

Federated Learning: Secure AI for the Future
Introduction to Federated Learning: A New Paradigm in AI
Federated learning is a game-changer in the world of artificial intelligence. It bringing a fresh approach to how we handle data privacy and security. Unlike traditional methods that gather and process data in a central location, federated learning keeps data on your device. This approach allows for powerful AI training while ensuring your personal information remains safe and secure. In this blog post, we’ll explore the benefits of federated learning, how it works, and why it’s poised to revolutionize the AI landscape. Ready to Explore Let’s get started!
What is Federated Learning?
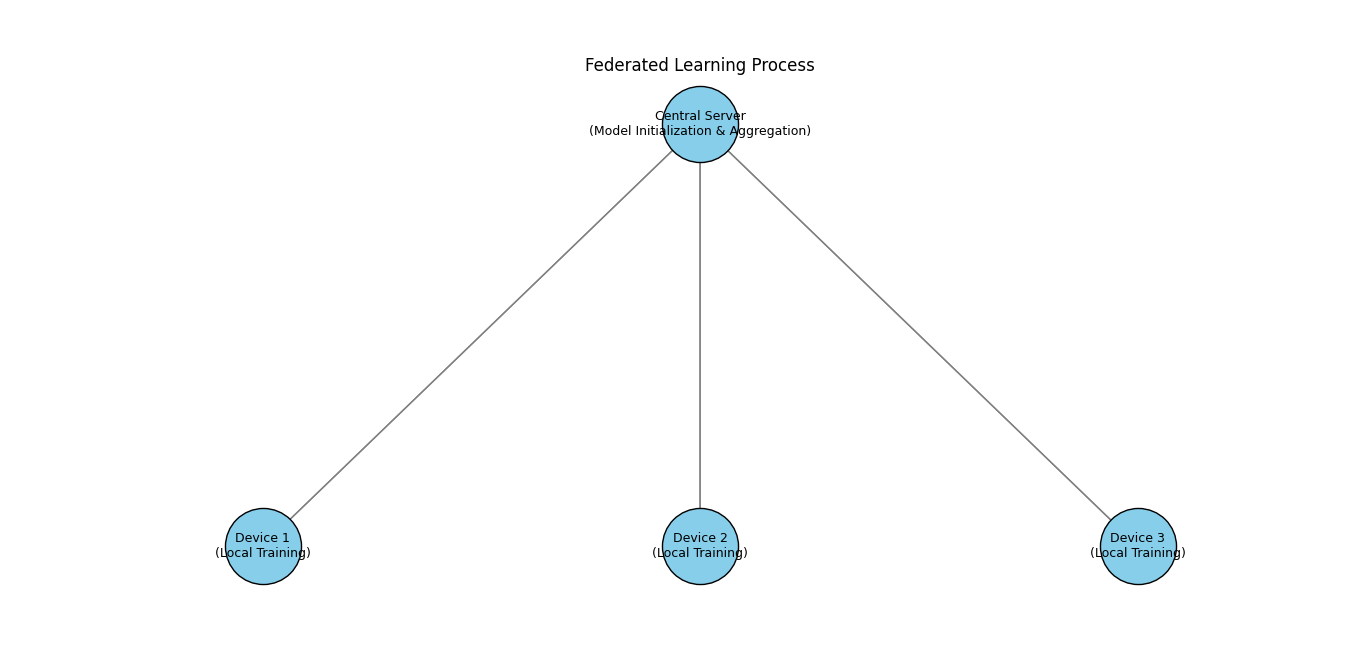
Federated learning is a cutting-edge approach in AI that prioritizes privacy and security by keeping data on local devices instead of transferring it to a central server. In traditional machine learning, data from various sources is pooled together for training models. This centralization raises privacy concerns and risks of data breaches.
Federated learning addresses these issues by enabling devices to train on local data and share only the model updates, not the raw data. This way, your personal information remains private while contributing to the overall model improvement. Imagine multiple smartphones collaborating to improve a shared AI model without sharing your personal messages or photos—this is the essence of federated learning.
Federated learning systems typically involve a central server that orchestrates the training process. The process includes:
- Model Initialization: The central server initializes a global model and sends it to all participating devices.
- Local Training: Each device trains the model using its local data, improving the model’s understanding based on individual datasets.
- Update Aggregation: Devices send the updated model parameters back to the server, not the actual data.
- Model Averaging: The server averages these updates to create an improved global model.
- Iteration: This cycle repeats, continually refining the model without compromising user data privacy.
Example: Google’s Federated Learning for Gboard
Google’s Gboard keyboard app uses Federated Learning to improve its language model. Without sending sensitive user data to the cloud, Gboard trains its model locally on users’ devices, ensuring data privacy. This approach enables Gboard to learn from user behavior and improve its autocorrect and suggestion features.
The Need for Federated Learning in AI
In traditional machine learning, data is collected and processed in a central location. This centralization raises significant privacy concerns. For example, when data is gathered in one place, it can become a target for breaches and misuse. Additionally, the practice of collecting data in silos creates barriers between organizations. This fragmentation means that knowledge and insights can’t be easily shared, limiting the potential of AI models.
