
 Is Safer Than list.sort() in Production Python Systems")
Why sorted() Is Safer Than list.sort() in Production Python Systems
Why Python’s sorted() Is Safer Than list.sort() in Large-Scale Systems
- The mutation problem that breaks shared state
- What CPython does in memory during each operation
- The GIL and list.sort() — what the docs actually say
- The real concurrency risk with shared list mutation
- A production incident, step by step
- Why sorted() fits better in data pipelines
- Performance: when the difference matters and when it does not
- When sort() is actually the right choice
- 10-question quiz
- FAQ
- Further reading
Most Python tutorials cover this in one sentence: sort() modifies the list in place and returns None; sorted() returns a new sorted list. That is accurate. But it leaves out the part that actually matters when you are writing a backend service.
In a short script, the difference is cosmetic. In a service where functions share data — through caches, through parameters, through objects passed across layers — sort() creates a category of bug that is genuinely hard to find. Not because it is complicated, but because it does not crash. The data just looks slightly wrong, and you spend time looking in the wrong places.
This article works through the mechanics: what Python does in memory when you call each function, what the GIL actually protects (and a common misconception about it), and a realistic incident pattern that shows how a single .sort() call can quietly corrupt shared state for weeks.
The Mutation Problem — How list.sort() Changes Data You Did Not Mean to Change
When you call my_list.sort(), Python rearranges the elements inside that list object. Every other variable that points to the same object immediately reflects the new order. There is no copy involved, no warning, and nothing in the output to indicate that anything changed.
In practice, the problem usually starts with a variable assignment that looks harmless. You rename a variable, pass a list into a function, or store something in a cache — and somewhere down the line, a sort on one name silently reorders the data seen through all the others.
