwd}'")
print(f"Strength: {strength} (Score: {score}/100)")
if feedback:
print("Issues:")
for issue in feedback:
print(f" ✗ {issue}")Output will vary due to random generation, but might look like:
PASSWORD GENERATOR AND ANALYZER
==================================================
Password 1: Km7nFp2w
Strength: Moderate (Score: 55/100)
Strengths:
✓ Uses multiple character types
✓ No obvious patterns detected
✓ High character diversity
✓ No common password patterns detected
Suggestions:
→ Consider using at least 12 characters for better security
→ Add symbols
Password 2: K8$mNx9#pQ2v
Strength: Very Strong (Score: 90/100)
Strengths:
✓ Good length (12 characters)
✓ Uses all character types
✓ No obvious patterns detected
✓ High character diversity
✓ No common password patterns detected
==================================================
ANALYSIS OF WEAK PASSWORDS
==================================================
Password: 'password'
Strength: Very Weak (Score: 15/100)
Issues:
✗ Password too short - use at least 8 characters
✗ Add uppercase letters, numbers, symbols
✗ Avoid common password patterns
Password: '123456789'
Strength: Weak (Score: 30/100)
Issues:
✗ Add uppercase letters, lowercase letters, symbols
✗ Avoid sequential characters (abc, 123)
✗ Use more diverse characters
Password: 'Password1'
Strength: Weak (Score: 45/100)
Issues:
✗ Add symbols
✗ Avoid common password patterns
Password: 'P@ssw0rd123!'
Strength: Moderate (Score: 65/100)
Strengths:
✓ Uses all character types
✓ No obvious patterns detected
✓ High character diversity
Suggestions:
✗ Consider using at least 12 characters for better security
✗ Avoid common password patternsConclusion
Congratulations! You’ve just completed a comprehensive journey through Python string methods and operations. Let me summarize what we’ve covered:
What You’ve Learned
- Basic String Concepts: Understanding what strings are and how to create them
- Case Operations: Converting between uppercase, lowercase, and title case
- Whitespace Handling: Cleaning up extra spaces and formatting text
- Search and Check Methods: Finding text and asking questions about string content
- Splitting and Joining: Breaking text apart and putting it back together
- Replacement Operations: Changing parts of your text
- Alignment and Padding: Making text look professional
- Advanced Formatting: Using f-strings and format methods
- Real-World Applications: Email validation, text cleaning, log parsing, and more
- Performance Considerations: Writing efficient string code
- Security Aspects: Avoiding common pitfalls
Key Takeaways
- Strings are immutable: Remember to assign the result back to a variable
- Choose the right tool: Different methods solve different problems
- Handle edge cases: Always consider None, empty strings, and unexpected input
- Performance matters: Use join() for multiple concatenations, f-strings for formatting
- Security is important: Always sanitize user input
Practice Suggestions
- Start Small: Try each method with simple examples
- Build Projects: Create a text analyzer, password generator, or log parser
- Read Code: Look at open-source Python projects to see how experts use strings
- Experiment: Don’t be afraid to try combining different methods
- Debug: Use print() statements to see what your string operations are producing
Your Next Steps
Now that you understand Python strings, you can:
- Build text processing applications
- Clean and analyze data from files
- Create user-friendly interfaces
- Validate user input effectively
- Parse configuration files and logs
Remember, becoming proficient with strings is like learning to use a Swiss Army knife – the more you practice with each tool, the more naturally you’ll know which one to reach for in any situation.
Keep practicing, stay curious, and most importantly, have fun coding! Python strings are incredibly powerful, and you now have all the tools you need to use them effectively.
Final Challenge
Try building a complete text processing program that:
- Reads text from user input
- Cleans and formats it
- Analyzes its content (word count, readability, etc.)
- Generates a summary report
This will help you practice everything you’ve learned and give you confidence to tackle real-world string processing tasks.
