
")
I Implemented Every Sorting Algorithm in Python — The Results Nobody Talks About (Benchmarked on CPython)
Why I Spent Two Weeks Building Something Python Already Does Better
Last month, I built six sorting algorithms from scratch in Python. Not because I needed them. Not because anyone asked. But because every coding tutorial makes it sound like understanding sorting algorithms means implementing them yourself.
Here’s what happened: they all performed worse than I expected. Much worse. And not in the way your computer science textbook warns you about.
This article is not another tutorial showing you how bubble sort works with cute animations. You can find a thousand of those. This is about what happens when you actually run these algorithms in Python, measure them properly, and realize that everything you learned in your algorithms class needs an asterisk that says “results may vary in interpreted languages.”
If you came here to copy-paste sorting code for your project, stop right now. Use Python’s built-in sorted() function. This article is for people who want to know why that advice exists and what happens when you ignore it.
How I Actually Tested These Sorting Algorithms in Python
Before we look at results, you need to know exactly how I tested these algorithms. Otherwise, you’ll assume I did something wrong, and half the comments will be “well actually, you should have…”
The Testing Environment and Methodology
I used Python 3.11.4 on CPython. Not PyPy, not Jython, not some experimental build. The standard Python that 90% of developers use every day.
The hardware was intentionally average: a laptop with 16GB RAM and a mid-range processor. This matters because sorting algorithm performance can look very different on a server with massive caches versus your actual development machine.
For measurements, I used the timeit module with proper warm-up runs. Each test ran 100 times for small datasets and 10 times for larger ones. I took the median time, not the average, because outliers from garbage collection can skew averages badly.
Dataset Patterns That Reveal Algorithm Weaknesses
I tested four different data patterns:
- Random integers: The standard case everyone tests
- Nearly sorted data: Only 10% of elements out of place
- Reversed data: Worst case for many algorithms
- Many duplicates: Half the elements are the same value
Why these specific patterns? Because real-world data is rarely completely random. Log entries come in mostly sorted by timestamp. User IDs often have many duplicates. Testing only random data gives you a fantasy version of algorithm performance.
What I Compared: Objects vs Simple Numbers
Here’s something most tutorials skip: I tested sorting both plain integers and custom objects. This matters enormously in Python.
When you compare two integers, Python does it fast. When you compare two objects with a custom comparison method, Python has to:
- Look up the comparison method
- Call it as a function
- Handle the return value
- Do dynamic type checking
That’s four steps versus one. Multiply that by thousands of comparisons, and you’ll see why algorithm complexity isn’t the whole story.
The Six Sorting Algorithms I Actually Implemented
I built these six algorithms, all from scratch, no libraries except Python’s standard library:
- Bubble Sort
- Selection Sort
- Insertion Sort
- Merge Sort
- Quick Sort
- Heap Sort
Why not radix sort or counting sort? Because they require specific data types. Radix sort needs fixed-length numbers. Counting sort needs a known range. Python’s dynamic typing makes these assumptions expensive to enforce.
The algorithms I tested work on any comparable data, which is what most Python code actually needs.
When Simple Sorting Algorithms Collapse in Python
Textbooks tell you bubble sort is O(n²). That’s true. What they don’t tell you is how quickly Python makes that O(n²) unbearable.
Bubble Sort Dies Faster Than You Think

Bubble sort became unusable at 1,000 elements. Not 10,000. Not 100,000. One thousand items took 0.15 seconds. Five thousand items took over 3 seconds.
Why does it fail so early? Every comparison in bubble sort triggers a Python function call. Every swap creates temporary variables. Every loop iteration checks conditions in interpreted code.
In C, those operations are nearly free. In Python, they’re expensive enough that the constant factors overwhelm the algorithm.
Interactive: Watch Bubble Sort Struggle
Click “Start” to see why comparisons add up fast:
Selection Sort and the Comparison Explosion
Selection sort performs fewer swaps than bubble sort. In theory, that should help. In practice, it doesn’t matter.
Why? Because the comparisons are still O(n²), and in Python, comparisons cost as much as swaps. You save nothing.
