

Machine Learning Production Pipeline: Complete System Design Guide
A machine learning production pipeline is where most ML projects fail — not because the model is wrong, but because the system around it is missing.
Series: Production ML Engineering — Article 01 of 15 (Pillar Post) This is the hub of a 15-part series on taking ML systems from prototype to production. Each section links to a dedicated deep-dive article.
Simple definition: Production ML engineering is how you keep ML models working after they leave your notebook — reliably, safely, and at scale.
You trained a model. Accuracy is strong. The notebook runs clean. Stakeholders are excited.
Then comes the question nobody in the meeting room is quite prepared to answer:
“Can we put this in production by next month?”
This is where most machine learning projects quietly die — not because the model was wrong, but because there was no system around it.
Here is the typical trajectory: the model ships, predictions flow, and business metrics look fine — for a few weeks. Then an upstream team changes a schema. Transaction patterns shift. The model keeps serving confident predictions, but they are increasingly wrong. Nobody notices, because nobody built anything to watch.
By week six, a stakeholder flags that conversion rates are down. An engineer digs in. The model has been degrading for weeks, and the path back is murky — the original training data was never versioned, the deployment was manual, and the engineer who wrote the retraining script has since moved to another team.
This is not a hypothetical. It is the standard failure pattern for production ML teams that skip the system-building work.
Production ML engineering is the discipline of building the system that prevents this — and recovers from it when it happens anyway.
What Is Production ML Engineering?
Simple definition: Production ML engineering is the practice of designing, deploying, and operating machine learning systems that function reliably, safely, and at scale in real-world environments.
It sits at the intersection of three disciplines — software engineering, data engineering, and ML research — borrowing from all three while being reducible to none of them.
The cleanest framing: ML research answers “can this work?” Production ML engineering answers “will this keep working?”
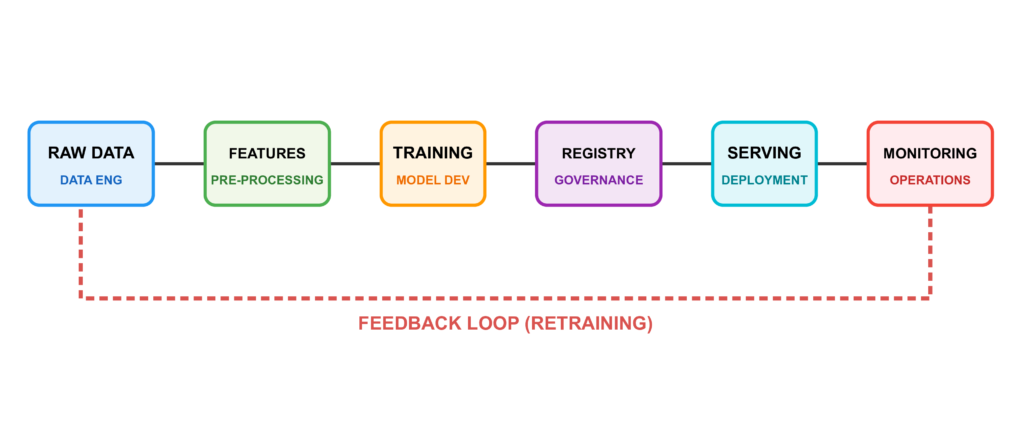
A production ML system does not end when you call model.fit(). It encompasses:
- Data infrastructure — versioned, validated pipelines that deliver clean data for both training and serving
- Reproducible training — automated workflows that can regenerate any model artifact on demand, at any point in time
- Serving and deployment — exposing predictions through APIs, containers, or batch jobs in a stable, scalable way
- Monitoring and observability — continuously tracking whether the model is still performing as expected on live data
- Continual learning — updating models safely as the world changes, without breaking what already works
You will also encounter the term MLOps — Machine Learning Operations — which refers to the cultural and tooling movement around these same ideas. The distinction worth preserving: MLOps is about processes and organisational practices; production ML engineering is about hands-on implementation. This series focuses firmly on the implementation side.
Why Most ML Models Never Make It to Production
Industry surveys and practitioner reports have consistently found that the large majority of ML models built in enterprise settings never reach production. Gartner’s research on AI adoption [1], a widely-cited VentureBeat analysis [2], and academic practitioner surveys have all pointed in the same direction over several years: the gap between a working prototype and a working production system is far larger than most teams anticipate.
The specific figures vary across studies and definitions, and should be read as directional rather than precise. What matters is the consistent finding: most ML projects fail at the system level, not the modelling level.
Key Insight: The research-to-production failure rate is not a modelling problem. It is a systems and reliability problem. Solving it requires engineering discipline, not better algorithms.
The Research-to-Production Translation Problem
Academic ML optimises for a single, clean objective: model performance on a held-out test set. Production ML optimises for something genuinely harder: sustained performance on a distribution of real inputs, over an indefinite time horizon, in the presence of a changing world.
These are different objectives. A model that achieves strong accuracy on a benchmark can fail in production because:
- the training data does not match live inputs
- features are computed differently at inference time
- user behaviour has shifted since training
- no one has defined what failure looks like, so degradation goes undetected until a business metric moves
Six Failure Modes That Account for Most Production Failures
Based on published post-mortems, practitioner surveys, and the foundational work on ML technical debt by Sculley et al. at Google [3], these six patterns account for the majority of production ML failures.
1. Training-serving skew
Failure Pattern: Training-serving skew is the most silent failure mode in production ML.
Features used during training are computed differently at inference time. This can be as direct as a normalisation step applied in training but forgotten in serving code, or as subtle as a time-based aggregation using different window sizes depending on which system runs it.
The result: the model is never actually evaluated on the distribution it will see in production. It degrades not because the world changed, but because it was never measuring the right thing to begin with.
2. Data pipeline brittleness
Production data is messy. Upstream schema changes, missing values, delayed events, and null-propagating bugs all cause silent failures that accuracy metrics cannot detect until significant damage has already been done. The pipeline was built to handle the expected case, and nobody modelled what would happen when the input assumptions broke. A model is only as reliable as the pipeline feeding it.
