

Top 10 Python Interview Questions That Look Easy but Catch You Off Guard
Introduction
If you’ve been preparing for a Python interview, you’ve probably gone through the usual questions—data types, loops, functions, OOPs… the basics. But what about those sneaky questions that look simple at first glance but end up making you second-guess yourself?
That’s exactly what I’ve covered in my latest YouTube video: “Top 10 Python Interview Questions That Look Easy but Catch You Off Guard.”
These aren’t just tricky—they’re deceptively tricky. Each one is designed as a multiple-choice question (MCQ), so you can test your knowledge as you go.
👉 Before you scroll further, I recommend watching the video and trying the quiz for yourself.
It’s a great way to challenge your Python instincts before you dive into the explanations here.
📺 Watch the quiz on YouTube here
Subscribe to my channel – Uncovered AI with Emi for more quizzes, tips, and hands-on coding content!
Once you’re done, come back here—I’ve broken down each question with detailed explanations, Python code examples, and the logic behind the correct answers.
Let’s see how many you got right. Or… how many caught you off guard.
Now, Let’s Explore These Tricky Python interview questions (with Explanations)
If you’ve already taken the quiz in the video, great! Whether you aced it or missed a few, this section is for breaking down each question and helping you understand why a certain answer is correct.
Let’s get started 👇
Python Function Output: Identify the Top Active Users
Python function, most common elements, list operations, Counter, user activity logs
1: What will this Python function return?
from collections import Counter
def top_active_users(logs):
users = [log.split()[0] for log in logs]
return [user for user, _ in Counter(users).most_common(2)]
logs = ["user1 login", "user2 login", "user1 logout"]
print(top_active_users(logs))
Options:
A. [‘user1’, ‘user2’]
B. [‘user2’, ‘user1’]
C. [‘user1’]
D. [‘user1’, ‘user1’]
Correct Answer: A. [‘user1’, ‘user2’]
The question is: What will this code print?
You have four options:
A. [‘user1’, ‘user2’]
B. [‘user2’, ‘user1’]
C. [‘user1’]
D. [‘user1’, ‘user1’]
Correct answer is A. [‘user1’, ‘user2’]
Let’s go through it one small step at a time.
First, look at the logs list:
logs = ["user1 login", "user2 login", "user1 logout"]
This list shows three user actions:
- user1 logged in
- user2 logged in
- user1 logged out
So we can already see that user1 shows up twice, and user2 shows up once.
Now go inside the function.
Line 1:
users = [log.split()[0] for log in logs]
Let’s understand this:
- For each item in the
logslist, we split the string. - For example,
"user1 login"becomes["user1", "login"] - Then we take the first part (that’s
[0]), which is just the username.
So now we have:
users = ['user1', 'user2', 'user1']
Cool? All we did is extract the usernames from the logs.
Line 2:
Counter(users).most_common(2)
This counts how many times each username appears in the list.
So from:
['user1', 'user2', 'user1']
The counts are:
- user1: 2 times
- user2: 1 time
most_common(2) means: “Give me the top 2 users with the highest counts.”
So now we get this:
[('user1', 2), ('user2', 1)]
This is just a list of tuples (a pair of values). The first value is the user, and the second is how many times they appeared.
Line 3:
[user for user, _ in ...]
This part means:
“From each tuple like (‘user1’, 2), take just the username.”
So we get:
['user1', 'user2']
Final Answer
The function prints:
['user1', 'user2']
So the correct answer is Option A.
Why is this question tricky?
Because it looks simple, but if you don’t understand how split(), list comprehensions, and Counter work together, it’s easy to get confused.
Regex in Python: What Does This Pattern Validate?