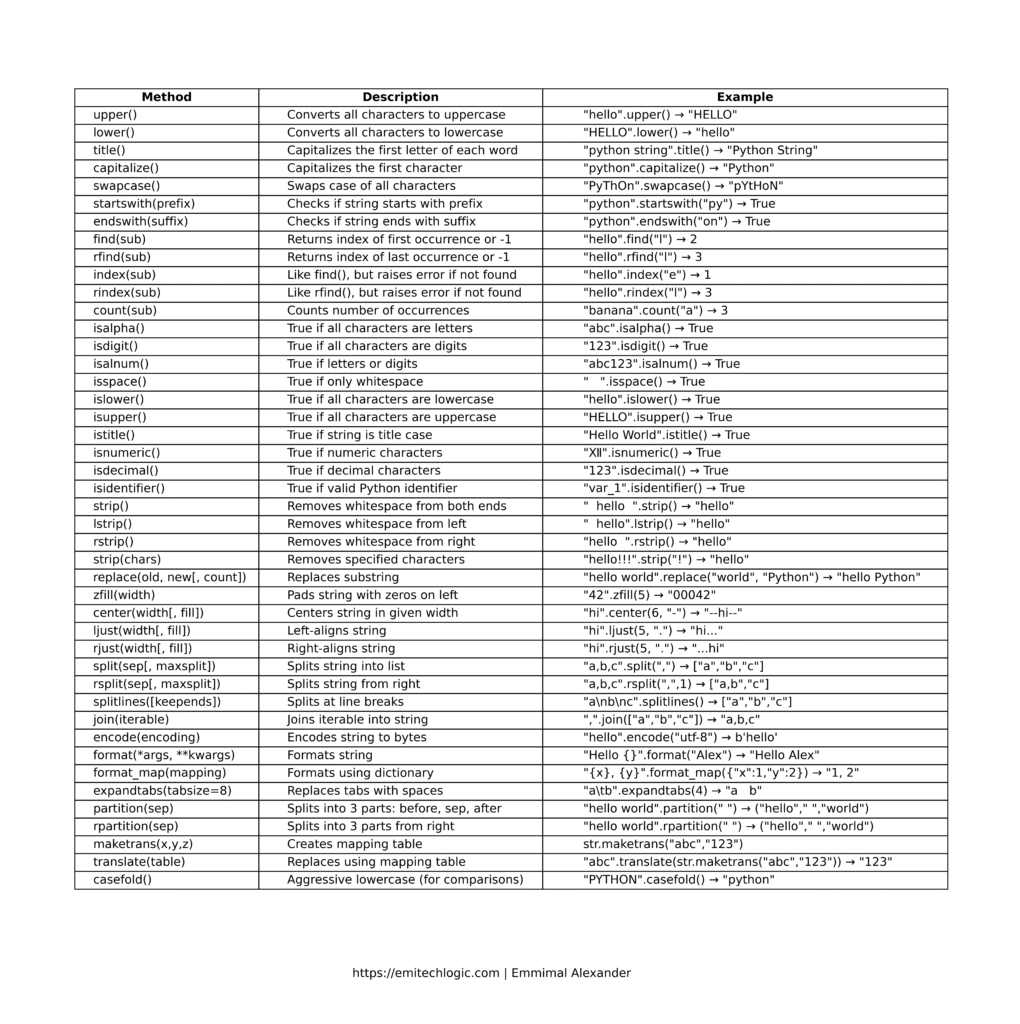
Python String Methods Cheatsheet
Python String Methods Quiz
Frequently Asked Questions (FAQ)
1. What is a string in Python?
A string in Python is a sequence of characters — letters, numbers, symbols, or spaces — enclosed in single (
') or double (") quotes. For example:"Hello World"or'Python123'.2. Why are string methods important?
String methods make it easier to handle text. Instead of writing long chunks of code, you can simply use built-in methods like
.upper(),.split(), or.replace()to process strings efficiently.3. Do string methods change the original string?
No. Strings in Python are immutable, which means their content cannot be changed. String methods always return a new string, leaving the original one untouched.
4. How can I check if a string contains only numbers?
You can use the
.isdigit()method. For example:"123".isdigit() # Returns True
"12a".isdigit() # Returns False5. What’s the difference between
find()andindex()?Both locate a substring in a string. The key difference is:
find()returns-1if the substring is not found.index()raises an error if the substring is not found.6. How do I remove spaces from the start and end of a string?
You can use
.strip(). For example:" hello ".strip() # Returns "hello"7. Can I join a list into a single string?
Yes. You can use the
.join()method. Example:",".join(["a", "b", "c"]) # Returns "a,b,c"8. What is the best way to format strings in Python?
You can use the
format()method or f-strings (Python 3.6+).name = "Alex"
f"Hello, {name}" # Returns "Hello, Alex"9. How do I check if a string starts or ends with a certain word?
Use
.startswith()or.endswith(). For example:"python".startswith("py") # True
"python".endswith("on") # True10. Can I convert a string into a list of characters?
Yes, simply use the
list()function. Example:list("hello") # ['h', 'e', 'l', 'l', 'o']
External Resources for Python Strings
- Python String Methods (Official Docs)
https://docs.python.org/3/library/stdtypes.html - Real Python – Strings and Character Data in Python
https://realpython.com/python-strings/ - W3Schools – Python String Methods
https://www.w3schools.com/python/python_ref_string.asp - GeeksforGeeks – Python String Methods
https://www.geeksforgeeks.org/python-string-methods/ - Programiz – Python Strings
https://www.programiz.com/python-programming/string - TutorialsPoint – Python Strings
https://www.tutorialspoint.com/python/python_strings.htm






Leave a Reply