Benefits of Federated Learning
Federated Learning presents a promising solution to these challenges. Here’s how it benefits the AI landscape:
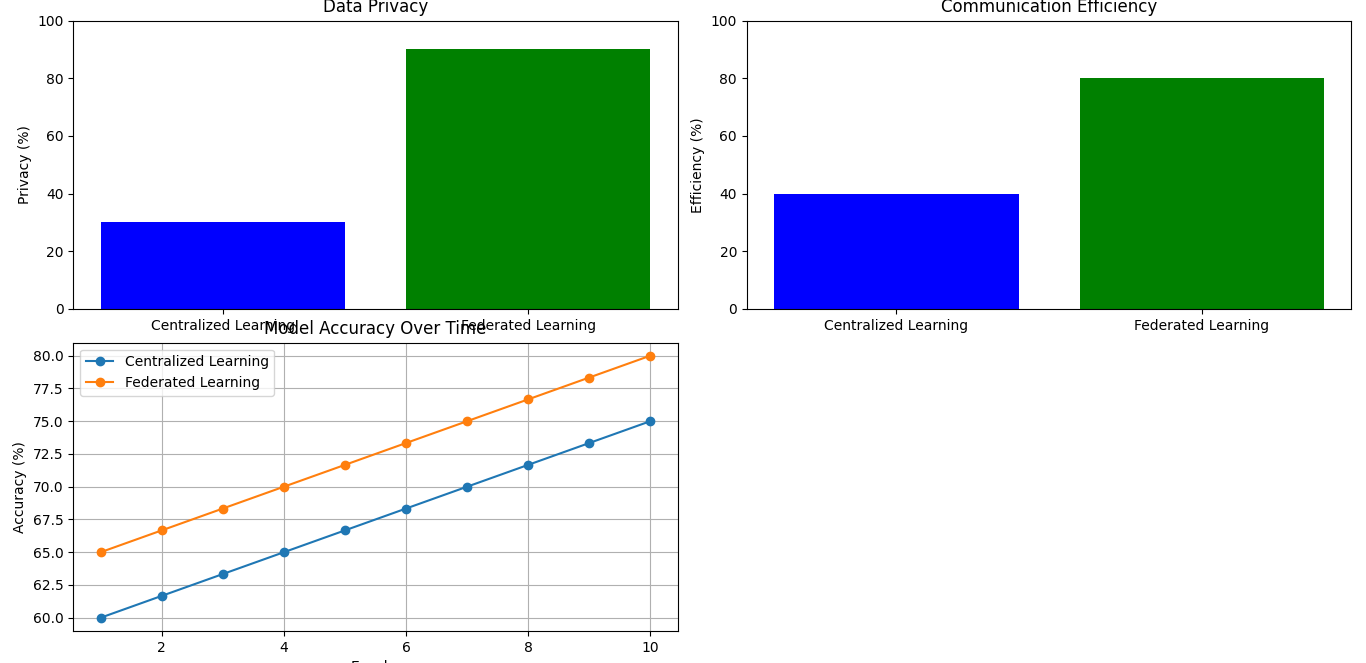
Improved Model Accuracy
One of the key advantages of Federated Learning is its ability to improve model accuracy. Instead of relying on data from a single source, Federated Learning aggregates data from multiple sources while keeping it decentralized. This diversity helps build more accurate and comprehensive AI models. By using data from different environments and contexts, these models can learn from a wider range of scenarios, enhancing their overall performance.
Enhanced Data Privacy
Another significant benefit of Federated Learning is enhanced data privacy. In this approach, sensitive data remains on local devices rather than being transferred to a central server. This setup minimizes the risk of data breaches and privacy violations. Since the data doesn’t leave its original location, it’s less exposed to potential threats, providing a higher level of protection for personal and sensitive information.
The Mechanics of Federated Learning
Federated Learning is a revolutionary approach to machine learning that enables multiple devices or organizations to collaborate on building a shared AI model without exchanging their raw data. In this section, we’ll explore the inner workings of Federated Learning, its key components, and how it compares to traditional centralized learning.
How Federated Learning Works
Federated Learning represents a modern approach to training machine learning models by focusing on data privacy and decentralized processing. This method involves multiple client devices working together to improve a shared global model while ensuring that sensitive data remains secure. Let’s explore the Federated Learning process in detail:
Data Decentralization in Federated Learning
Data decentralization is a core principle of Federated Learning, where each client device—such as smartphones, IoT devices, or edge servers—manages and processes its own data locally. This decentralized approach brings several key benefits:
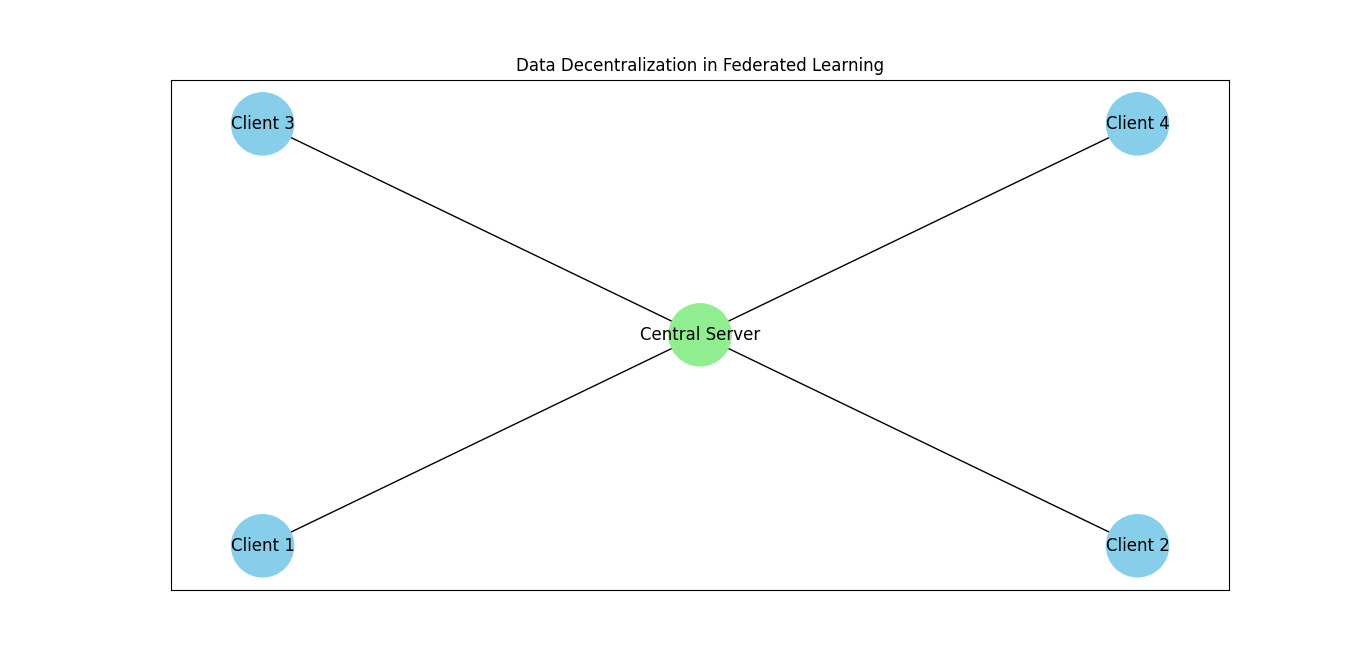
Local Data Storage
One of the primary advantages of data decentralization is local data storage. In Federated Learning, sensitive data remains on the device where it was generated. This method offers several important benefits:
- Enhanced Data Privacy: By keeping data on the local device, Federated Learning significantly reduces the risk of data breaches. Sensitive information, such as personal details or proprietary data, does not need to be transmitted to a central server. This localized handling minimizes exposure to potential security threats.