Python regex, regular expression, email validation, pattern matching
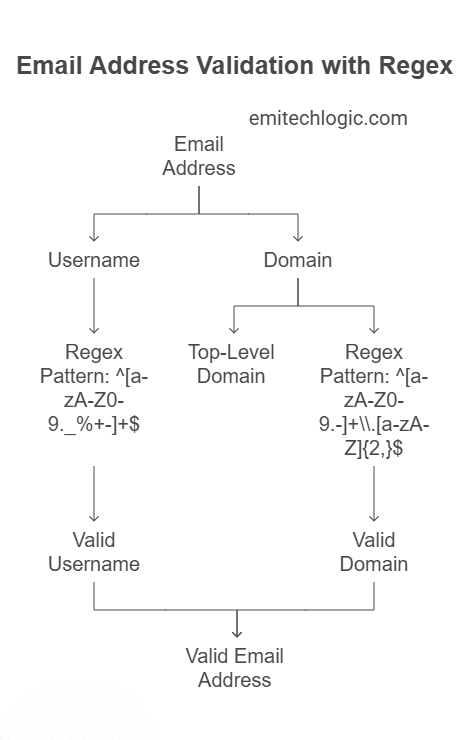
2: What does the following regex check for?
re.match(r'^[\w\.-]+@[\w\.-]+\.\w+$', email)
Options:
A. Valid phone number
B. Valid email address
C. URL format
D. IP address
Correct Answer: B. Valid email address
Let’s break it down.
This question is about regular expressions (also called regex). Regex is used to match patterns in text — like checking if something looks like an email, phone number, etc.
In this case, we’re matching this pattern:
r'^[\w\.-]+@[\w\.-]+\.\w+$'
Let’s break this into parts:
1. ^
This means: start of the string.
So we want to match from the beginning.
2. [\w\.-]+
This is the username part of an email (the part before the @).
\wmeans any letter, number, or underscore.is a literal dot-is a literal dash[]means “any of these characters”+means “one or more”
So [\w\.-]+ means:
One or more letters, numbers, dots, or dashes.
Example match: john.doe, alex_123, my-email
3. @
Just matches the @ symbol in the email.
4. [\w\.-]+
Same thing again — now for the domain name part (like gmail or emitechlogic).
5. \.
This matches a dot — like the one before .com, .org, etc.
Notice the backslash: . on its own means “any character”, but \. means “a real dot”.
6. \w+
This means: one or more letters or numbers (this is for .com, .net, etc.).
7. $
This means: end of the string.
So nothing extra should come after the email.
Final Pattern Summary:
It checks for something like:
username@domain.com
With support for:
- dots and dashes in both parts
- only letters, numbers, dots, or dashes
- exactly one
@in the middle - a proper ending like
.com,.org,.co.in, etc.
So, what does this regex check?
It checks if a string looks like a valid email address.
That’s why the correct answer is B.
Let’s try this regex in Python and test it with a few examples
Step-by-step Code Example
import re
def is_valid_email(email):
pattern = r'^[\w\.-]+@[\w\.-]+\.\w+$'
return re.match(pattern, email) is not None
# Test cases
emails = [
"john.doe@example.com", # valid
"alex_123@my-site.co", # valid
"noatsymbol.com", # invalid
"invalid@.com", # invalid
"missing@domain", # invalid
"user@domain.org", # valid
"user@domain123.net", # valid
"user@domain.c", # valid (technically allowed)
]
for email in emails:
result = is_valid_email(email)
print(f"{email:30} --> {'Valid' if result else 'Invalid'}")
What this does:
- We define a function called
is_valid_emailthat takes an email and checks if it matches the pattern. - Then we test a list of sample email addresses — some correct, some clearly wrong.
- For each email, it prints whether it’s valid or invalid.
Output will look like:
john.doe@example.com --> Valid
alex_123@my-site.co --> Valid
noatsymbol.com --> Invalid
invalid@.com --> Invalid
missing@domain --> Invalid
user@domain.org --> Valid
user@domain123.net --> Valid
user@domain.c --> Valid
Note
This regex is simple and covers basic email formats. But in real-world apps, email validation often uses stricter patterns or libraries like email-validator.