3. No monitoring for drift
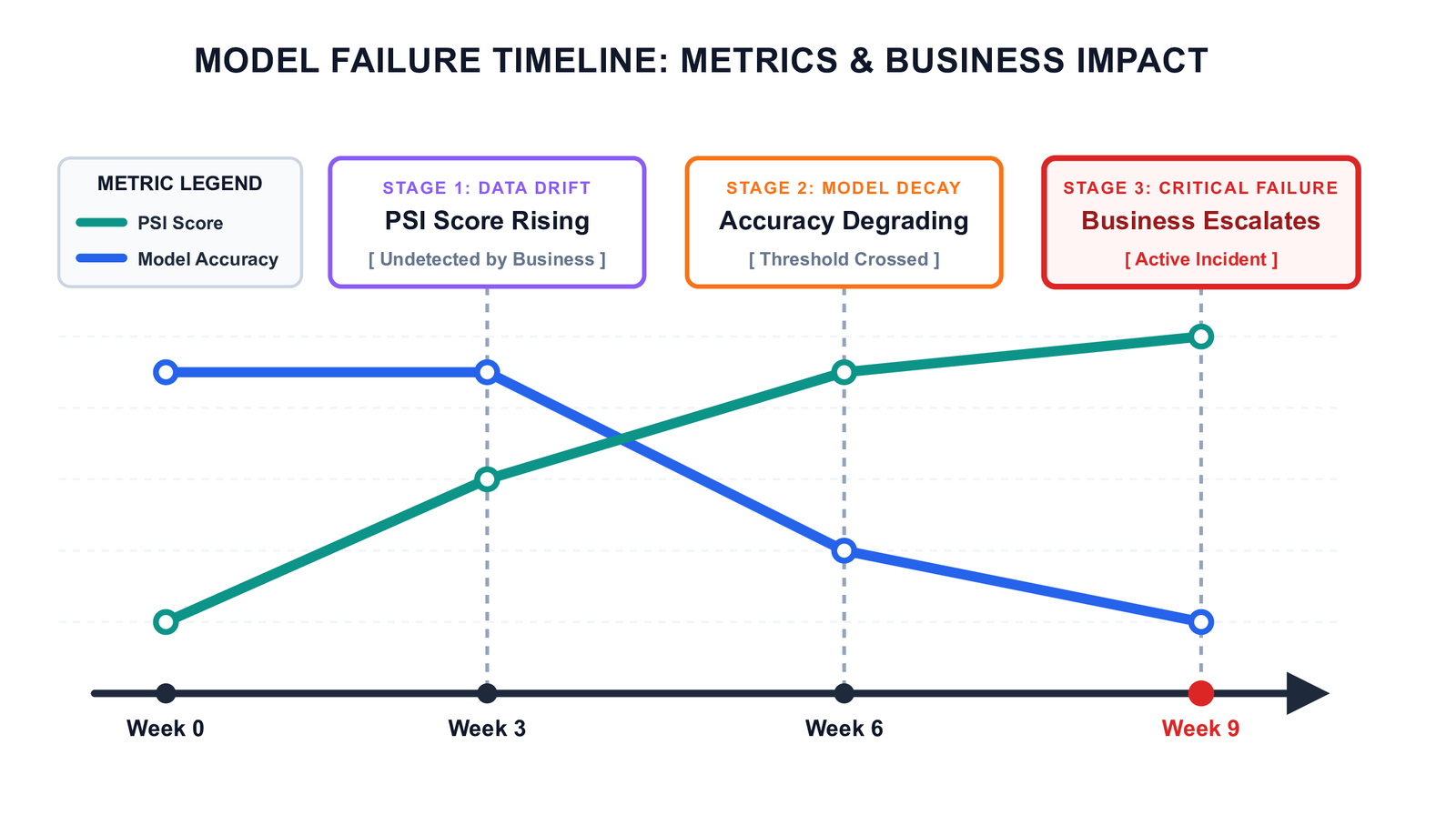
A model trained six months ago on last year’s data may perform well on day one. But user behaviour shifts, market conditions evolve, and upstream systems change. Without continuous monitoring, there is no mechanism to detect when performance has meaningfully degraded. The failure is not sudden — it is a slow slide that becomes visible only after it has already cost something.
Key Insight: Monitoring is not a nice-to-have that gets added when the system is mature. It needs to be in place before the model ships — because by the time you realise you need it, the drift has already happened.
4. Manual retraining processes
When retraining is an undocumented procedure that a single engineer knows how to run, it is not a process — it is a single point of failure wrapped in tribal knowledge. When that engineer leaves or is unavailable during an incident, the system is effectively frozen.
5. Absent rollback strategy
Teams deploy a new model version without a tested path back to the previous version. A bad deployment becomes an incident rather than a routine reversion. The fix — versioned artifacts, blue-green deployment, traffic routing controls — is not complicated. But it needs to be designed before deployment, not scrambled for during an outage.
6. No ownership model
The data scientist who built the model has moved on. The software engineers who deployed it do not understand its failure modes. Nobody is responsible for its long-term health. This is an organisational problem that manifests technically: alerts go unacknowledged, retraining cadences slip, and gradual degradation becomes a crisis before anyone treats it as one.
Machine Learning Production Pipeline: The 5 Core Pillars
Key Insight: Production ML engineering is fundamentally a reliability engineering problem that happens to involve machine learning — not a machine learning problem that incidentally gets deployed.
Every production ML system — regardless of framework, cloud provider, or scale — rests on five foundational pillars. Weakness in any one creates a class of failures the other four cannot compensate for.