A simple example of the aliasing problem
# Both names point at the same list object in memory.
raw = [5, 2, 9, 1]
audit_log = raw
def process(order_ids):
order_ids.sort() # sorts in place — no copy made
return order_ids
result = process(raw)
print(audit_log) # [1, 2, 5, 9] — insertion order is gone
print(raw) # [1, 2, 5, 9] — same object, same result
The function sorted the caller’s list. audit_log still holds a reference to raw, so it also shows the sorted version. There was no crash, no exception — just missing data.
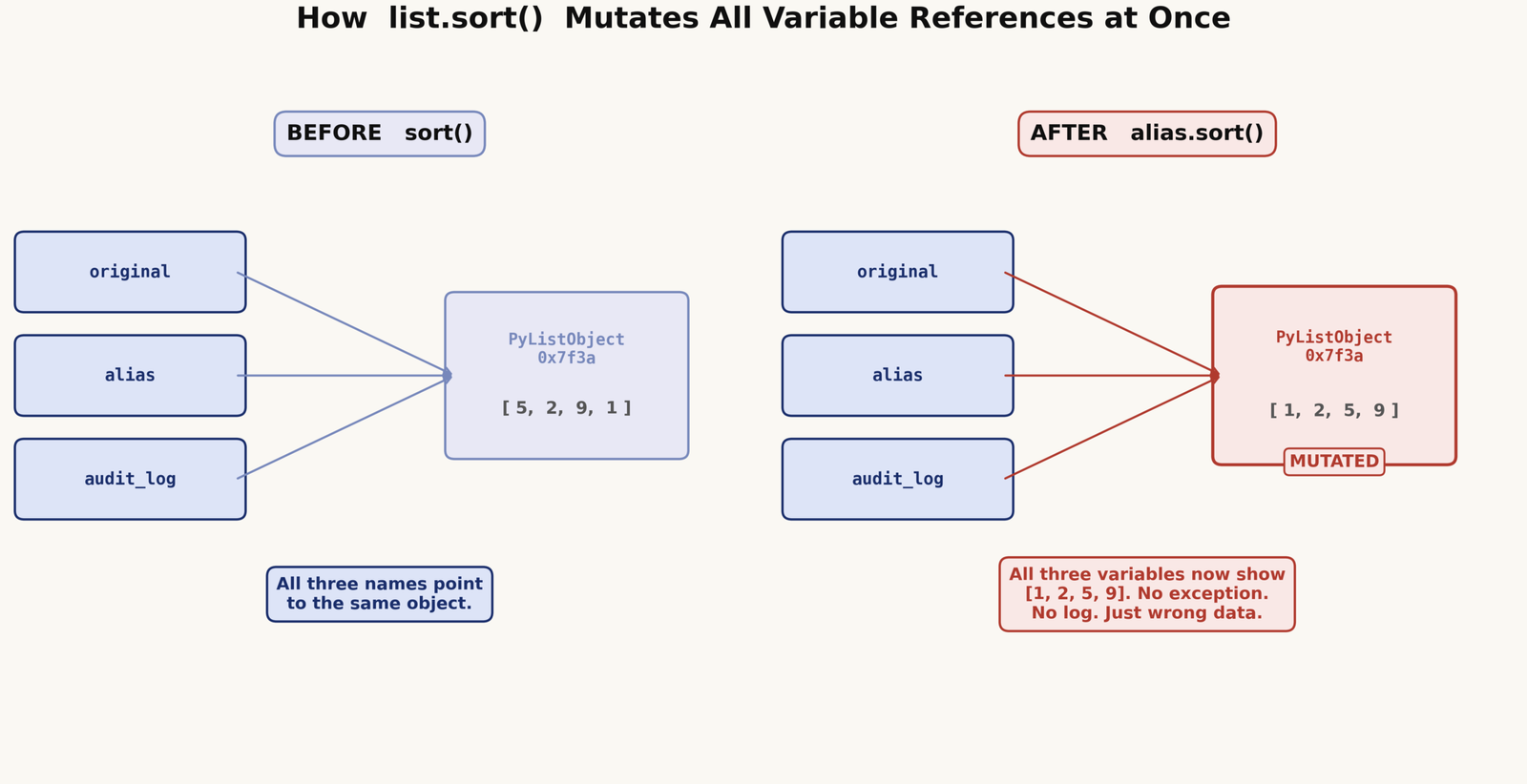
If that audit log was supposed to record arrival order for a reconciliation job or a replay system, the sequence of events is now wrong. The kind of wrong that takes a while to notice. If you want to understand how Python handles object references in general, this article on parameter passing in Python explains the mechanics clearly.
The mutation happens silently. There is no exception, no type error, and no indication in the sorted list itself that it was produced by mutating shared data. Tests that only check the output of a function will pass. Only a test that also checks the original input after the call will catch this.
What CPython Does in Memory During sort() and sorted()
To understand why the mutation reaches all aliases, it helps to look at what a Python list actually is at the C level. CPython represents a list as a struct called PyListObject. It holds a pointer to an array of pointers — one pointer per element — along with a size count. The actual elements live elsewhere in memory.
You can read more about how CPython differs from other Python implementations in this comparison of CPython, Jython, and IronPython.
/* CPython — Objects/listobject.c (simplified) */
typedef struct {
PyObject_VAR_HEAD
PyObject **ob_item; /* array of pointers to the list's elements */
Py_ssize_t allocated; /* how many slots are allocated */
} PyListObject;