Hash Function in Python: Purpose of MD5 and URL Encoding
Python hashlib, MD5 hash, URL hashing, string encoding, short URL

3: What is the purpose of this code?
hashlib.md5(url.encode()).hexdigest()[:6]
Options:
A. Encrypt a URL
B. Generate a long URL
C. Shorten a URL using hash
D. Check if URL is valid
✅ Correct Answer: C. Shorten a URL using hash
Here’s the code again:
hashlib.md5(url.encode()).hexdigest()[:6]
This line is used to create a short code for a long URL.
Think of it like this:
You have a long website address like:
https://emitechlogic.com/blog/type-conversion-in-python/That’s long. But what if you want to create a short version like:
https://short.ly/abc123
That’s what the code is doing — it turns your long URL into a short string like abc123. Let’s see how it works step-by-step:
Step 1: url.encode()
This turns the URL (which is a string) into a format that the computer can process — bytes.
Why? Because the next step needs bytes, not plain text.
Example:
url = "https://emitechlogic.com"
url.encode() # turns it into bytes
Step 2: hashlib.md5(...)
This creates a hash of the URL.
Hashing = turning your URL into a fixed, scrambled string of numbers and letters.
Example:
hashlib.md5(url.encode())
This gives a hash object.
Step 3: .hexdigest()
Now we convert that hash into a readable string.
hashlib.md5(url.encode()).hexdigest()
This gives a string like:
6e36cbcf1a03f601e2ed7f66d15fcaaa
Step 4: [:6]
We don’t want the whole long string — we just want the first 6 characters to make it short and sweet:
'6e36cbcf1a03f601e2ed7f66d15fcaaa'[:6]
This gives:
'6e36cb'
So finally:
hashlib.md5(url.encode()).hexdigest()[:6]
Becomes:
'6e36cb'
You can now use this short string as a short URL ID.
✅ Final Answer: It creates a short code for a long URL.
That’s why the correct answer is:
C. Shorten a URL using hash
Creating a Short URL in Python
import hashlib
def shorten_url(long_url):
# Step 1: Convert the URL to bytes
url_bytes = long_url.encode()
# Step 2: Create an MD5 hash of the URL
url_hash = hashlib.md5(url_bytes)
# Step 3: Convert the hash to a hex string
hex_string = url_hash.hexdigest()
# Step 4: Take the first 6 characters to make it short
short_code = hex_string[:6]
# You can use this short code as a short URL path
short_url = f"https://short.ly/{short_code}"
return short_url
# Test it
original_url = "https://emitechlogic.com/blog/awesome-python-interview-questions"
short_url = shorten_url(original_url)
print("Original URL:", original_url)
print("Short URL :", short_url)
Output:
Original URL: https://emitechlogic.com/blog/awesome-python-interview-questions
Short URL : https://short.ly/f3d192
What just happened?
- We took a long URL.
- We turned it into a unique short string (
f3d192) using a hash. - Then we attached that short string to a domain like
short.ly. - That’s how URL shorteners work in the background.
This short code can now be saved in a database and mapped to the original URL.
Must Read
- How to Diagnose and Fix Class Imbalance in Machine Learning (Complete Guide)
- How to Diagnose Overfitting in Machine Learning — 9 Proven Tools
- PyTorch Debugging Checklist: A Systematic Framework to Fix Models That Won’t Learn
- Why sorted() Is Safer Than list.sort() in Production Python Systems
- Monotonic Sequence in Python: 7 Practical Methods With Edge Cases, Interview Tips, and Performance Analysis
Python Code Output: Formatting a Phone Number String
Python string formatting, phone number, digits extraction, clean formatting

4: What is the output of this code?
def format_phone_number(number):
digits = ''.join(filter(str.isdigit, number))
return f"({digits[:3]}) {digits[3:6]}-{digits[6:]}"
print(format_phone_number("987-654-3210"))
Options:
A. 9876543210
B. (987) 654-3210
C. 987-654-3210
D. (98) 765-4321
✅ Correct Answer: B
Let me teach you how this works step-by-step:
1. filter(str.isdigit, number)
This removes everything except the digits.