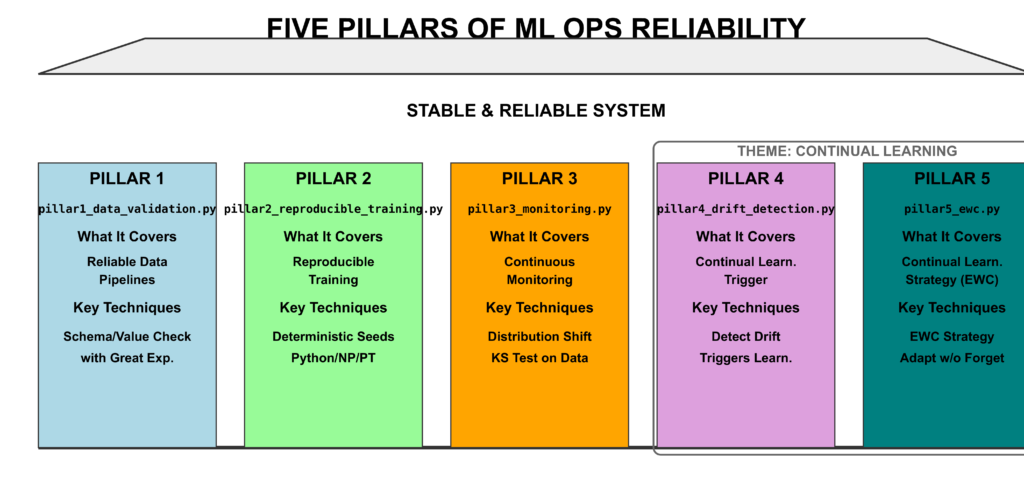
Pillar 1: Data Layer in a Machine Learning Production Pipeline
How to deploy a machine learning model to production starts here: if the data is wrong, the model is wrong — and you may not know it.
A reliable ML data pipeline has five properties that distinguish it from a general-purpose ETL pipeline.
Versioning. Every dataset used to train a model must be reproducible. If you retrain six months from now, you need to reconstruct the exact training data used today. Tools like DVC [4], Delta Lake [5], and LakeFS [6] address this at the data layer.
Validation. Data entering the pipeline should be validated against a schema that captures not just types, but statistical properties — expected distributions, acceptable ranges, cardinality constraints. Validation failures should be loud and halt the pipeline. Silent propagation of corrupt data is far more dangerous than a visible failure. Great Expectations [8] is a widely adopted framework-agnostic solution:
import great_expectations as ge
df = ge.read_csv("training_data.csv")
df.expect_column_values_to_not_be_null("user_id")
df.expect_column_values_to_not_be_null("label")
df.expect_column_values_to_be_between("age", min_value=0, max_value=120)
df.expect_column_values_to_be_of_type("label", "int")
results = df.validate()
if not results["success"]:
raise ValueError(f"Data validation failed: {results}")Feature consistency. The same feature must be computed identically in the training pipeline and the serving pipeline. The best engineering solution is a feature store — a centralised service that makes the same computation available to both training and serving. Without one, training-serving skew is a constant risk. Feast [9], Tecton [10], and Hopsworks [11] are the most common production options.
Lineage tracking. You need to know, for any model artifact, exactly which data it was trained on, which transformations were applied, and in what order. This supports debugging and is increasingly required for ML governance and compliance audits.
Pipeline monitoring. The data pipeline itself needs to be monitored — not just the model. Upstream schema changes, volume drops, freshness delays, and null rate spikes are signals that the model’s input distribution may have shifted, often days or weeks before output quality measurably degrades.
📖 Deep dive: [Article 02 — How to Deploy a Machine Learning Model to Production] covers pipeline setup end to end, including Docker-based serving and CI/CD integration.
Pillar 2: Reproducible Training
If you cannot reliably reproduce a model artifact, you cannot safely update it.
Reproducible training means that given the same code, data, and configuration, you can regenerate the same model — or a functionally equivalent one — at any point in time.
Experiment tracking. Every training run should log its hyperparameters, data version, code commit hash, environment dependencies, and output metrics. MLflow [12] and Weights & Biases [13] are the most widely adopted tools.
Environment pinning. Training should run inside a containerised environment with fully pinned dependencies. Docker provides strong guarantees by isolating the OS, CUDA version, and system libraries.
Deterministic training. Many training procedures are non-deterministic by default. For PyTorch [35]:
import torch
import numpy as np
import random
SEED = 42
torch.manual_seed(SEED)
torch.cuda.manual_seed_all(SEED)
np.random.seed(SEED)
random.seed(SEED)
# Full determinism at some performance cost
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = FalseNote: Full bit-for-bit reproducibility across hardware and CUDA versions is not always achievable — the PyTorch documentation is explicit about this [14]. The practical goal is to reduce variance enough that training runs are functionally reproducible.
Model registry. Every trained model artifact should be stored in a versioned registry with metadata linking it to the experiment that produced it. The registry becomes the single source of truth for which version is in production, staging, or archived. MLflow Model Registry [12] and Weights & Biases Artifact system [13] both serve this purpose.
📖 Deep dive: [Article 04 — ML Model Versioning: How to Track, Roll Back, and Manage Models in Production]
Pillar 3: Deployment in a Machine Learning Production Pipeline
A model that cannot be reliably served is not a production asset — it is a liability.
Getting the model to respond to a single API request locally is easy. Getting it to handle variable load, recover from failures, deploy new versions without downtime, and integrate cleanly with downstream systems is a different engineering problem entirely.
Containerisation. Every model should be packaged as a Docker container that includes the model artifact, inference code, and all dependencies.
FROM python:3.11-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
COPY model/ ./model/
COPY serve.py .
EXPOSE 8000
CMD ["uvicorn", "serve:app", "--host", "0.0.0.0", "--port", "8000"]REST API serving. FastAPI [15] is the current standard for ML serving APIs in Python — automatic OpenAPI documentation, request validation via Pydantic, async support, and strong performance. BentoML [16] and Seldon Core [17] offer higher-level abstractions for more complex serving requirements.
Health checks and graceful degradation. Every serving endpoint should implement /health and /ready endpoints. A model that fails a health check should be replaced — not left serving increasingly wrong predictions silently.