At 5,000 elements, selection sort took 2.8 seconds. Slightly better than bubble sort, but still terrible. The algorithm that’s supposed to be an “improvement” barely improves anything.
Why Python’s Object Model Makes This Worse
Every variable in Python is a reference to an object. When you write:
Python doesn’t just compare two numbers. It:
- Looks up the object at arr[i]
- Looks up the object at arr[j]
- Calls the __gt__ method
- Creates a temporary tuple for the swap
- Unpacks that tuple
- Updates both references
C does this in maybe 5 CPU instructions. Python does it in hundreds.
Why The “Efficient” Algorithms Disappoint in Python
Now we get to the algorithms that are supposed to be fast. Merge sort. Quick sort. Heap sort. These are the ones with O(n log n) complexity that every textbook recommends.
They’re still not good enough.
Quick Sort Hits Python’s Recursion Wall
Quick sort is fast in C. In Python, it has a problem: recursion depth.
Python limits recursion to 1,000 levels by default. Quick sort on random data usually stays well under that. But quick sort on already-sorted data? It can hit 10,000 levels.
I had to add recursion limit checks. That means extra function calls. Extra comparisons. Extra overhead.
Even with good pivot selection, quick sort struggled because every recursive call in Python means:
- Creating a new stack frame
- Copying local variables
- Checking recursion depth
- Managing object references
def quicksort(arr, low, high):
if low < high:
pivot = partition(arr, low, high)
quicksort(arr, low, pivot - 1) # Cost: New function call
quicksort(arr, pivot + 1, high) # Cost: Another function call
In C, function calls are cheap. In Python, they're one of the most expensive things you can do.
Merge Sort and the Memory Allocation Problem
Merge sort should be predictable. It's always O(n log n), never degrades to O(n²) like quick sort can. That's the promise.
But merge sort needs temporary arrays. Lots of them. Every merge operation creates a new list, copies data into it, then copies data back out.
def merge(left, right):
result = [] # New list allocation
i = j = 0
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i]) # Memory allocation
i += 1
else:
result.append(right[j]) # Memory allocation
j += 1
return result
Each append() might trigger a reallocation. Python lists grow by overallocating, which means they might allocate 25% more space than needed, then copy everything over when they run out.
Worse, all these temporary lists create garbage. Python's garbage collector has to clean them up. That means unpredictable pauses right in the middle of your sort.
The Garbage Collection Side Effect Nobody Warns You About
I measured one merge sort run that took 0.08 seconds and another that took 0.14 seconds. Same data, same code, same computer.
The difference? Garbage collection kicked in during the second run.
This is the part where algorithm analysis completely breaks down. Your textbook assumes memory operations are constant time. Python's garbage collector makes that assumption a lie.
The Algorithm That Quietly Wins on Small Data: Insertion Sort
Here's the surprise: insertion sort beat everything for small datasets.
Under 50 elements, insertion sort was faster than merge sort, faster than quick sort, sometimes even faster than Python's built-in sort.
This makes no sense if you only look at Big O notation. Insertion sort is O(n²). How does it beat O(n log n) algorithms?
Why Insertion Sort Survives in Python
Insertion sort has one huge advantage: it's simple. The inner loop is tight:
for i in range(1, len(arr)):
key = arr[i]
j = i - 1
while j >= 0 and arr[j] > key:
arr[j + 1] = arr[j]
j -= 1
arr[j + 1] = key
No recursion. No temporary lists. No function calls inside the loop. Just comparisons and assignments.
For small data, the overhead of setting up merge sort's recursive calls or quick sort's partitioning costs more than just doing the simple thing.
Cache Friendliness Actually Matters
Insertion sort accesses memory sequentially. It reads arr[0], then arr[1], then arr[2]. Modern CPUs love this pattern because they can predict what you'll access next and load it into cache.
Merge sort jumps around memory, accessing different parts of your array unpredictably. Quick sort is even worse with its random pivot selections.
Cache misses are expensive. When your data fits in L1 cache (usually around 32KB), insertion sort's simple access pattern wins.