The original input is:
"987-654-3210"
filter(str.isdigit, number) keeps only the digits →
['9', '8', '7', '6', '5', '4', '3', '2', '1', '0']
We then join them together:
digits = ''.join(...) → '9876543210'
So at this point:
digits = '9876543210'
2. f"({digits[:3]}) {digits[3:6]}-{digits[6:]}"
This formats the digits in the (XXX) YYY-ZZZZ style.
Let’s break it:
digits[:3]→ first 3 digits →'987'digits[3:6]→ next 3 digits →'654'digits[6:]→ remaining digits →'3210'
So the final string becomes:
(987) 654-3210
Final Output:
(987) 654-3210
Which is why the correct answer is B.
Detecting Duplicate File Names in Python
Python set, duplicate detection, list comparison, file handling
5. What does this code detect?
def has_duplicates(files):
return len(files) != len(set(files))
A. Files without extensions
B. Files with uppercase names
C. Duplicate file names
D. Hidden files
✅ Correct Answer: C
Here’s the code we’re talking about:
def has_duplicates(files):
return len(files) != len(set(files))
Let’s say you call the function like this:
has_duplicates(["file1.txt", "file2.txt", "file1.txt"])
What does this mean?
You’re giving a list of file names. The goal is to check if any file name appears more than once.
Now let me break it down for you:
Step 1: len(files)
This counts how many file names are in the list.
Example:
files = ["file1.txt", "file2.txt", "file1.txt"]
len(files) = 3
So there are 3 items in the list.
Step 2: set(files)
A set is a special thing in Python that removes duplicates.
So:
set(files) = {"file1.txt", "file2.txt"}
Notice that "file1.txt" only appears once in the set — even though it appeared twice in the original list.
Now:
len(set(files)) = 2
Step 3: Compare both lengths
len(files)is 3len(set(files))is 2
Since they are not equal, the function returns True.
That means: Yes, there are duplicates.
Final Answer:
The function is checking if there are duplicate file names in the list.
If there are duplicates, it returns True.
If there are no duplicates, it returns False.
One more example — no duplicates:
has_duplicates(["a.txt", "b.txt", "c.txt"])
All are different → the function returns False
So what does the function detect?
✅ C. Duplicate file names
Python Code Example
def has_duplicates(files):
return len(files) != len(set(files))
# Example 1: With duplicates
file_list_1 = ["file1.txt", "file2.txt", "file1.txt"]
result_1 = has_duplicates(file_list_1)
print("List 1 has duplicates:", result_1) # This will print: True
# Example 2: Without duplicates
file_list_2 = ["file1.txt", "file2.txt", "file3.txt"]
result_2 = has_duplicates(file_list_2)
print("List 2 has duplicates:", result_2) # This will print: False
Output:
List 1 has duplicates: True
List 2 has duplicates: False
What you’re seeing:
- List 1 has
"file1.txt"two times → returns True - List 2 has all unique files → returns False
This shows exactly what the function is doing:
It checks if any file name appears more than once.
Password Strength Checker in Python: What’s Missing?
password strength, security flaws, Python validation logic, password length

6. What is the key flaw in this password checker?
Here’s the code:
def is_strong_password(password):
return len(password) > 8
Correct Answer: ✅ D. All of the above
What does this function do?
It only checks one thing:
- Is the password longer than 8 characters?
That’s it. If the password is even 9 lowercase letters, it will say it’s “strong”.
Example:
is_strong_password("hellothere") # returns True
What’s missing?
It doesn’t check for uppercase letters, numbers, or special characters like !, @, or #.
Even lowercase letters aren’t required — so something like "!!!!!!!!!!" could still be rated as strong.