- Reduced Risk of Data Misuse: With data stored and processed locally, the chances of unauthorized access or misuse are lower. This approach helps in complying with privacy regulations and protecting user data from external threats.
Personalized Data Handling
Another significant benefit of data decentralization is personalized data handling. Each client device utilizes its own dataset, which leads to several advantages:
- Contextually Relevant Training: Local datasets often reflect unique patterns and characteristics specific to each device or user. Training models on these personalized datasets helps create models that are more contextually relevant and better suited to individual needs.
- Improved Model Performance: By leveraging diverse and specific data from various devices, Federated Learning can enhance the model’s ability to generalize and perform well across different scenarios. This results in more accurate and effective models that can adapt to the nuances of data from each device.
- Customization and Adaptation: Since each device trains the model using its own data, the resulting model can be customized to fit particular contexts or use cases. This personalized approach can lead to better user experiences and more effective machine learning solutions.
Local Model Training in Federated Learning
In Federated Learning, local model training is a crucial step where each client device independently trains its own model using the data it holds. This process plays a significant role in enhancing both the privacy and effectiveness of machine learning models. Here’s a closer look at how local model training works:
Training Local Models
Each client device performs model training on its own dataset. This approach has several benefits:
- Efficient Learning Process: Training the model locally means that the data never needs to be sent to a central server. This setup is efficient because it leverages the processing power of the device where the data resides, avoiding the need for large-scale data transfers.
- Privacy Preservation: By keeping the data on the device, local model training ensures that sensitive information remains confidential. There is no risk of exposing raw data to external sources, which is crucial for protecting user privacy and complying with data protection regulations.
Model Learning
The local model training process involves learning from the data specific to each device. This aspect has important implications:
- Data-Specific Learning: Each client’s model is trained using the unique patterns and features present in the local data. This means that the model becomes attuned to the specific characteristics of the data it processes. For example, a smartphone might learn different patterns compared to an IoT device due to variations in data types and usage contexts.
- Enhanced Model Accuracy: By incorporating data-specific learning, the local models contribute valuable insights into the global model. The diverse data sources help the global model become more comprehensive, capturing a wide range of patterns and features. This results in a global model that is better at generalizing and performing well across different scenarios.
- Adaptation to Local Contexts: Local models can adapt to the particular contexts in which they operate. For instance, a model trained on health data from wearable devices can become specialized in recognizing health-related patterns. This specialization enhances the model’s relevance and effectiveness for specific use cases.
Model Aggregation in Federated Learning
Model aggregation is a pivotal step in Federated Learning that ensures the collective improvement of a machine learning model based on updates from multiple client devices. Here’s a detailed look at the aggregation process:
Collecting Model Updates
Once local models have been trained on their respective client devices, these devices send their updates to a central server. This step involves:
- Receiving Updates: The server gathers updates from each client’s model. These updates consist of improvements and adjustments made during the local training phase. Each update includes information on how the local model has evolved based on the data it processed.
- Ensuring Consistency: The server must handle updates from potentially diverse sources. This involves managing different types of model changes and ensuring that all updates are compatible for aggregation.
Combining Updates
After receiving the updates, the server’s next task is to combine them into a single global model. This process includes:
- Aggregating Information: The server consolidates the model updates into a unified global model. This involves averaging or otherwise combining the various updates to reflect the collective learning from all participating clients. Techniques such as Federated Averaging (FedAvg) may be used to effectively integrate these updates.
- Incorporating Diverse Data: By aggregating updates from multiple devices, the server creates a model that benefits from a broad range of data sources. This diversity helps improve the global model’s accuracy and generalization capabilities. The aggregated model incorporates insights from different datasets, which can lead to a more comprehensive and effective machine learning model.
- Improving Model Quality: The aggregated global model represents the collective knowledge gained from the individual client models. This process enhances the model’s overall quality and performance by integrating various data patterns and features learned from different clients.
Model Update in Federated Learning
The model update phase is a crucial part of the Federated Learning process, ensuring that the improvements made by each client device are incorporated into a unified global model. Here’s a detailed look at this step:
Updating the Global Model
After the central server has aggregated the updates from various client devices, it must update the global model:
- Incorporating Improvements: The server integrates the combined model updates into the global model. This step reflects the collective learning that has occurred across all participating devices. The updated global model incorporates the advancements and adjustments made during local training, resulting in a more refined and effective model.
- Enhancing Model Performance: The new version of the global model benefits from the diverse data and insights gathered from each client. This aggregation enhances the model’s accuracy, performance, and ability to generalize across different scenarios. By incorporating improvements from a wide range of data sources, the global model becomes more robust and versatile in its applications.
- Maintaining Consistency: Updating the global model involves ensuring that all changes are consistently applied. The server must carefully merge the updates to maintain the integrity and quality of the model, ensuring that it performs well across all use cases.
Sending the Updated Model
Once the global model has been updated, the next step is to distribute it back to the client devices:
- Distributing the Model: The updated global model is sent to each client device. This distribution process allows clients to receive the latest version of the model, which now includes improvements derived from the collective training of all participants.
- Benefiting from Collective Improvements: By receiving the updated global model, each client device can leverage the enhancements made through the aggregation process. This ensures that all devices benefit from the collective learning, leading to improved model performance and accuracy at the individual client level.