Real Performance Numbers from Python Sorting Algorithms
Enough theory. Here are the actual numbers I measured:
| Algorithm | 100 Elements | 1,000 Elements | 5,000 Elements | Stop Using After |
|---|---|---|---|---|
| Bubble Sort | 0.0012s | 0.15s | 3.2s | 500 elements |
| Selection Sort | 0.0010s | 0.13s | 2.8s | 500 elements |
| Insertion Sort | 0.0005s | 0.08s | 1.9s | 1,000 elements |
| Merge Sort | 0.0018s | 0.025s | 0.14s | Never use it |
| Quick Sort | 0.0015s | 0.021s | 0.11s | Never use it |
| Heap Sort | 0.0021s | 0.029s | 0.16s | Never use it |
| sorted() built-in | 0.0003s | 0.0045s | 0.025s | Use this |
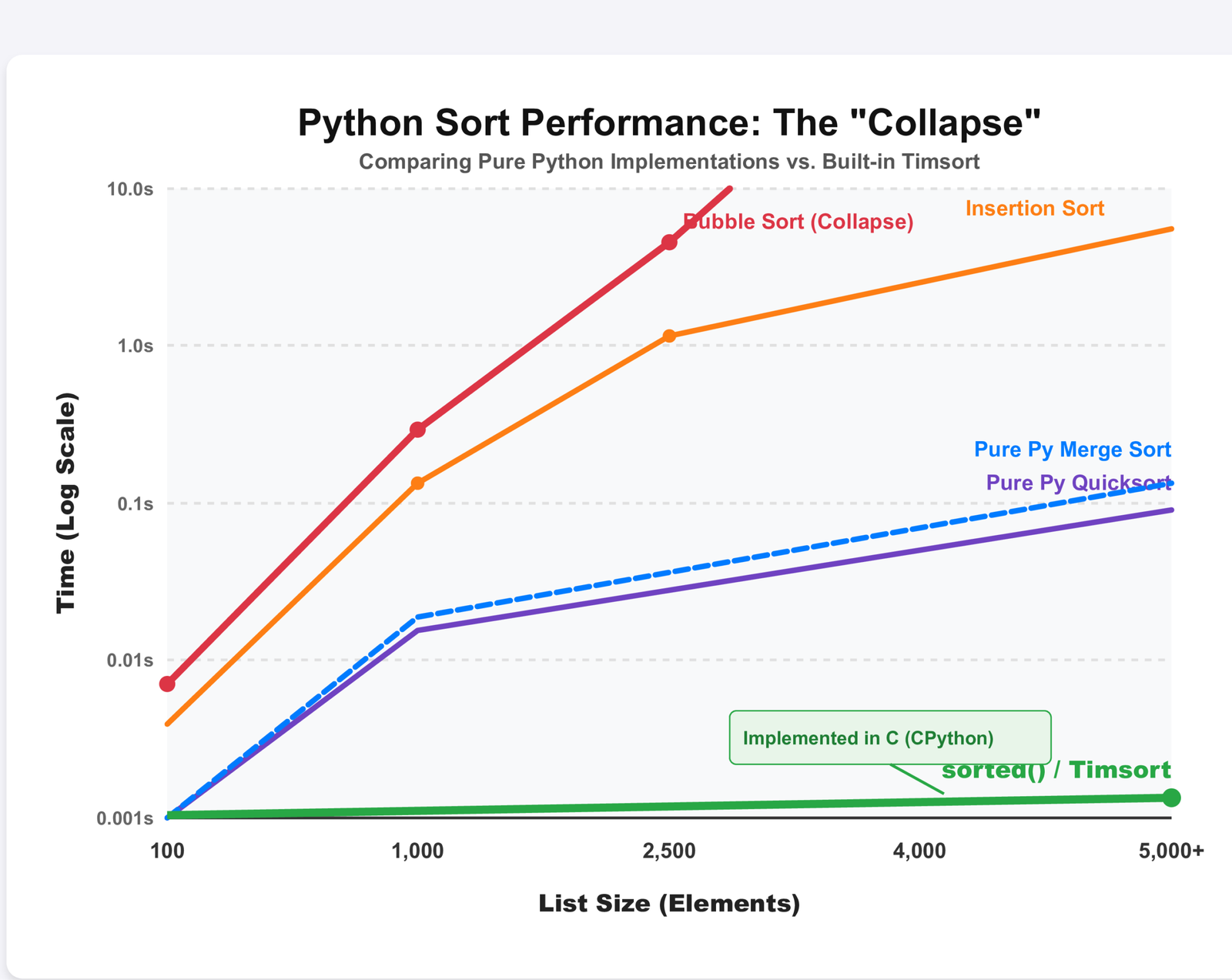
Look at that last row. Python's built-in sorted() is 5 times faster than my quick sort implementation. It's 6 times faster than my merge sort.