So let’s go through the options:
A. It doesn’t check special characters → Yes, that’s a flaw
B. It ignores uppercase letters → Also true
C. It only checks length → Exactly
D. All of the above → This is the full truth
Let’s test it in Python
def is_strong_password(password):
return len(password) > 8
# Weak password but long
print(is_strong_password("aaaaaaaaa")) # True
# Strong password but short
print(is_strong_password("A1@b")) # False
Final takeaway:
This function is too simple. It only checks the length, not the real strength of a password.
That’s why D (All of the above) is the correct answer.
Python Word Frequency Counter Output
word count, Python Counter, frequency analysis, text processing
7. What’s the output of this word frequency counter?
from collections import Counter
text = "Python is fun and Python is powerful"
words = text.lower().split()
print(Counter(words)['python'])
A. 1
B. 2
C. 3
D. 0
✅ Correct Answer: B
What does this code do?
from collections import Counter
text = "Python is fun and Python is powerful"
words = text.lower().split()
print(Counter(words)['python'])
We’re trying to find how many times the word "python" appears in that sentence.
Step-by-step Explanation
1. text = "Python is fun and Python is powerful"
This is your sentence.
2. text.lower()
This converts every letter to lowercase, so:
"Python is fun and Python is powerful"
↓
"python is fun and python is powerful"
This helps avoid case mismatch issues.
3. .split()
Now we split the sentence into words:
['python', 'is', 'fun', 'and', 'python', 'is', 'powerful']
So "python" appears twice in this list.
4. Counter(words)
This counts how many times each word appears.
You get something like:
Counter({
'python': 2,
'is': 2,
'fun': 1,
'and': 1,
'powerful': 1
})
5. Counter(words)['python']
This pulls the count of the word "python" → which is 2
Final Answer: B. 2
Try it in Python yourself:
from collections import Counter
text = "Python is fun and Python is powerful"
words = text.lower().split()
count = Counter(words)['python']
print("Python appears:", count)
Output:
Python appears: 2
Python Code Logic: Counting Positive Reviews in Text
sentiment analysis, review processing, positive word detection, Python loop
8. What does this code do?
sum(any(word in review.lower() for word in {"good", "great"}) for review in reviews)
Correct Answer: ✅ C. Count positive reviews
Let’s unpack this like you and I are debugging it together.
Step-by-step Explanation
Say we have a list of reviews:
reviews = [
"This product is really good!",
"Not what I expected",
"Great value for the price",
"Okay-ish",
"Absolutely amazing"
]
Let’s focus on this part first:
any(word in review.lower() for word in {"good", "great"})
What it means:
- For each review (like
"This product is really good!"), we check:- Is “good” in it?
- Or is “great” in it?
We do this after converting the review to lowercase to handle case-insensitive matching.
If either word is found, any(...) returns True.
If neither is found, it returns False.
Now wrap that in a loop:
for review in reviews
It goes through each review in the list and checks for "good" or "great".
Now wrap everything in sum(...)
This is the cool part.
Each time any(...) returns True, it’s treated as 1.
Each time it returns False, it’s treated as 0.
So you’re basically counting how many reviews contain either “good” or “great”.
Try it in Python:
reviews = [
"This product is really good!",
"Not what I expected",
"Great value for the price",
"Okay-ish",
"Absolutely amazing"
]
positive_count = sum(any(word in review.lower() for word in {"good", "great"}) for review in reviews)
print("Number of positive reviews:", positive_count)
Output:
Number of positive reviews: 2
Why? Because:
"good"is found in review 1"great"is found in review 3
Final Answer: C. Count positive reviews
Currency Conversion in Python: What Is Printed?
currency conversion, Python function, default arguments, round function
9. What is printed?
def convert_usd_to_eur(usd, rate=0.91):
return round(usd * rate, 2)
print(convert_usd_to_eur(100))
✅ Correct Answer: A. 91.0
Step-by-step Explanation
1. This is a function that converts USD to EUR:
def convert_usd_to_eur(usd, rate=0.91):
- It takes two parameters:
usd: the amount in US dollarsrate: the conversion rate from USD to EUR (default is 0.91)
So, if you don’t pass a rate, it uses 0.91 automatically.