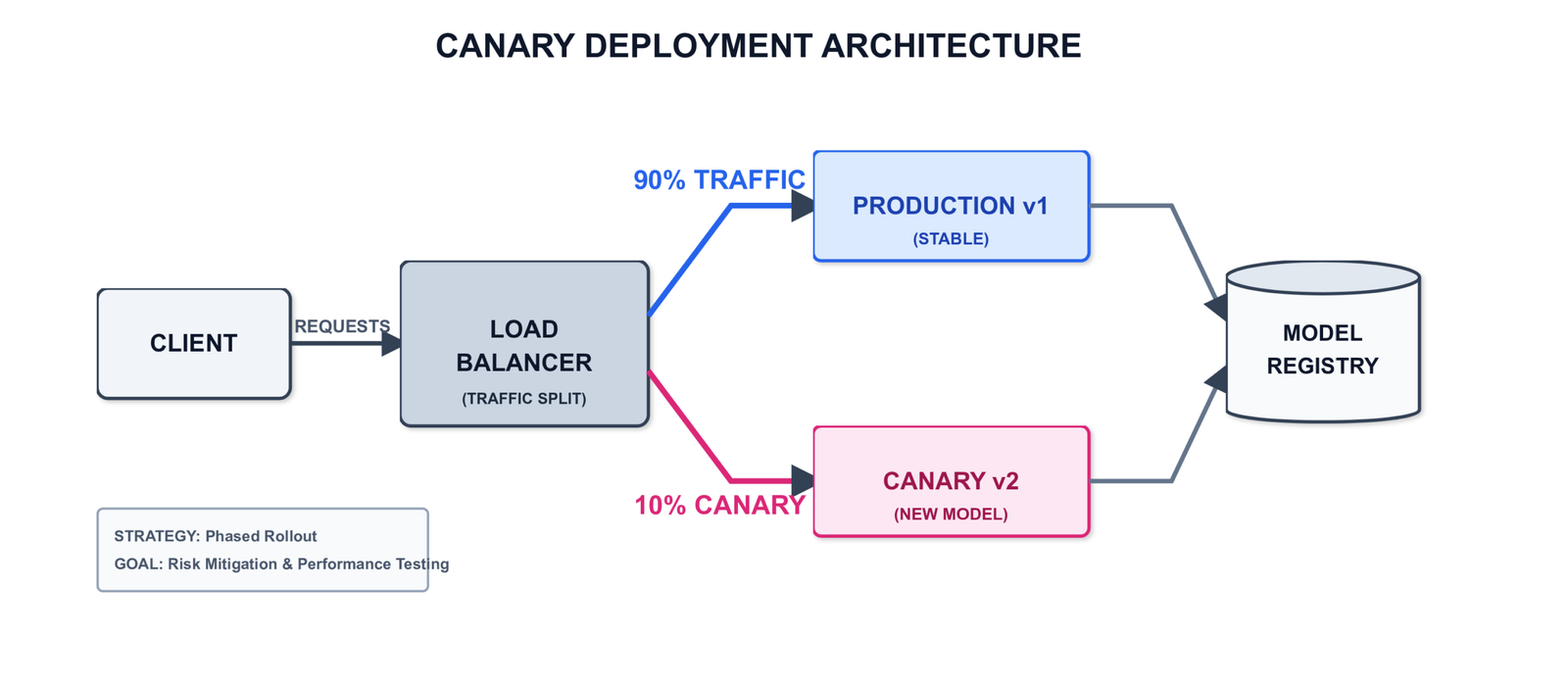
Versioned endpoints with canary deployment. Blue-green or canary strategies route a percentage of traffic to a new model version while keeping the previous version live. The rollback should be tested before it is needed, not designed during an incident.
Latency and throughput budgets. Before deploying, define explicit SLAs: maximum acceptable p99 latency, minimum throughput the system must sustain.
📖 Deep dive: [Article 02 — How to Deploy a Machine Learning Model to Production] and [Article 03 — How to Build an ML Retraining Pipeline That Won’t Break in Production]
Monitoring in a Machine Learning Production Pipeline
How to detect data drift and model decay in production — before your business stakeholders detect it for you.
A deployed model is not a finished product. It is a system that requires ongoing observation.
There are three forms of drift worth distinguishing:
- Data drift — the distribution of input features in production diverges from the training distribution
- Concept drift — the underlying relationship between inputs and outputs changes, even if the input distribution stays relatively stable
- Label drift — the distribution of outcomes changes (e.g., class imbalance shifts significantly after deployment)
Detecting these forms of drift requires statistical tests applied continuously to production data:
- Kolmogorov-Smirnov (KS) test for continuous features — tests whether two samples are drawn from the same distribution [18]
- Population Stability Index (PSI) — widely used in credit risk modelling, measures how much a feature distribution has shifted [19]
- Maximum Mean Discrepancy (MMD) — a kernel-based method that works for high-dimensional feature spaces [20]
from scipy.stats import ks_2samp
def detect_drift(train_feature: list, prod_feature: list, threshold: float = 0.05) -> bool:
"""
Run a KS test to detect distribution shift.
Returns True if drift is detected (p-value below threshold).
"""
statistic, p_value = ks_2samp(train_feature, prod_feature)
drift_detected = p_value < threshold
print(f"KS Statistic: {statistic:.4f} | p-value: {p_value:.4f}")
print(f"Drift detected: {drift_detected}")
return drift_detectedKey Insight: PSI often detects distribution shift weeks before it becomes visible as an accuracy drop. This is what makes monitoring genuinely valuable — not as a post-mortem tool, but as an early warning system that gives you time to act before the business notices.
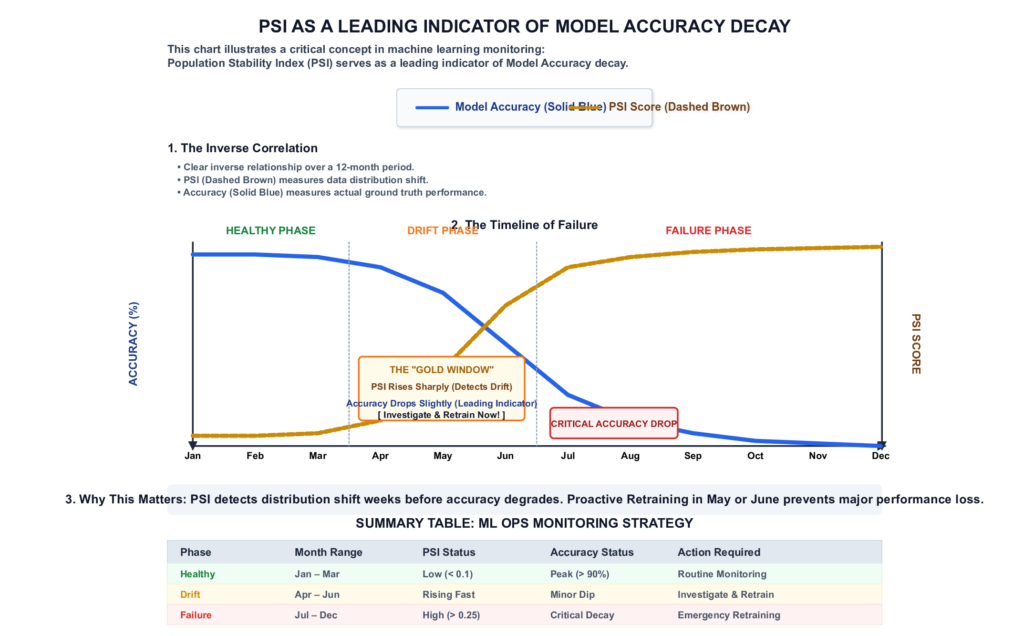
Beyond drift, production monitoring should track prediction distributions, model calibration, and the downstream business metrics the model is ultimately supposed to move.