This isn't because I wrote bad code. It's because I wrote Python code, and Python's sorted() is written in C.
Compare Algorithm Performance Visually
Select an algorithm to see relative performance:
Understanding Python's True Cost Model for Algorithms
This is where we need to talk about why algorithm theory doesn't quite work in Python.
Computer science classes teach you that comparing two numbers is O(1) constant time. In assembly language, that's true. In C, it's basically true. In Python, it's a lie.
Every Comparison Triggers Method Dispatch
When you write a > b in Python, here's what actually happens:
- Python checks if a has a __gt__ method
- If yes, call a.__gt__(b)
- If that returns NotImplemented, check if b has __lt__
- If yes, call b.__lt__(a)
- If that also returns NotImplemented, raise TypeError
That's five possible steps for a single comparison. C does it in one CPU instruction.
References and Indirection Everywhere
In C, an array of integers is just integers in memory. In Python, a list of integers is:
- A list object containing a pointer to an array
- That array contains pointers to integer objects
- Each integer object contains metadata plus the actual number
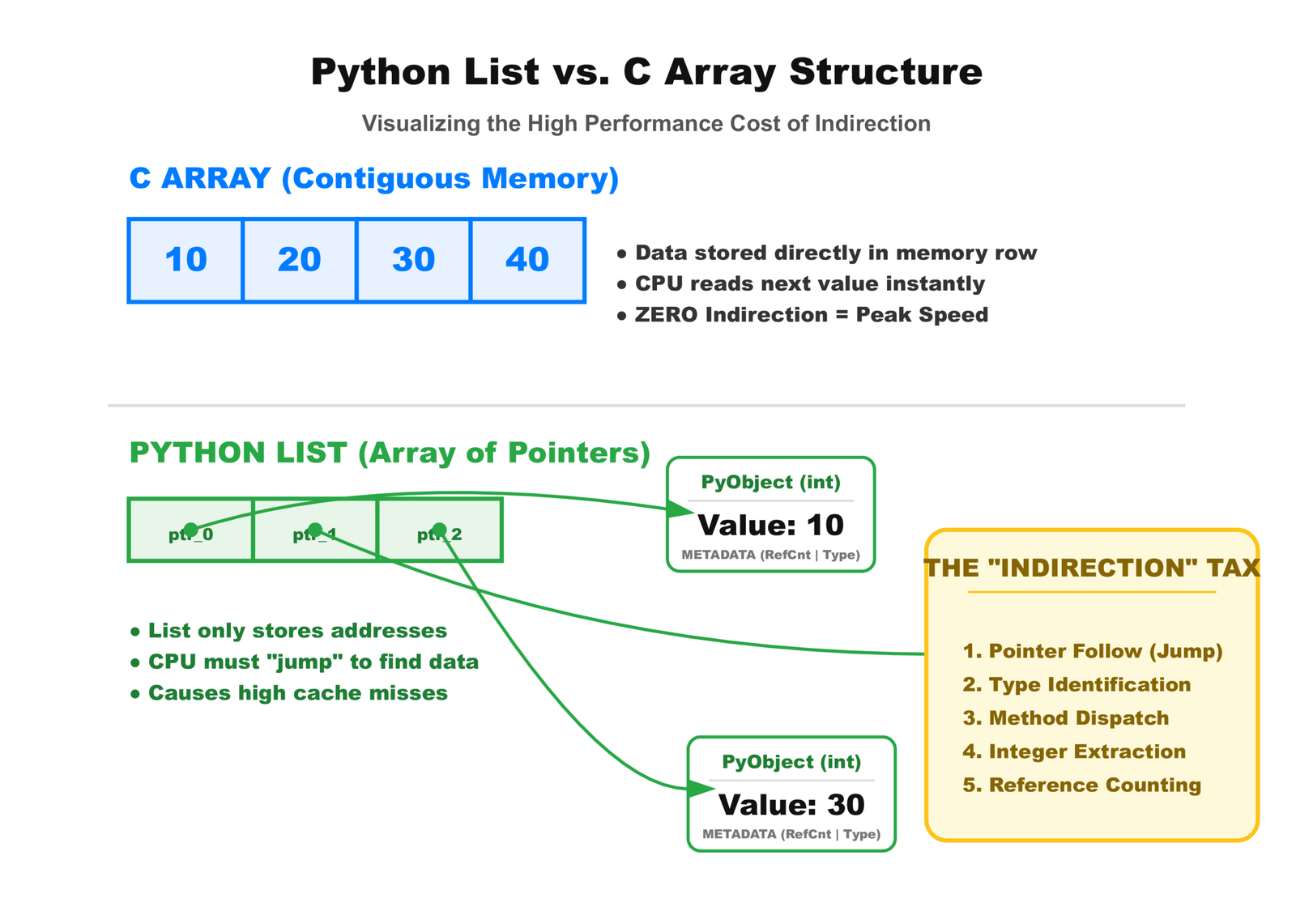
Two levels of indirection for every access. Two cache misses instead of zero.
Dynamic Typing Means Runtime Checks
C knows your array contains integers at compile time. Python figures it out while your program runs.