- Continuing the Learning Cycle: With the updated global model, each client can start the next round of local training. This iterative process ensures continuous improvement and adaptation of the model based on new data and insights gathered by each device.
Local Model Update in Federated Learning
The local model update phase is the final step in the Federated Learning process, where each client device refines its model using the latest global model. Here’s a detailed explanation of how this process works:
Incorporating the Global Model
After receiving the updated global model from the central server, each client device adjusts its local model:
- Updating Local Models: Each client device integrates the global model into its local model. This involves adjusting the local model’s parameters to align with the improvements made during the global aggregation phase. The incorporation of the global model helps synchronize the local models with the collective advancements achieved through Federated Learning.
- Enhancing Performance: By aligning local models with the updated global model, clients benefit from the collective learning of all participating devices. This update leads to enhanced performance and accuracy at the local level. The model on each device becomes more effective in handling its specific data and use cases, thanks to the broader insights gained from the global model.
- Adaptation to Global Improvements: Local model updates ensure that each client’s model is adapted to reflect the latest improvements. This process helps in maintaining consistency and quality across different devices. The integration of the global model ensures that local models are not only tailored to their specific data but also benefit from the enhanced learning contributed by other clients.
Must Read
- How to Diagnose Overfitting in Machine Learning — 9 Proven Tools
- PyTorch Debugging Checklist: A Systematic Framework to Fix Models That Won’t Learn
- Why sorted() Is Safer Than list.sort() in Production Python Systems
- Monotonic Sequence in Python: 7 Practical Methods With Edge Cases, Interview Tips, and Performance Analysis
- How to Check if Dictionary Values Are Sorted in Python
Privacy and Security in Federated Learning
Federated Learning is designed to enhance machine learning while prioritizing data privacy and security. Here’s an in-depth look at how Federated Learning addresses these crucial aspects:
Data Privacy in Federated Learning

Federated Learning is built with privacy at its core, addressing concerns about sensitive data:
- Local Data Storage: In Federated Learning, data remains on the client devices and is not transferred to a central server. This approach ensures that personal or sensitive information does not leave the local device, greatly reducing the risk of data breaches and unauthorized access.
- Data Privacy Preservation: Since each client device processes its data locally, Federated Learning prevents the centralization of personal information. This model helps comply with privacy regulations such as GDPR and CCPA, as data privacy is maintained throughout the training process.
- Differential Privacy Techniques: Federated Learning can incorporate differential privacy mechanisms to add noise to the data, further protecting individual data points from being exposed or reverse-engineered during model training.
Security Measures in Federated Learning
Federated Learning employs various security measures to protect data and models:
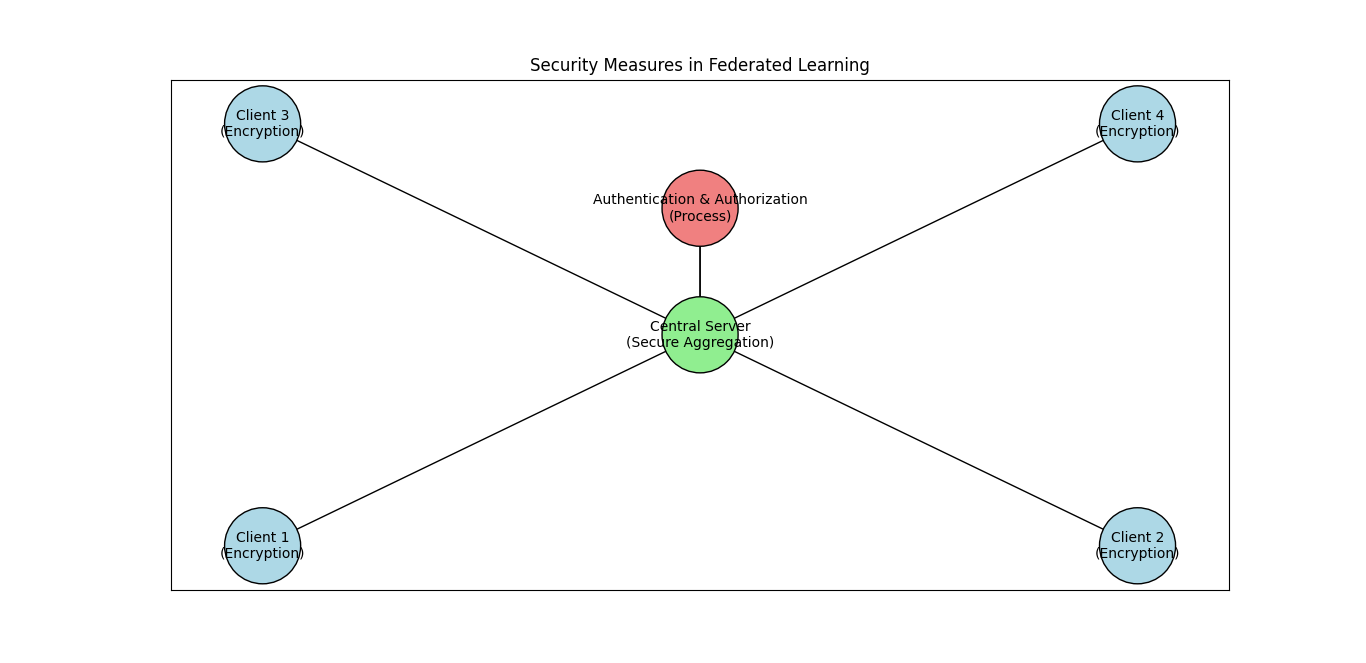
- Encryption: Data and model updates are often encrypted both in transit and at rest. Encryption techniques ensure that even if data or updates are intercepted, they cannot be accessed or understood without the proper decryption keys. This is crucial for maintaining the confidentiality and integrity of the information.
- Secure Aggregation: Secure aggregation protocols are used to combine model updates from different clients without revealing individual data contributions. This technique ensures that the central server cannot access raw data or detailed model updates from each client, preserving privacy while still enabling effective model training.