📖 Deep dive: [Article 09 — ML Model Monitoring: How to Detect Data Drift and Model Decay in Production] and [Article 10 — How to Build an ML Monitoring Dashboard from Scratch]
Pillar 5: Continual Learning
The best model you can deploy today is not the best model you will need twelve months from now.
The final pillar addresses what monitoring tells you when a model is degrading: how do you update it safely, efficiently, and without creating new problems in the process?
Continual learning refers to systems that can incorporate new data and update their representations without retraining from scratch, and without catastrophically forgetting what they previously learned.
Neural networks, when fine-tuned on new data, have a strong tendency to overwrite the weights that represented previously learned patterns. A model retrained purely on recent data may perform well on current examples while losing accuracy on the original training distribution [21].
The primary strategies for handling this trade-off are:
Elastic Weight Consolidation (EWC), introduced by Kirkpatrick et al. at DeepMind [21], identifies which weights are most important for previously learned tasks and applies a regularisation penalty that resists updates in those directions:
def ewc_loss(model, original_params, fisher_diag, criterion, outputs, labels, lambda_ewc=0.4):
"""
Combines task loss with EWC regularisation.
lambda_ewc controls a genuine tension:
- Too high → model resists learning new patterns (underfits new distribution)
- Too low → model overwrites old knowledge (catastrophic forgetting)
Tune this on a held-out evaluation set that includes both old and new examples.
"""
task_loss = criterion(outputs, labels)
ewc_penalty = 0
for name, param in model.named_parameters():
fisher = fisher_diag[name]
old_param = original_params[name]
ewc_penalty += (fisher * (param - old_param) ** 2).sum()
return task_loss + (lambda_ewc / 2) * ewc_penaltyExperience Replay maintains a buffer of representative samples from previous training distributions and mixes them into each retraining batch. It is simpler than EWC and often more practical in production — but requires storing historical data, which introduces storage costs and potential privacy considerations.
Progressive Neural Networks [22] add new network capacity for new tasks while keeping existing columns frozen — guaranteeing no forgetting at the cost of a growing memory footprint. This is the right choice when tasks are genuinely distinct; it is overkill for typical distribution shift scenarios.
📖 Deep dive: [Article 05 — How to Prevent Catastrophic Forgetting in PyTorch], [Article 06 — Online Learning in Python], and [Article 07 — Continual Learning in PyTorch]
ML Infrastructure vs Research Infrastructure
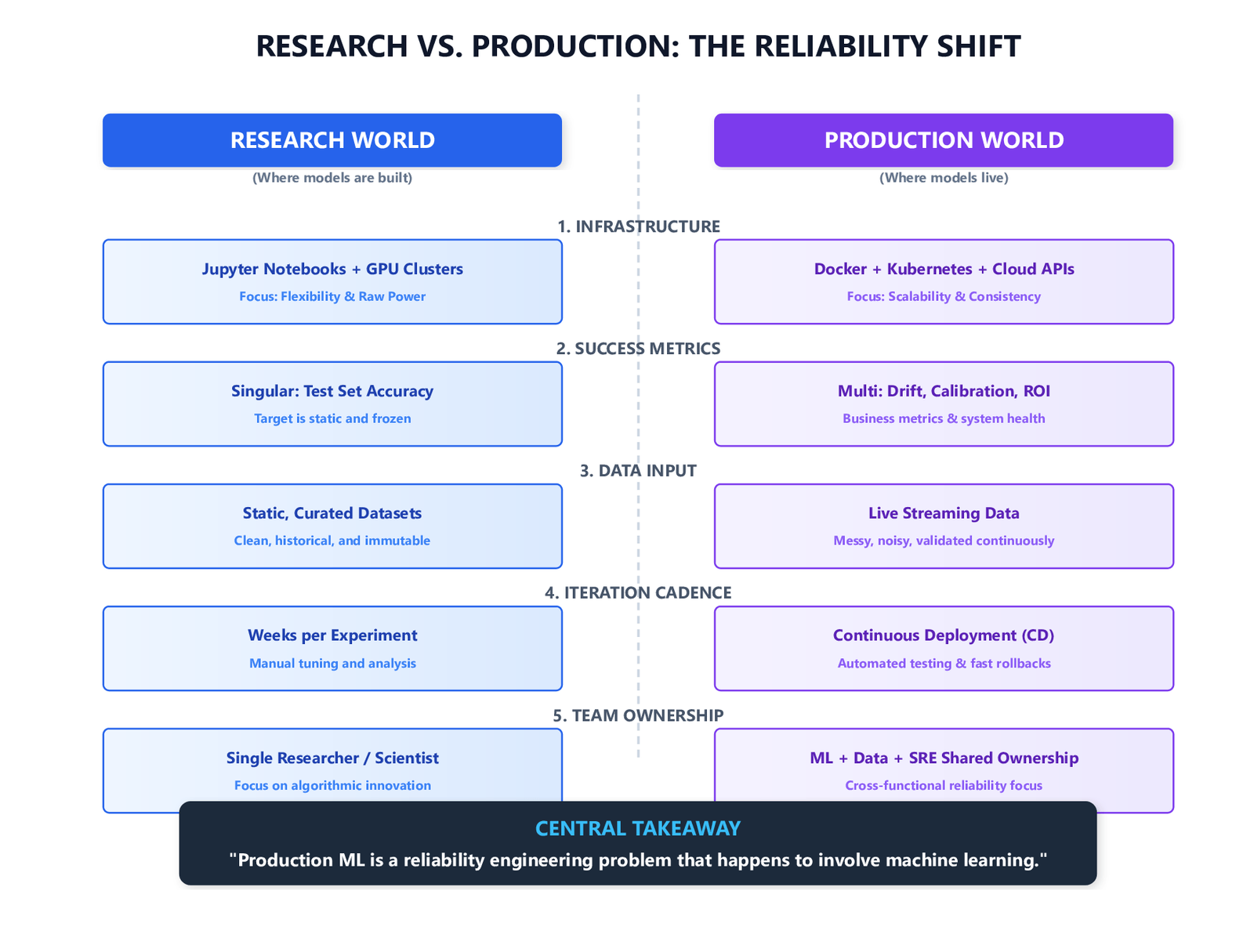
One of the most persistent failure modes in production ML is applying research instincts to a production problem. The tools, constraints, and objectives are fundamentally different.