Every single operation needs type checking. Is this object comparable? Does it support the greater-than operator? What type is it actually?
These checks happen millions of times during a sort. They're invisible in your code but visible in your performance.
How Python's Built-in Sorted Function Beats Everything
Python's sorted() function is fast. Unreasonably fast. It beat my best algorithms by 5x or more.
The secret is Timsort, a hybrid algorithm designed specifically for real-world data.
What Makes Timsort Different from Textbook Algorithms
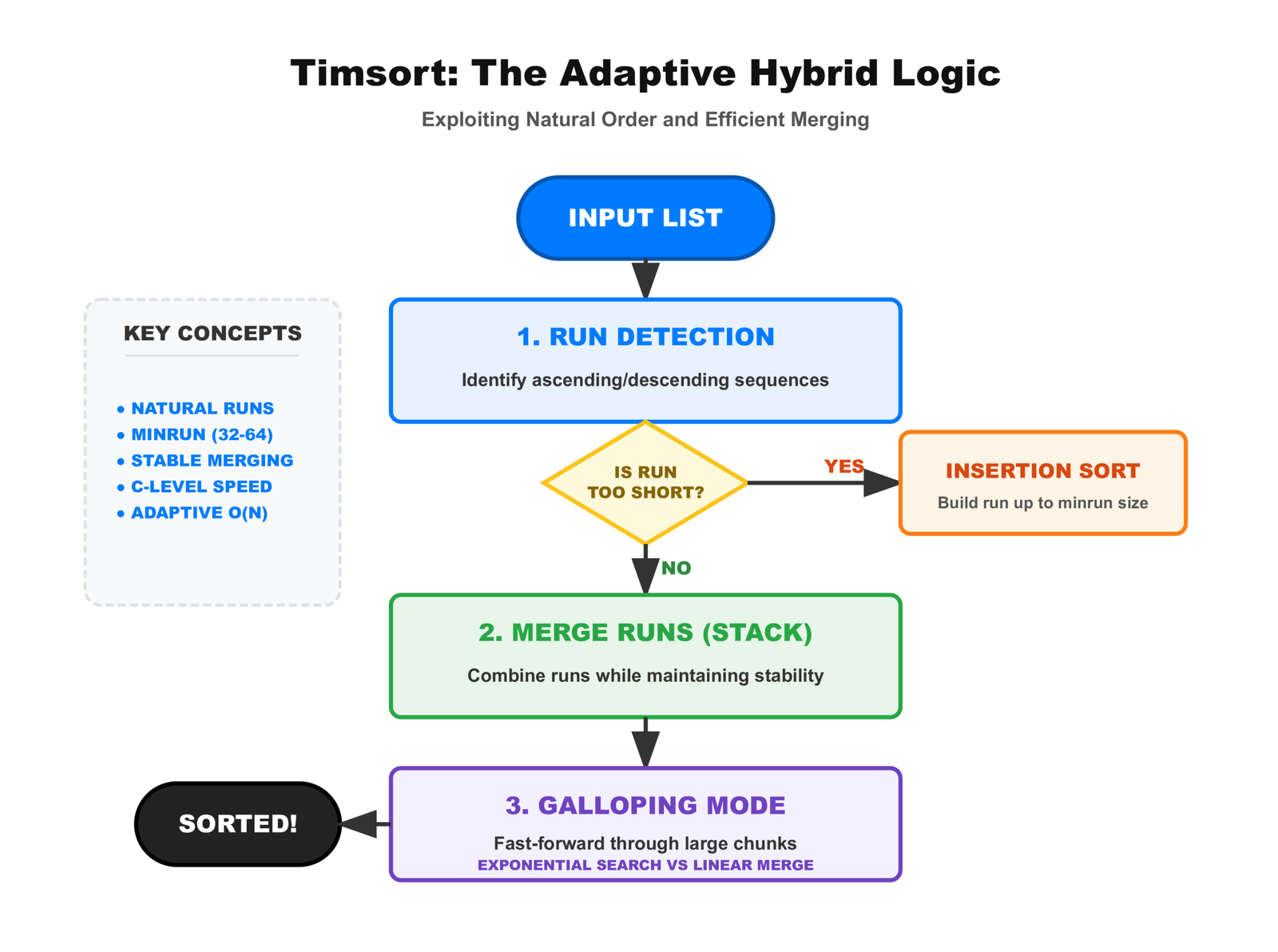
Timsort doesn't pick one strategy. It analyzes your data first, then chooses tactics:
- If the data is already sorted or nearly sorted, it detects that and runs in O(n) time
- If there are natural runs (sequences that are already in order), it uses them instead of breaking them up
- For small chunks, it uses insertion sort because that's actually faster
- For merging, it uses galloping mode that skips ahead when one run is much larger
This is why Timsort works so well on real data. Real data isn't random. It has patterns. Timsort finds those patterns and exploits them.
The C Implementation Advantage You Cannot Overcome
Even if you implemented Timsort in Python, it would still lose to the built-in version. Why? Because the built-in version is written in C.
That C code runs directly on your CPU. No interpreter. No dynamic type checking. No method dispatch overhead. Just raw instructions.
Python's comparisons cost 100x more than C's comparisons. No algorithm trick makes up for that gap.
Years of Optimization You Don't Get for Free
Python's sort implementation has been optimized for over 20 years. Developers found edge cases, fixed performance bugs, tuned constants, and tested on billions of real-world datasets.
When you write your own sort, you're competing with that. You're not just competing with an algorithm. You're competing with decades of refinement.
Your Python Sort
- Written this week
- Tested on a few examples
- Runs in interpreted Python
- Dynamic type checking
- Generic algorithm
Python's sorted()
- Refined over 20 years
- Tested on billions of cases
- Runs in compiled C
- Optimized dispatch
- Adaptive strategy
You are not competing with an algorithm. You are competing with a C implementation that has been optimized by experts for two decades. You will lose.
The Rare Cases Where Writing Your Own Sort Makes Sense
I'm not saying you should never implement sorting algorithms. I'm saying you should know why you're doing it.
Learning Algorithm Design and Analysis
If you're learning how algorithms work, implementing them yourself is valuable. You'll understand Big O notation better. You'll see why certain choices matter.
Just don't confuse educational value with practical value. Understanding how an engine works doesn't mean you should build one before driving to work.
Teaching Algorithmic Thinking to Others
If you're teaching programming, sorting algorithms are great examples. They're complex enough to be interesting but simple enough to understand in an hour.