- Authentication and Authorization: Federated Learning systems often implement strong authentication and authorization protocols to ensure that only legitimate and authorized devices can participate in the training process. This helps prevent unauthorized access and potential security threats.
Challenges and Solutions in Federated Learning Security
While Federated Learning offers enhanced privacy and security, several challenges remain:
- Data Leakage Risks: Despite the use of encryption and secure aggregation, there is still a risk of data leakage through model updates. For example, attackers might infer information from aggregated updates.
- Solution: To mitigate this risk, advanced techniques such as secure multi-party computation (SMPC) and homomorphic encryption can be used. These methods provide additional layers of protection by ensuring that computations on encrypted data do not compromise privacy.
- Model Poisoning Attacks: Malicious clients could potentially introduce biased or harmful updates into the global model, affecting its performance and reliability.
- Solution: Implementing robust anomaly detection systems and federated learning safeguards can help detect and mitigate the impact of malicious updates. Regular monitoring and validation of model updates are essential to ensure the integrity of the learning process.
- Scalability Concerns: As the number of participating clients increases, managing and securing communications and updates can become more complex.
- Solution: Developing efficient and scalable security protocols and network management strategies can help handle the increased complexity. Ensuring that security measures can scale with the growing number of clients is crucial for maintaining privacy and security.
Applications of Federated Learning
Federated Learning is increasingly being adopted across various sectors due to its ability to enhance privacy and security while leveraging data from multiple sources. Here’s how Federated Learning is being applied in different domains:
Federated Learning in Healthcare
In the healthcare sector, Federated Learning offers significant advancements by enabling collaborative data analysis without compromising patient privacy:
- Patient Data Analysis: Federated Learning allows healthcare providers to collaboratively analyze patient data from multiple institutions without sharing sensitive information. For example, hospitals and research centers can work together to develop predictive models for disease outbreaks or patient outcomes, using data from each institution without needing to centralize it.
- Personalized Medicine: Federated Learning facilitates the development of personalized treatment plans by integrating data from various sources. It enables the creation of models that can predict how different patients will respond to specific treatments, based on diverse datasets from different healthcare providers. This approach helps in tailoring treatments to individual needs while keeping patient data secure.
- Collaborative Research: Researchers across different institutions can use Federated Learning to train models on large-scale health datasets. This collaborative approach accelerates the discovery of new medical insights and enhances the accuracy of predictive models, all while preserving the confidentiality of patient data.
Federated Learning in Finance
In the financial sector, Federated Learning is transforming how financial institutions handle data and protect user privacy:
- Privacy-Preserving Techniques: Financial institutions use Federated Learning to analyze transaction data and detect fraud without exposing sensitive financial information. By training models on local data at each institution and aggregating the results, Federated Learning helps in identifying fraudulent activities while ensuring that individual transaction details remain confidential.
- Risk Management: Federated Learning enables financial institutions to build more accurate risk assessment models by combining insights from multiple sources. This approach improves the accuracy of credit scoring and risk evaluation processes while maintaining the privacy of individual financial data.
- Collaborative Analytics: Banks and financial organizations can collaborate on joint analytics projects using Federated Learning. For instance, different banks can jointly develop models for predicting loan defaults or market trends, leveraging their collective data without sharing sensitive customer information.
Federated Learning in IoT
In the Internet of Things (IoT) sector, Federated Learning enhances the functionality and security of connected devices:
- Enhanced Security: Federated Learning allows IoT devices to learn from local data while keeping this data on the device. This reduces the risk of sensitive information being exposed during data transmission and helps protect against potential security breaches.
- Efficient Model Training: IoT devices can train models locally on their data and share only the model updates with a central server. This approach reduces the need for large-scale data transfers and makes the training process more efficient and secure.
- Collaborative Device Learning: By using Federated Learning, devices from different manufacturers can collaborate to improve models for tasks such as predictive maintenance or anomaly detection. For example, smart home devices can collectively learn about patterns in energy usage or detect unusual behaviors while keeping their data private.
Implementing Federated Learning
Here’s an example of federated learning on the MNIST dataset using TensorFlow Federated: A Decentralized Deep Learning Approach.
Federated Learning on MNIST with TensorFlow Federated: A Decentralized Deep Learning Approach
This code demonstrates a federated learning approach for training a convolutional neural network (CNN) on the MNIST dataset using TensorFlow Federated.
In this example, we simulate a federated learning scenario with multiple clients, each holding a portion of the MNIST dataset. We use TensorFlow Federated to implement the federated averaging process, which aggregates local model updates from clients to form a global model. The code covers the following key aspects:
- Data loading and preprocessing
- Federated data creation and client simulation
- Model definition and compilation
- Federated averaging process implementation
- Training and evaluation of the federated model
This code serves as a starting point for exploring federated learning and its applications in decentralized AI.
Before we start writing code, we need to set up the environment.
Setting up the environment for federated learning using TensorFlow Federated (TFF) and other dependencies involves several steps. Here’s a step-by-step guide to get you started:
1. Install Required Packages
First, you’ll need to install the necessary libraries. You can do this using pip, which is the Python package installer.
TensorFlow
pip install tensorflow
TensorFlow Federated
pip install tensorflow-federated
NumPy
pip install numpy
These commands will install TensorFlow for building and training the model, TensorFlow Federated for federated learning, and NumPy for handling data.
2. Set Up Your Python Environment
It’s a good practice to use a virtual environment to manage dependencies and avoid conflicts between different projects. Here’s how you can set up a virtual environment:
Using venv (Python’s Built-in Tool)
- Create a Virtual Environment:
python -m venv federated_env
2. Activate the Virtual Environment:
- On Windows:
federated_env\Scripts\activate
- On macOS/Linux:
source federated_env/bin/activate
- Install Packages Inside the Virtual Environment: After activating the virtual environment, install the required packages using the
pipcommands mentioned earlier.