| Dimension | Research Infrastructure | Production Infrastructure |
|---|---|---|
| Primary goal | Maximise model performance on benchmark | Maximise reliability, correctness, and uptime |
| Iteration cycle | Weeks to months per experiment | Continuous deployment |
| Data | Static, curated, versioned once | Streaming, evolving, validated continuously |
| Failure mode | Wrong results on test set | Silent degradation, serving errors, data corruption |
| Reproducibility | “I can rerun this notebook” | “Any engineer can reproduce any artifact from version control” |
| Monitoring | Training loss curves | Prediction drift, feature drift, business metrics |
| Rollback | Revert a git commit | Route traffic away from a bad model version within seconds |
| Latency | Not a constraint | Hard SLA — often < 100ms p99 |
| Compliance | Usually not a concern | Data lineage, model explainability, audit trails |
Key Insight: Production ML borrows heavily from Site Reliability Engineering. Concepts like error budgets, runbooks, on-call rotations, and incident post-mortems are as relevant to a production ML system as to any other production service.
How to Use This Series
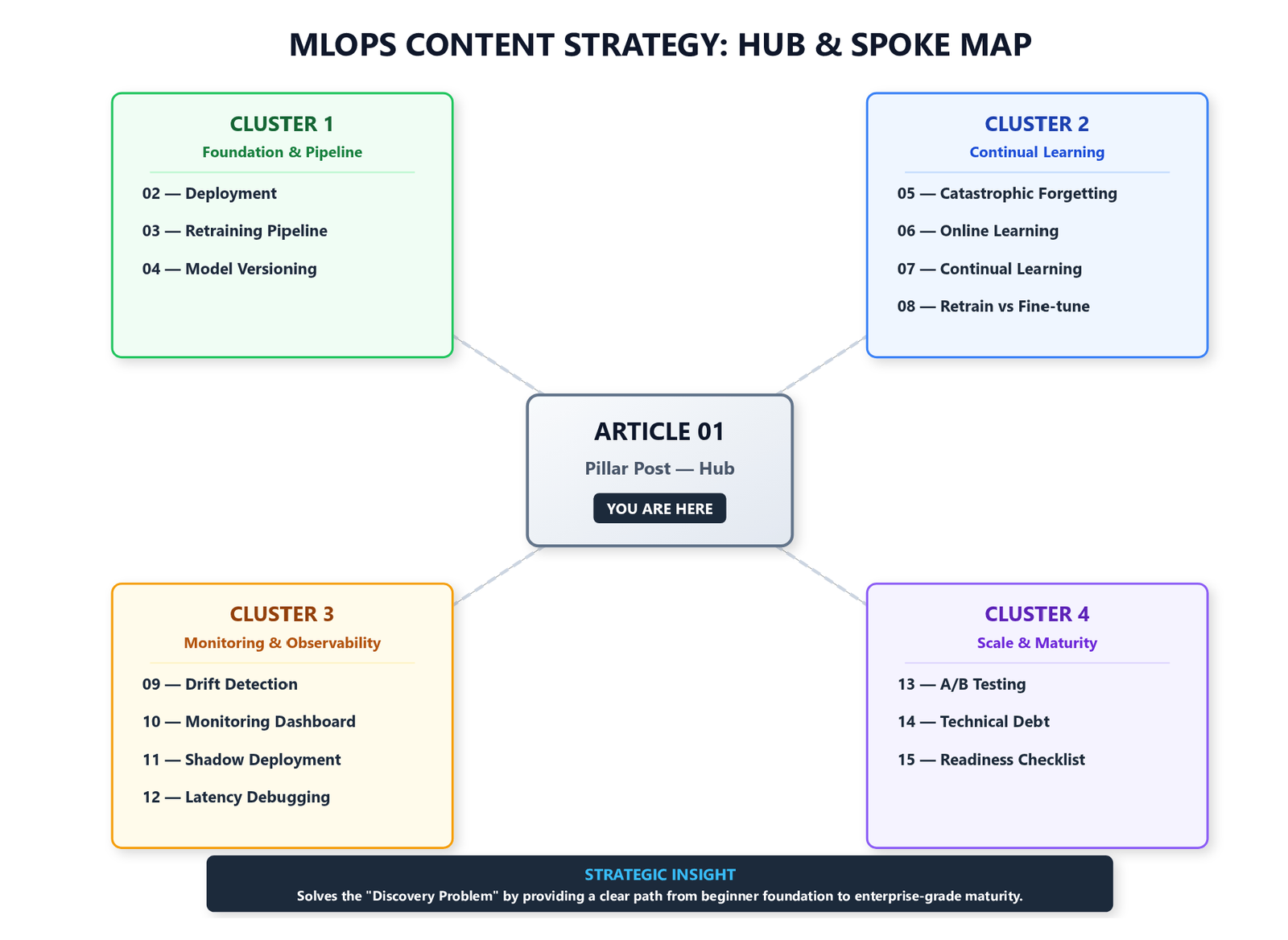
This series follows a pillar-and-cluster structure. This article is the hub. Each of the 14 articles below is a standalone deep-dive that expands on one component of the system described here.