When list.sort() runs, Timsort rearranges the pointers inside ob_item. The element objects on the heap do not move. Only the order of pointers changes — inside the one PyListObject that all your variable names are pointing to. Every name that holds the address of that struct immediately sees the new order.
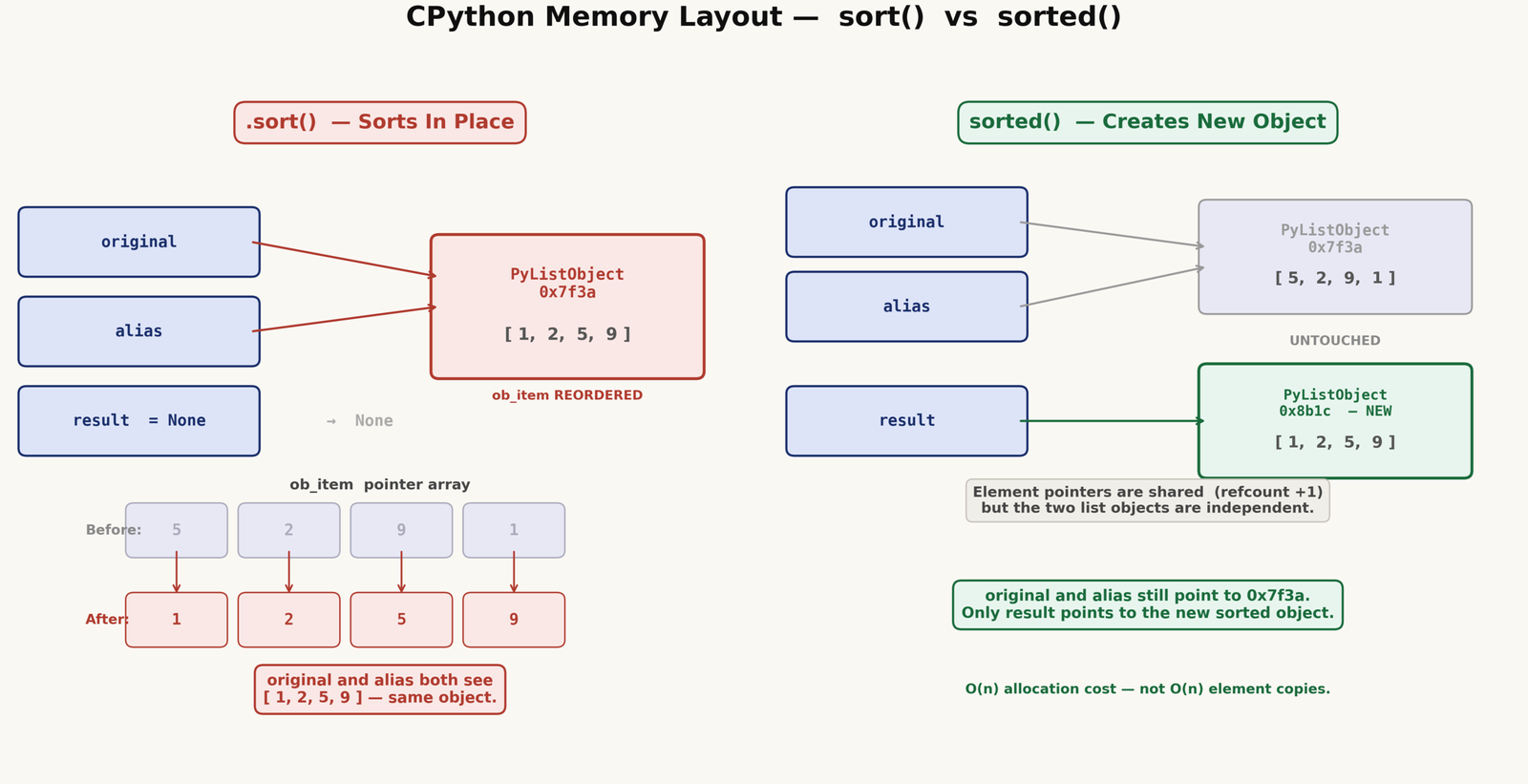
When sorted() runs, it creates a new PyListObject, copies the element pointers into it (incrementing reference counts along the way), and then sorts that new object. The original PyListObject is never touched. This is also why sorted() is safe to use with shared data — it never modifies the thing it was given. Python’s reference counting is covered in more detail in the Python garbage collection article if you want to understand how reference counts work in this context.
What the GIL Actually Guarantees During list.sort() — and Where the Common Explanation Goes Wrong
A widely repeated claim states that CPython’s Timsort drops the GIL at internal checkpoints, which would allow other threads to see a partially sorted list mid-operation. That is not accurate for standard CPython, and it is worth being specific about why.
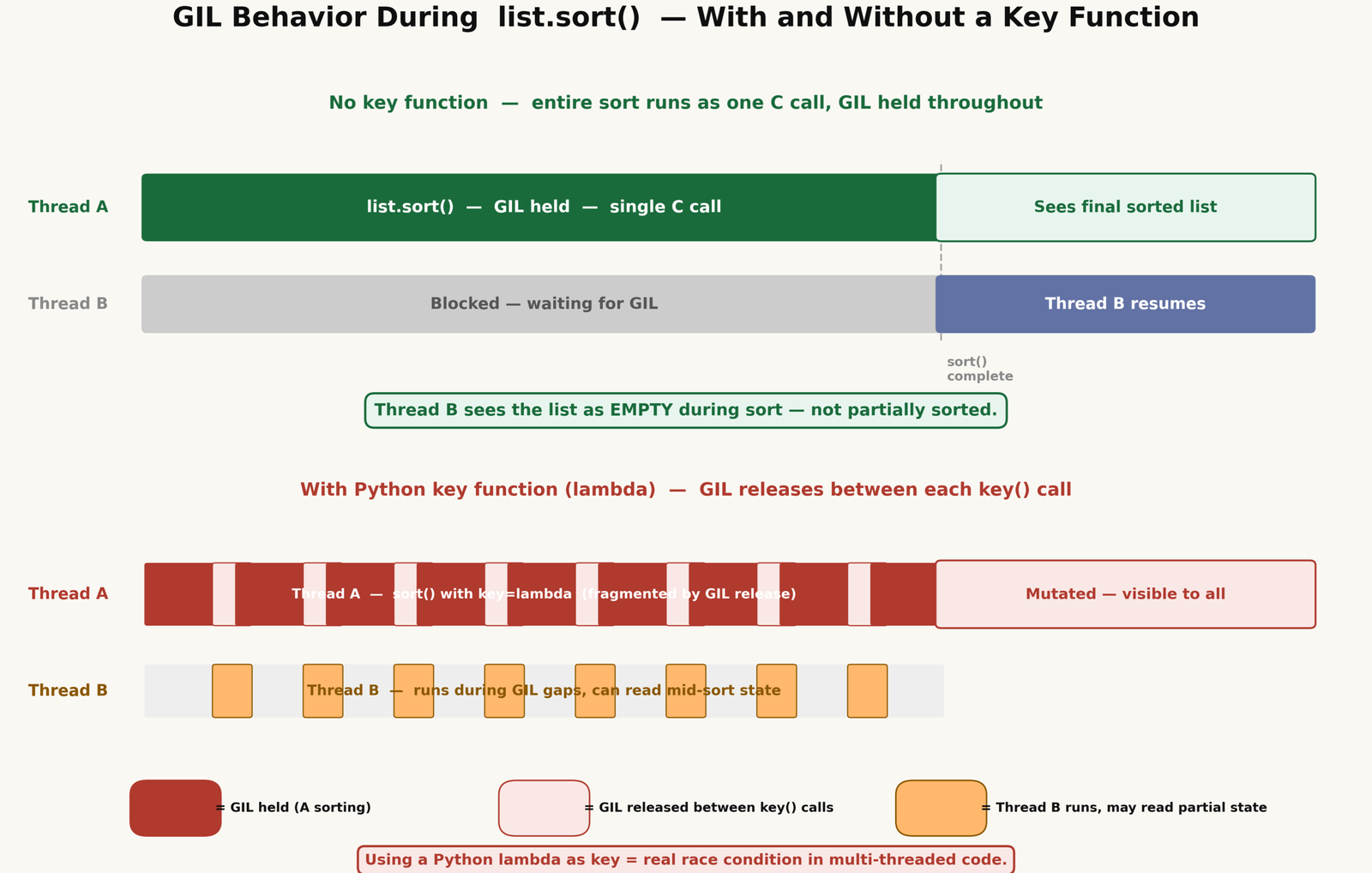
When you call list.sort() without a Python key function, the whole operation runs as a single C function call. The GIL is held throughout. No other Python thread can execute while the sort is running. As an implementation detail of CPython, the list appears empty to other threads during the sort — not partially sorted, just empty — and the final sorted result becomes visible all at once when the operation finishes.
The picture changes when you use a Python-level key function, such as key=lambda x: x.score. Every time Timsort calls that lambda, it executes Python bytecode, and the GIL can be released between those calls. During those windows, another thread can read the list while it is mid-sort. So partially sorted views are possible — but only when a Python key function is involved.