3. Verify the Installation
To ensure that everything is set up correctly, you can run a simple script to check if TensorFlow and TensorFlow Federated are properly installed.
import tensorflow as tf
import tensorflow_federated as tff
print("TensorFlow version:", tf.__version__)
print("TensorFlow Federated version:", tff.__version__)
Save this script as check_installation.py and run it:
python check_installation.py
You should see the versions of TensorFlow and TensorFlow Federated printed out, indicating that they are correctly installed.
4. Prepare Your Workspace
Create a directory for your project and organize your files. For instance:
mkdir federated_learning_project
cd federated_learning_project
Inside this directory, you can have:
- A
notebooksfolder for Jupyter notebooks. - A
scriptsfolder for Python scripts. - A
datafolder for any datasets you use.
This setup will prepare your environment for developing and experimenting with federated learning using TensorFlow Federated. Now let’s start:
Here’s a explanation of the code for federated learning on the MNIST dataset using TensorFlow Federated:
1. Importing Libraries
import tensorflow as tf
import tensorflow_federated as tff
import numpy as np
We start by importing the necessary libraries:
- TensorFlow (
tf) for building and training the model. - TensorFlow Federated (
tff) for federated learning functionalities. - NumPy (
np) for handling arrays and data manipulation.
2. Loading MNIST Data
The load_mnist function handles loading the MNIST dataset:
def load_mnist():
(train_data, _), (test_data, _) = tf.keras.datasets.mnist.load_data()
train_data = train_data / 255.0 # Normalize to [0,1]
test_data = test_data / 255.0
return train_data, test_data
tf.keras.datasets.mnist.load_data(): This function loads the MNIST dataset, which consists of 28×28 grayscale images of handwritten digits (0-9). The data is split into training and testing sets. Here,train_datacontains the images and_(underscore) is a placeholder for labels (which are not used in this function). Similarly,test_datacontains the images and_is a placeholder for the labels in the test set.- Normalization:
train_data = train_data / 255.0andtest_data = test_data / 255.0scale the pixel values of the images from a range of 0-255 (the usual range for image pixels) to a range of 0-1. This helps the neural network to learn more effectively by ensuring that all input values are on a similar scale. - Return Values: The function returns two arrays:
train_dataandtest_data, which are now normalized.
3. Preprocessing Data
The preprocess function reshapes and formats the image data:
def preprocess(data):
data = data.reshape(-1, 28, 28, 1).astype(np.float32)
return data
- Reshape:
data.reshape(-1, 28, 28, 1)reshapes the data array. The-1automatically calculates the number of images based on the total number of elements, while28x28specifies the image dimensions and1indicates that these are grayscale images (single channel). This reshaping converts the data into the format expected by many deep learning frameworks:[number of images, height, width, channels]. - Data Type:
astype(np.float32)ensures that the data type of the array isfloat32. This is a common practice in machine learning to ensure that numerical operations are handled accurately and efficiently. - Return Value: The function returns the preprocessed data in the shape and format suitable for training a neural network.
4. Applying the Functions
train_data, test_data = load_mnist()
train_data = preprocess(train_data)
test_data = preprocess(test_data)
Loading Data: train_data, test_data = load_mnist() calls the load_mnist function to get the raw, normalized image data.
Preprocessing: train_data = preprocess(train_data) and test_data = preprocess(test_data) apply the preprocess function to reshape and format the data for both the training and test sets.
5. Creating Federated Data
def create_federated_data(train_data, num_clients):
federated_data = []
data_split = np.array_split(train_data, num_clients)
for data in data_split:
federated_data.append(tff.simulation.ClientData.from_tensor_slices((data, np.zeros_like(data))))
return federated_data
num_clients = 5
federated_data = create_federated_data(train_data, num_clients)
Function Definition:
create_federated_datais a function that takestrain_data(your training dataset) andnum_clients(the number of clients or devices) as inputs.
Initialize Federated Data:
- An empty list
federated_datais created to store the data for each client.
Split Data:
np.array_splitdividestrain_dataintonum_clientschunks. For instance, if you have 1000 samples and 5 clients, each client gets 200 samples.
Distribute Data:
- Each chunk of data is converted into a
ClientDataobject usingtff.simulation.ClientData.from_tensor_slices. This method creates a format compatible with TensorFlow Federated (TFF), with the data and a placeholder array of zeros (which serves as dummy labels in this case). TheClientDataobject is appended to thefederated_datalist.
Return Data:
- The function returns the
federated_datalist, now containing the data slices for all clients.
Usage:
- You set
num_clientsto 5 and call thecreate_federated_datafunction with yourtrain_dataandnum_clientsto prepare the federated dataset. The result is stored infederated_data.
6. Building the Keras Model
def create_keras_model():
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32, kernel_size=3, activation='relu', input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])
return model
Define the Function:
create_keras_modelis a function that sets up and returns a Keras model. Keras is a popular high-level API for building and training deep learning models.
Create a Sequential Model:
model = tf.keras.models.Sequential([])initializes a Sequential model. This means the layers are stacked one after another in a linear fashion.
Add Convolutional Layer:
tf.keras.layers.Conv2D(32, kernel_size=3, activation='relu', input_shape=(28, 28, 1))adds a 2D convolutional layer with 32 filters. Each filter has a 3×3 size, and the activation function used is ReLU (Rectified Linear Unit). Theinput_shapespecifies the shape of the input images, which is 28×28 pixels with a single color channel (grayscale).
Add MaxPooling Layer:
tf.keras.layers.MaxPooling2D(pool_size=2)adds a max-pooling layer with a pool size of 2×2. This layer reduces the spatial dimensions of the input, helping to reduce the number of parameters and computations in the network.
Flatten Layer:
tf.keras.layers.Flatten()flattens the output from the previous layer into a one-dimensional vector. This step is necessary before feeding the data into fully connected (dense) layers.
Add Dense Layer:
tf.keras.layers.Dense(10, activation='softmax')adds a dense (fully connected) layer with 10 units. The softmax activation function is used here, which is suitable for multi-class classification problems as it converts the output into probabilities for each class.