If you are just starting out: Begin with Article 02 (deployment) and Article 03 (retraining pipelines). These give you the operational foundation everything else builds on.
If your models are deployed but degrading: Go directly to Article 09 (drift monitoring) and Article 05 (catastrophic forgetting). These address the most common causes of production degradation.
If you are auditing an existing system: Start with Article 15 (production readiness checklist) and Article 14 (ML technical debt). Both are designed as diagnostic frameworks rather than tutorials.
Cluster 1 — Foundation & Pipeline
| # | Article | What You Will Learn |
|---|---|---|
| 02 | How to Deploy a Machine Learning Model to Production | Containerisation, FastAPI serving, CI/CD for ML, cloud deployment |
| 03 | How to Build an ML Retraining Pipeline That Won’t Break in Production | Trigger strategies, pipeline orchestration, Airflow vs Prefect vs Kubeflow |
| 04 | ML Model Versioning: How to Track, Roll Back, and Manage Models in Production | Model registries, MLflow, DVC, rollback under 5 minutes |
Cluster 2 — Continual Learning
| # | Article | What You Will Learn |
|---|---|---|
| 05 | How to Prevent Catastrophic Forgetting in PyTorch | EWC, experience replay, PackNet — benchmarked head-to-head |
| 06 | Online Learning in Python: How to Train Models on Streaming Data | River library, SGD, concept drift handling, evaluation strategies |
| 07 | Continual Learning in PyTorch: A Practical Guide | Task/domain/class-incremental learning, progressive neural networks |
| 08 | Retrain vs Fine-Tune vs Train from Scratch: A Decision Framework | Decision tree, transfer learning vs continual learning, industry heuristics |
Cluster 3 — Monitoring & Observability
| # | Article | What You Will Learn |
|---|---|---|
| 09 | ML Model Monitoring: How to Detect Data Drift and Model Decay | KS test, PSI, MMD, Evidently AI tutorial, Grafana integration |
| 10 | How to Build an ML Monitoring Dashboard from Scratch | Prediction logging, drift visualisation, Slack and email alerts |
| 11 | Shadow Deployment and Canary Testing for ML Models | Shadow mode vs A/B testing vs canary, Seldon Core, traffic splitting |
| 12 | How to Debug Latency and Throughput Issues in ML Inference | PyTorch Profiler, quantisation, ONNX, load balancing strategies |
Cluster 4 — Scale & Maturity
| # | Article | What You Will Learn |
|---|---|---|
| 13 | How to A/B Test Machine Learning Models the Right Way | Experiment design, statistical significance, multi-metric evaluation |
| 14 | ML Technical Debt: How to Identify, Measure, and Pay It Down | Google’s 8 debt types, system audit, scoring framework, safe refactoring |
| 15 | ML Production Readiness Checklist: 50 Things to Verify Before You Ship | 50-item checklist across data, model, deployment, monitoring, and team |
Tools and Stack Overview
The tables below map each pillar to the tools most commonly used in production environments. The right choice depends on your team’s size, cloud provider, and scale requirements.

Data & Feature Layer
| Tool | Category | Best For |
|---|---|---|
| DVC [4] | Data versioning | Git-like versioning for datasets and models |
| Great Expectations [8] | Data validation | Schema and distribution validation with HTML reports |
| Feast [9] | Feature store | Open-source, works with Redis and BigQuery |
| Tecton [10] | Feature store | Managed, enterprise-grade, strong SLA guarantees |
| Delta Lake [5] | Data storage | ACID-compliant data lake with time travel |
Training & Experiment Layer
| Tool | Category | Best For |
|---|---|---|
| MLflow [12] | Experiment tracking + registry | Open-source, self-hosted, broad framework support |
| Weights & Biases [13] | Experiment tracking | Rich visualisations, collaboration features, sweeps |
| DVC Pipelines [4] | Pipeline orchestration | Lightweight, Git-native ML pipelines |
| Kubeflow Pipelines [23] | Pipeline orchestration | Kubernetes-native, enterprise scale |
| Prefect [24] | Workflow orchestration | Developer-friendly, hybrid cloud |
Serving & Deployment Layer
| Tool | Category | Best For |
|---|---|---|
| FastAPI [15] | API serving | Fast, Pythonic, automatic documentation |
| BentoML [16] | ML serving framework | Multi-framework, built-in batching and runner support |
| Seldon Core [17] | Kubernetes-native serving | Advanced routing, canary deployments, explainability |
| ONNX Runtime [25] | Inference optimisation | Cross-framework, optimised inference |
| TorchServe [26] | PyTorch serving | Official PyTorch serving solution, handler-based |
Monitoring & Observability Layer
| Tool | Category | Best For |
|---|---|---|
| Evidently AI [27] | ML monitoring | Open-source, pre-built drift reports |
| Grafana + Prometheus [28][29] | Infrastructure monitoring | General-purpose, ML metrics dashboards |
| whylogs / WhyLabs [30] | Data logging | Lightweight statistical profiling at inference time |
| Arize AI [31] | ML observability | Managed, strong root-cause analysis tooling |
| Streamlit [32] | Dashboard development | Rapid custom dashboard development in Python |
Continual Learning Layer
| Tool | Category | Best For |
|---|---|---|
| River [33] | Online ML library | Native online learning algorithms, streaming-first |
| Avalanche [34] | Continual learning research | PyTorch-based, all major CL strategies implemented |
| PyTorch [35] | Deep learning framework | EWC, experience replay, custom CL implementations |
Conclusion
Production ML engineering is not a single skill. It is a system of interconnected practices that together determine whether a machine learning model delivers lasting value in the real world.
The five pillars — reliable data pipelines, reproducible training, robust deployment, continuous monitoring, and continual learning — are not optional features you add when you have time. They are the minimum viable foundation of a system that can be trusted, debugged, improved, and operated safely over time. Skip any one and you have built something that will eventually fail in a way that surprises you, even if it does not surprise anyone who has seen this pattern before.
Teams that succeed at production ML treat it like any other reliability engineering challenge: they define failure modes before they ship, they instrument everything early, they build rollback paths before they need them, and they accept that a deployed model is a living system requiring ongoing attention — not a milestone to be shipped and forgotten.