If you sort a shared list with a Python lambda key in a multi-threaded service, other threads can read the list in an intermediate state between comparisons. If you use no key or a C-level key like operator.attrgetter, the GIL is held and no partial state is visible. In either case, the list is permanently mutated after the sort — which is the real problem, regardless of threading.
The actual risk: permanent shared mutation, not a torn read
Whether the GIL drops during the sort or not, the end result is the same: once sort() finishes, the list is reordered and every reference to it sees the new state. If that list lives in a cache, or was passed in as a parameter, every other part of the code that holds a reference now has different data than it started with. No exception is raised. Nothing is logged. The scope and lifetime of Python variables explains the reference model that makes this possible.
How This Bug Plays Out in Production — A Step-by-Step Incident
The following is a reconstruction of a pattern that comes up regularly in Python backend post-mortems. The details are illustrative, but the structure of the bug is real.
products.sort(key=lambda p: p.revenue, reverse=True) in the handler. The products variable comes from an in-memory cache. The code works fine in testing, the review passes, and it ships.id(cached_list) before and after the endpoint runs. They match. The fix is one word — .sort() becomes sorted(). The investigation took four weeks; the fix took ten seconds. Python’s id() function is exactly what you need for tracing this kind of object identity problem.The fix is never the hard part with this kind of bug. What costs time is that the symptom — data in the wrong order — is easy to mistake for a logic error in a completely different part of the system.
Why sorted() Works Better in Data Pipelines
When data flows through a sequence of functions — filter, sort, transform, take the top N — each function ideally leaves its input unchanged. That way, you can test each step in isolation, pass the same input to multiple paths, and trust that the data at each stage is what you put in.