The calculation inside:
return round(usd * rate, 2)
That means:
- Multiply
usdbyrate - Round the result to 2 decimal places
The function call:
convert_usd_to_eur(100)
You’re passing usd = 100, and not providing a rate, so the default 0.91 is used.
Now the math:
100 * 0.91 = 91.0
Then it’s rounded to 2 decimal places (though it’s already clean), so the output is:
print(91.0) # ✅
You can try this in Python:
def convert_usd_to_eur(usd, rate=0.91):
return round(usd * rate, 2)
print(convert_usd_to_eur(100)) # Output: 91.0
Final Answer: A. 91.0
CSV Data Cleaning in Python: What Will This List Comprehension Output?
CSV cleaning, Python list comprehension, whitespace handling, data sanitization
![CSV table showing a blank field replaced with "N/A"; before: ["John", "", "25"], after: ["John", "N/A", "25"], with color highlighting the updated cell.](https://emitechlogic.com/wp-content/uploads/2025/04/Cleaning-Empty-CSV-Fields.png)
10. What is the output of this code?
[cell if cell.strip() else "N/A" for cell in ["John", "", "25"]]
✅ Correct Answer: B. ["John", "N/A", "25"]
Step-by-step Explanation
This is called a list comprehension — it loops through a list and applies some logic to each item.
Let’s break it down:
1. Input list:
["John", "", "25"]
So we have three values:
"John"— a normal string""— an empty string"25"— a string number
2. What does cell.strip() do?
The strip() function removes whitespace from the beginning and end of a string.
So:
"John".strip()→"John"(still has content)"".strip()→""(still empty)"25".strip()→"25"(still has content)
Then this line:
cell if cell.strip() else "N/A"
says:
- If the stripped value is non-empty, keep it as is.
- If it’s empty, replace it with
"N/A"
3. Let’s apply it to each item:
"John"→"John".strip()→"John"→ keep"John"""→"".strip()→""→ replace with"N/A""25"→"25".strip()→"25"→ keep"25"
Final Output:
["John", "N/A", "25"]
That’s why the answer is:
✅ B. ["John", "N/A", "25"]
Try this in Python:
cleaned = [cell if cell.strip() else "N/A" for cell in ["John", "", "25"]]
print(cleaned)
Output:
['John', 'N/A', '25']
Final Thoughts
These 10 Python interview questions might look easy at first glance, but as you’ve seen, they have subtle twists that can trip up even experienced developers. Whether it’s how Counter ranks elements, how list comprehensions clean data, or how default arguments sneak in, each question is a chance to sharpen your understanding of Python’s behavior in real-world coding.
If you haven’t already tried the quiz in the YouTube video, go ahead and give it a shot now — then come back here to see how many you nailed!
Python interviews often test your attention to detail, not just your syntax knowledge. So keep practicing, stay curious, and next time you’re in the hot seat, you’ll be ready for anything.
💡 Found this helpful?
Do me a favor — share this post with your friends, colleagues, or on your social media. You never know who might need a quick Python refresher before their next interview.
✍️ For more Python tricks, breakdowns, and real-world coding insights, head over to emitechlogic.com. I post new tutorials regularly!
Thanks for reading
📲 Follow for Python tips & tricks
📸 Instagram: https://www.instagram.com/emi_techlogic/
💼 LinkedIn: https://www.linkedin.com/in/emmimal-alexander/
#PythonQuiz #CodingInterview #PythonInterviewQuestions #MCQChallenge #PythonMCQ #EmitechLogic #UncoveredAI #PythonTips #AIwithEmi #PythonCoding #TechWithEmi




 Function in Python")

Leave a Reply