Compile the Model:
model.compile(optimizer='adam', loss='sparse_categorical_crossentropy', metrics=['accuracy'])compiles the model with the following settings:- Optimizer:
adam, which helps in adjusting the weights of the network during training. - Loss Function:
sparse_categorical_crossentropy, which is appropriate for classification tasks with integer labels. - Metrics:
accuracy, to evaluate the model’s performance based on the number of correct predictions.
- Optimizer:
Return the Model:
- The function returns the compiled Keras model, ready for training and evaluation.
7. Defining the Model Function for Federated Learning
def model_fn():
keras_model = create_keras_model()
return tff.learning.from_keras_model(
keras_model,
input_spec=tff.simulation.ClientData.from_tensor_slices((train_data[0:1], np.zeros_like(train_data[0:1]))).element_spec,
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()]
)
Explanation:
- Function Definition (
model_fn):- The function
model_fnis defined to create and configure a model specifically for use in TensorFlow Federated (TFF).
- The function
- Creating the Keras Model:
keras_model = create_keras_model():- This line calls the previously defined
create_keras_modelfunction to create a Keras model. The Keras model is a neural network defined with convolutional layers, pooling layers, and a dense output layer.
- This line calls the previously defined
- Converting Keras Model to TFF Model:
tff.learning.from_keras_model(...):- This function converts the Keras model into a TFF model that can be used in federated learning scenarios.
- Specifying Input Specifications:
input_spec=tff.simulation.ClientData.from_tensor_slices((train_data[0:1], np.zeros_like(train_data[0:1]))).element_spec:tff.simulation.ClientData.from_tensor_slices(...)is used to create a dummy dataset with the same shape as the actual training data.element_specprovides the shape and type information for the inputs, ensuring that TFF knows what kind of data it will handle.
- Setting Loss Function:
loss=tf.keras.losses.SparseCategoricalCrossentropy():- This specifies that the loss function used for training the model will be SparseCategoricalCrossentropy. This is suitable for multi-class classification problems where labels are integers.
- Defining Metrics:
metrics=[tf.keras.metrics.SparseCategoricalAccuracy()]:- This sets the evaluation metric to SparseCategoricalAccuracy, which measures how often the predicted labels match the true labels.
The model_fn function is essential for preparing your model for federated learning. It creates a Keras model and then adapts it for federated learning by specifying how it handles input data, what loss function to use, and which metrics to track. This setup is crucial for ensuring that the model can be trained and evaluated effectively in a federated setting.
8. Setting Up Federated Averaging
def create_federated_averaging_process():
return tff.learning.FederatedAveragingProcess(
model_fn=model_fn,
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=0.02),
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=1.0)
)
federated_averaging_process = create_federated_averaging_process()
- Function Definition (
create_federated_averaging_process):- This function sets up the Federated Averaging process, which is a method for training models across multiple clients in a federated learning environment.
- Creating Federated Averaging Process:
tff.learning.FederatedAveragingProcess(...):model_fn=model_fn:- Specifies the model function (
model_fn) that creates the model. This function will be used by both the clients and the server to build and train the model.
- Specifies the model function (
client_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=0.02):- Defines the optimizer for the clients. Here, we use Stochastic Gradient Descent (SGD) with a learning rate of 0.02. This determines how clients will update their local models.
server_optimizer_fn=lambda: tf.keras.optimizers.SGD(learning_rate=1.0):- Defines the optimizer for the server. The server also uses SGD, but with a learning rate of 1.0. This optimizer is responsible for aggregating the updates from the clients and updating the global model.
- Initializing Federated Averaging Process:
federated_averaging_process = create_federated_averaging_process():- This line creates an instance of the Federated Averaging process using the function defined above.
9. Running Federated Training
state = federated_averaging_process.initialize()
for round_num in range(1, 6):
state, metrics = federated_averaging_process.next(state, federated_data)
print(f'Round {round_num}, Metrics: {metrics}')
- Initializing the Training State:
state = federated_averaging_process.initialize():- This initializes the state of the Federated Averaging process. It sets up the initial conditions for the training process, including the starting point for the model and optimizers.
- Training Loop:
for round_num in range(1, 6)::- This loop runs for a specified number of rounds (1 to 5 in this case). Each round represents an iteration of training where the model gets updated based on the federated data.
- Training Process:
state, metrics = federated_averaging_process.next(state, federated_data):federated_averaging_process.next(...):- This function performs a single round of training. It takes the current state and federated data, updates the model, and returns the new state along with performance metrics.
print(f'Round {round_num}, Metrics: {metrics}'):- This line prints out the round number and the metrics obtained after each round. Metrics typically include performance indicators like accuracy and loss, providing insight into how well the model is learning.
This code snippet demonstrates the process of setting up and running federated learning using TensorFlow Federated. It involves defining a Federated Averaging process, initializing it, and then training the model across multiple rounds. By using Federated Averaging, you can train models in a distributed manner, using data from multiple clients while maintaining data privacy.
Future of Federated Learning
Federated learning is rapidly evolving, and its future promises to bring both exciting advancements and new challenges. Let’s explore the current trends, its role in ethical AI, and the hurdles and future directions for this innovative approach.
Advancements in Federated Learning
The field of federated learning is witnessing significant progress. Recent advancements focus on enhancing efficiency, scalability, and accuracy. Key areas of development include:
- Enhanced Communication Efficiency: New techniques are emerging to reduce the communication costs associated with federated learning. Innovations like compression algorithms and efficient aggregation methods help in minimizing the amount of data exchanged between clients and servers, making federated learning more practical for large-scale systems.
- Improved Algorithms: Researchers are developing more sophisticated algorithms that better handle the challenges of non-IID (independent and identically distributed) data. These advancements ensure that models trained using federated learning can perform well even when data distributions vary significantly across clients.
- Increased Privacy Measures: The latest methods include advanced privacy-preserving techniques, such as differential privacy and secure multi-party computation. These techniques ensure that sensitive data remains confidential while still allowing for effective model training.
- Integration with Edge Computing: Federated learning is increasingly being integrated with edge computing devices. This combination leverages the processing power of edge devices to perform computations locally, reducing latency and improving the responsiveness of applications.