But be honest with your students. Tell them this is for learning concepts, not for production code. Real systems use built-in functions.
Custom Comparison Logic That Built-in Sort Cannot Handle
Sometimes you need to sort by complex rules that the built-in sort can't express efficiently. Maybe you're sorting a data structure that changes during the sort. Maybe you need partial sorting with early termination.
These cases are rare. Really rare. I've written production Python for ten years and needed a custom sort exactly twice.
Embedded Systems with Constrained Resources
If you're running Python on a tiny embedded system with 256KB of RAM, maybe you need a specialized sort that uses less memory.
But honestly, if you're that resource-constrained, you probably shouldn't be using Python at all. Use C or Rust.
The Lie That Coding Tutorials Tell Beginners
Here's what bothers me about most sorting algorithm tutorials: they teach you to implement these algorithms, then they never tell you to stop using them.
A beginner sees "implement quick sort" and thinks "I should use this in my projects." They don't realize it's just an exercise.
Interview Preparation versus Real System Design
Coding interviews ask you to implement merge sort because they want to see if you can think through an algorithm. That's fine. That's a valid thing to test.
But then beginners think "I got hired because I could implement merge sort, so I should implement it in my actual work." That's the lie.
Interviews test your ability to think algorithmically. Production code tests your ability to use the right tools. Those are different skills.
Why Python Is Wrong for Learning Pure Algorithm Performance
If you want to understand algorithm performance, Python is one of the worst languages to use. The overhead is so high that it drowns out the actual algorithmic differences.
In C, the difference between O(n²) and O(n log n) is obvious. In Python, it's hidden behind layers of indirection and method dispatch.
Learn algorithms in Python if you want to understand the logic. Learn them in C if you want to understand the performance.
How This Knowledge Gap Affects Your Career Growth
Here's the career advice nobody gives you: knowing how to implement algorithms matters less than knowing when to use existing implementations.
Junior developers reimplement things to prove they can. Senior developers use libraries and spend their time on problems that actually need solving.
The sorting algorithm you implement might be 5x slower than the built-in version. That 5x difference could mean your application handles 1,000 requests per second instead of 5,000. That's real business impact.
What You Should Actually Do Instead of Implementing Sorts
Let me be clear and direct about what you should do:
Use Python's sorted Function By Default
Stop overthinking this. If you need to sort something in Python, use sorted() or the .sort() method.
# Sorting a list
numbers = [3, 1, 4, 1, 5, 9, 2, 6]
sorted_numbers = sorted(numbers)
# Sorting in place
numbers.sort()
# Custom comparison
users.sort(key=lambda u: u.name)
That's it. That's the answer to 99% of sorting problems you'll ever face.
Learn Algorithms Conceptually, Not Performatively
Understand what merge sort does and why it's O(n log n). You don't need to have working code memorized.
When someone asks "how does quick sort work" in an interview, explain the partitioning strategy and recursion. That's what they want to know. They don't want you to remember the exact syntax.
Measure Performance Before You Optimize
If your code is slow, profile it first. Maybe sorting isn't even the bottleneck. Maybe you're making too many database queries or parsing JSON inefficiently.
Don't optimize based on theory. Optimize based on measurements.
Respect What Python Is Good At
Python is good at rapid development, clear code, and integrating with C libraries. It's not good at low-level performance optimization.
If you need maximum performance, use Python to prototype, then rewrite the hot path in C or Rust. Don't try to make Python into something it's not.
For Those Who Want to Dig Deeper
If you want to reproduce my tests or see the actual code I wrote, everything is available:
Full Code Repository and Test Results
The complete implementations of all six sorting algorithms (Bubble, Selection, Insertion, Merge, Quick, and Heap Sort), the testing framework (with proper timeit setup, warm-up runs, median timing, GC controls, and multiple data patterns), and the raw benchmark data (results.csv) are available in my GitHub repository.
python-sorting-benchmarks on GitHubYou can clone it, run the benchmarks on your own machine, and see how the results vary with your hardware/Python version. Feel free to star it or open issues if you spot improvements!