The remaining 14 articles in this series go deep on each of these areas. Start wherever your current system is weakest.
References
[1] Gartner. (2022). Top Strategic Technology Trends for 2022. Gartner Research. Press release: https://www.gartner.com/en/newsroom/press-releases/2021-10-18-gartner-identifies-the-top-strategic-technology-trends-for-2022 (Full report available to Gartner subscribers at gartner.com/en/documents/4006913)
[2] VentureBeat. (2019). Why do 87% of data science projects never make it into production? VentureBeat. https://venturebeat.com/technology/why-do-87-of-data-science-projects-never-make-it-into-production (Note: This figure originates from a 2019 practitioner panel at VentureBeat Transform and is widely cited as a directional estimate, not a formally peer-reviewed statistic.)
[3] Sculley, D., Holt, G., Golovin, D., Davydov, E., Phillips, T., Ebner, D., Chaudhary, V., Young, M., Crespo, J.-F., & Dennison, D. (2015). Hidden technical debt in machine learning systems. Advances in Neural Information Processing Systems (NeurIPS), 28. https://proceedings.neurips.cc/paper_files/paper/2015/hash/86df7dcfd896fcaf2674f757a2463eba-Abstract.html
[4] Iterative AI. (2024). DVC: Data Version Control. https://dvc.org
[5] Databricks. (2024). Delta Lake: Open-source storage layer. Linux Foundation Project. https://delta.io
[6] Treeverse. (2024). lakeFS: Data version control for data lakes. https://lakefs.io
[7] Baylor, D., Breck, E., Cheng, H.-T., et al. (2017). TFX: A TensorFlow-based production-scale machine learning platform. Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining. https://doi.org/10.1145/3097983.3098021
[8] Superconductive Health. (2024). Great Expectations: Data quality and documentation framework. https://greatexpectations.io
[9] Feast Authors. (2024). Feast: Open-source feature store for machine learning. Linux Foundation AI Project. https://feast.dev
[10] Tecton. (2024). Tecton: The enterprise feature store. https://www.tecton.ai
[11] Hopsworks. (2024). Hopsworks: The Python-centric feature store. https://www.hopsworks.ai
[12] Zaharia, M., Chen, A., Davidson, A., et al. (2018). Accelerating the machine learning lifecycle with MLflow. IEEE Data Engineering Bulletin, 41(4), 39–45. https://people.eecs.berkeley.edu/~matei/papers/2018/ieee_mlflow.pdf
[13] Biewald, L. (2020). Experiment tracking with Weights and Biases. https://www.wandb.com
[14] PyTorch Documentation. (2024). Reproducibility. https://pytorch.org/docs/stable/notes/randomness.html
[15] Ramírez, S. (2024). FastAPI: Modern, fast web framework for building APIs with Python. https://fastapi.tiangolo.com
[16] BentoML Team. (2024). BentoML: Build production-ready AI applications. https://bentoml.com
[17] Seldon Technologies. (2024). Seldon Core: Machine learning deployment for Kubernetes. https://www.seldon.io/solutions/seldon-core
[18] Massey, F. J. (1951). The Kolmogorov-Smirnov test for goodness of fit. Journal of the American Statistical Association, 46(253), 68–78. https://doi.org/10.2307/2280095
[19] Yurdakul, B. (2018). Statistical properties of population stability index. Western Michigan University Dissertations. 3208. https://scholarworks.wmich.edu/dissertations/3208
[20] Gretton, A., Borgwardt, K. M., Rasch, M. J., Schölkopf, B., & Smola, A. (2012). A kernel two-sample test. Journal of Machine Learning Research, 13(25), 723–773. https://jmlr.csail.mit.edu/papers/v13/gretton12a.html
[21] Kirkpatrick, J., Pascanu, R., Rabinowitz, N., et al. (2017). Overcoming catastrophic forgetting in neural networks. Proceedings of the National Academy of Sciences, 114(13), 3521–3526. https://doi.org/10.1073/pnas.1611835114
[22] Rusu, A. A., Rabinowitz, N. C., Desjardins, G., et al. (2016). Progressive neural networks. arXiv preprint arXiv:1606.04671. https://arxiv.org/abs/1606.04671
[23] Kubeflow Authors. (2024). Kubeflow Pipelines: ML workflow orchestration on Kubernetes. https://www.kubeflow.org/docs/components/pipelines/
[24] Prefect Technologies. (2024). Prefect: Modern workflow orchestration. https://www.prefect.io
[25] Microsoft & ONNX Authors. (2024). ONNX Runtime: Cross-platform inference engine. https://onnxruntime.ai
[26] PyTorch Authors. (2024). TorchServe: A flexible and easy-to-use tool for serving PyTorch models. https://pytorch.org/serve/
[27] Evidently AI. (2024). Evidently: Open-source ML monitoring and testing. https://www.evidentlyai.com
[28] Grafana Labs. (2024). Grafana: Open-source observability platform. https://grafana.com
[29] Prometheus Authors. (2024). Prometheus: Monitoring system and time series database. Cloud Native Computing Foundation. https://prometheus.io
[30] WhyLabs. (2024). whylogs: Open-standard data logging library. https://whylogs.readthedocs.io
[31] Arize AI. (2024). Arize AI: ML observability platform. https://arize.com
[32] Streamlit Inc. (2024). Streamlit: Fastest way to build ML data apps. https://streamlit.io
[33] Montiel, J., Halford, M., Mastelini, S. M., et al. (2021). River: Machine learning for streaming data in Python. Journal of Machine Learning Research, 22(110), 1–8. https://jmlr.org/papers/v22/20-1380.html
[34] Lomonaco, V., Pellegrini, L., Cossu, A., et al. (2021). Avalanche: An end-to-end library for continual learning. Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), 3595–3605. https://doi.org/10.1109/CVPRW53098.2021.00399
[35] Paszke, A., Gross, S., Massa, F., et al. (2019). PyTorch: An imperative style, high-performance deep learning library. Advances in Neural Information Processing Systems (NeurIPS), 32. https://proceedings.neurips.cc/paper/2019/hash/bdbca288fee7f92f2bfa9f7012727740-Abstract.html

")




Leave a Reply