The Role of Federated Learning in AI Ethics
Federated learning plays a crucial role in the development and usage of ethical AI systems. Here’s how it contributes to ethical AI practices:
- Data Privacy and Security: By keeping data on local devices and only sharing model updates, federated learning significantly enhances data privacy. This approach aligns with ethical principles by protecting user information and minimizing the risk of data breaches.
- Bias Mitigation: Federated learning allows for models to be trained on diverse datasets from various sources. This can help in reducing bias and improving fairness in AI systems, as the model can learn from a wide range of data sources rather than being limited to a single, potentially biased dataset.
- Informed Consent: Users have more control over their data in a federated learning setup. They can be informed about how their data contributes to model training and can opt out if they choose, ensuring that their participation is voluntary and informed.
Federated Learning: Challenges and Future Directions
While federated learning shows great promise, it also faces several challenges and has potential future directions:
- Scalability Issues: As federated learning systems grow, managing a large number of clients and ensuring efficient communication and aggregation become increasingly complex. Scaling these systems while maintaining performance and efficiency is an ongoing challenge.
- Data Heterogeneity: Federated learning systems often deal with data that is non-IID. Developing techniques to handle this data heterogeneity effectively remains a significant challenge. Future research will likely focus on improving algorithms that can accommodate diverse and unevenly distributed data.
- Security Concerns: Even with advanced privacy measures, federated learning systems are not immune to security threats. Ensuring that models and data remain secure against potential attacks and ensuring the robustness of privacy-preserving methods are critical areas for future research.
- Regulatory and Ethical Standards: As federated learning becomes more widespread, establishing regulatory frameworks and ethical standards will be essential. This includes ensuring that federated learning practices align with global data protection regulations and ethical guidelines.
Conclusion
Federated learning represents a groundbreaking shift in how we approach AI training, especially when it comes to enhancing AI security and fostering a more secure and privacy-conscious future. As we wrap up our exploration of federated learning, let’s recap its significance and the exciting possibilities that lie ahead.
The Impact of Federated Learning on AI Security
Federated learning has a profound impact on AI security by addressing several critical challenges in data privacy and model protection:
- Data Privacy: One of the core benefits of federated learning is its ability to keep sensitive data on local devices. Instead of sending raw data to a central server, federated learning only transmits model updates. This approach significantly reduces the risk of data breaches and ensures that personal information remains confidential.
- Enhanced Security Measures: Federated learning integrates advanced security techniques like differential privacy and secure multi-party computation. These methods enhance the confidentiality of the data used in model training, providing additional layers of security against potential threats.
- Minimized Data Exposure: By decentralizing the data processing, federated learning minimizes the amount of data exposed to potential attackers. This distributed approach makes it harder for unauthorized parties to access sensitive information, thus strengthening overall security.
- Ethical AI Development: Federated learning supports the ethical development of AI systems by ensuring that user consent and privacy are prioritized. It aligns with ethical standards and regulations by providing a framework where users are informed about how their data is used and can opt out if they prefer.
The Path Forward
The future of federated learning is full of promise, and its potential to create a secure AI future is substantial. Here’s why exploring federated learning is a step worth taking:
- Innovation and Research Opportunities: The field of federated learning is still evolving, with ongoing research opening up new possibilities for improving data security, privacy, and model performance. Researchers and practitioners have the opportunity to contribute to groundbreaking work that will shape the future of AI.
- Broader Adoption: As federated learning techniques mature, their adoption across various industries will likely increase. This adoption can lead to the development of more secure and privacy-focused AI applications, benefiting both businesses and individuals.
- Collaboration and Community: Engaging with the federated learning community can provide valuable insights and foster collaboration. By sharing knowledge and experiences, the community can drive forward innovations that address current challenges and explore new applications.
- Real-World Impact: Federated learning has the potential to make a significant impact on real-world applications, from healthcare and finance to smart devices and personalized services. By focusing on secure and private data handling, federated learning can improve trust and security in these critical areas.
In conclusion, federated learning is not just a technological advancement; it’s a pivotal development in the quest for secure and ethical AI. As we move forward, embracing federated learning and contributing to its evolution will be crucial in creating a future where AI systems are both powerful and respectful of user privacy. Exploring this field offers a unique opportunity to be at the forefront of AI innovation while ensuring that security and ethical considerations remain a top priority.
External Resources
Google AI Blog: Federated Learning
- Google’s blog provides an in-depth look at federated learning, its applications, and advancements.
- Read more
TensorFlow Federated (TFF) Documentation
- TensorFlow Federated is an open-source framework for machine learning and other computations on decentralized data.
- Explore TFF
OpenMined: Federated Learning Course
- OpenMined offers a comprehensive course on federated learning, covering the basics and advanced topics.
- Enroll in the course
MIT Technology Review: How Federated Learning is Transforming AI
- This article provides insights into how federated learning is changing the landscape of artificial intelligence.
- Read the article
The Alan Turing Institute: Federated Learning Research
- The Alan Turing Institute conducts cutting-edge research on federated learning and its implications for AI security and privacy.
- Discover their research
FAQs
What is federated learning?
Federated learning is a machine learning technique where multiple devices collaboratively train a model while keeping the data decentralized. Each device trains the model on its local data and only shares the model updates, not the raw data, ensuring data privacy.
How does federated learning enhance data privacy?
Federated learning enhances data privacy by keeping the data on local devices. Only the model updates are shared with a central server, minimizing the risk of exposing sensitive information.
How does federated learning improve AI security?
Federated learning improves AI security by reducing the risk of data breaches. Since the data is not transferred to a central server, there is less opportunity for attackers to access sensitive information.
How is federated learning used in real-world applications?
Federated learning is used in various real-world applications such as:
- Healthcare: Training models on patient data without compromising privacy.
- Finance: Enhancing fraud detection systems using decentralized data.
- Smart Devices: Improving user experience by training models on local data from smartphones and IoT devices.
Can federated learning be used with other AI technologies?
Yes, federated learning can be combined with other AI technologies such as differential privacy and homomorphic encryption to further enhance data security and privacy during model training.

")



")
Leave a Reply