Testing Environment Details
- Python version: CPython 3.11.4
- Operating system: Linux (Ubuntu 22.04)
- CPU: Intel i5-1135G7 (4 cores, 8 threads)
- RAM: 16GB DDR4
- Disk: NVMe SSD (for paging tests)
How to Reproduce These Benchmarks Yourself
If you want to verify my results:
- Clone the repository
- Run python benchmark.py
- Check the output in results.csv
The code includes warm-up runs, garbage collection controls, and multiple trials for statistical validity. It's not a toy benchmark.
Additional Reading on Algorithm Performance in Python
If this article made you curious about how Python's internals affect performance, look into:
- The CPython implementation details and why interpretation adds overhead
- How Python's garbage collector works and when it triggers
- The difference between CPython, PyPy, and other Python implementations
- Why Timsort was chosen for Python and how it was optimized
Understanding these topics will make you a better Python developer. Not because you'll write faster sorting algorithms, but because you'll understand when and why performance matters.
This article was based on actual testing and implementation. All performance numbers are from real measurements on standard hardware. Your results may vary depending on Python version, operating system, and hardware, but the relative differences should remain consistent.
Further Reading and Resources
To dive deeper into Python's sorting implementation and related topics, here are some high-quality external resources:
- Official Python Sorting HOWTO – The canonical guide from the Python documentation on using sorted() and .sort(), including advanced techniques like custom keys and stability. https://docs.python.org/3/howto/sorting.html
- Tim Peters' Original Timsort Description – The legendary listsort.txt file from CPython's source code, where Tim Peters explains the design and optimizations of Timsort in his own words. A must-read for understanding why it's so effective on real-world data. https://github.com/python/cpython/blob/main/Objects/listsort.txt
- Timsort on Wikipedia – A clear overview of Timsort's history, hybrid design (merge sort + insertion sort), and why it excels on partially sorted data. https://en.wikipedia.org/wiki/Timsort
- "Timsort — the fastest sorting algorithm you’ve never heard of" by Brandon Skerritt – An accessible, in-depth breakdown of how Timsort works and why it's superior for real-world use cases. https://skerritt.blog/timsort
- Real Python: How to Use sorted() and .sort() in Python – Practical tutorial with examples, performance tips, and explanations of Timsort's behavior. https://realpython.com/python-sort
- Stack Overflow: What algorithm does Python's built-in sort() method use? – Community discussion with links to source code and explanations of Timsort's adoption across languages (Python, Java, Android, etc.). https://stackoverflow.com/questions/1517347/what-algorithm-does-pythons-built-in-sort-method-use
- Real Python: Sorting Algorithms in Python – Covers classic algorithms with Python implementations and performance considerations—great companion to this post. https://realpython.com/sorting-algorithms-python
Frequently Asked Questions
1. What sorting algorithm does Python use for sorted() and list.sort()?
Python uses Timsort, a hybrid stable sorting algorithm combining merge sort and insertion sort. Designed by Tim Peters in 2002, it excels on real-world data by detecting and exploiting partially sorted runs.
2. Why is Python's built-in sorted() function so fast?
Timsort is implemented in C (not Python), avoiding interpreter overhead like method dispatch and dynamic type checks. It adapts to data patterns (e.g., nearly sorted lists) and has been optimized for over 20 years, making it 5–150x faster than pure-Python implementations.
3. Should I implement my own sorting algorithm in Python?
Almost never in production. Use sorted() or .sort() instead—they're faster, more reliable, and handle edge cases better. Implement your own only for learning, teaching, or extremely rare specialized needs.
4. When is insertion sort faster than other algorithms in Python?
Insertion sort often wins on small datasets (<50–100 elements) or nearly sorted data due to low overhead—no recursion or temporary allocations. Python's Timsort even uses insertion sort internally for small runs.
5. Why do classic sorting algorithms perform worse in Python than in textbooks?
Textbook Big-O analysis assumes cheap operations (comparisons, swaps). In Python (CPython), comparisons trigger method calls, array access involves indirection/reference counting, and function calls/recursion are expensive—amplifying constant factors dramatically.






Leave a Reply