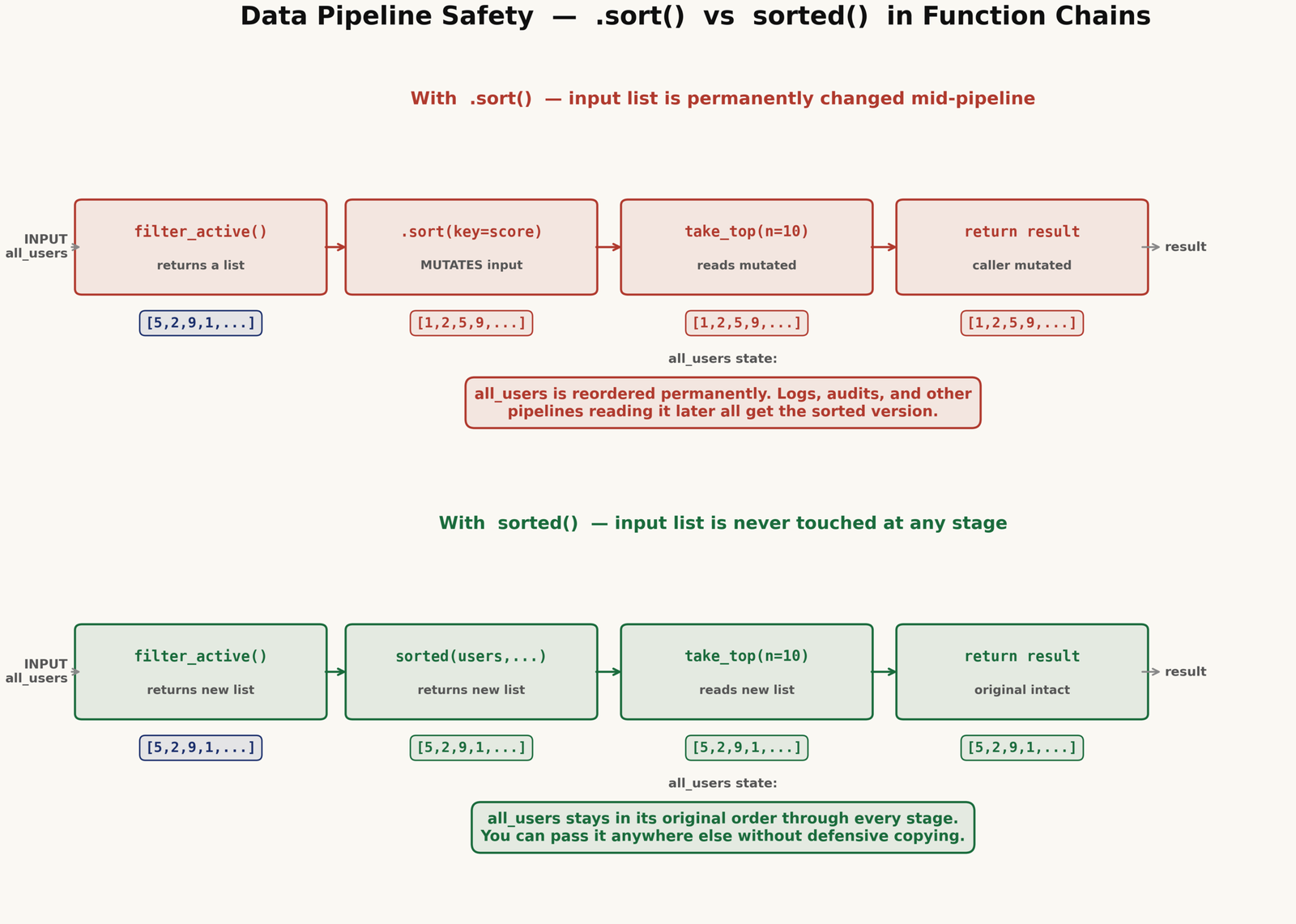
sorted() fits naturally into this model. .sort() does not. If you want to write non-mutating list transformations, list comprehensions are a good tool to combine with sorted() for the same reason.
# Each function returns a new list without touching its input.
def filter_active(users):
return [u for u in users if u.is_active]
def rank_by_score(users):
return sorted(users, key=lambda u: u.score, reverse=True)
def take_top(users, n=10):
return users[:n]
result = take_top(rank_by_score(filter_active(all_users)))
# all_users is untouched. You can still use it, log it, or pass it elsewhere.A function that uses sorted() can be tested by asserting the input list is unchanged after the call. This is not possible with .sort() — the mutation happens to the test fixture itself, and running the test twice on the same data gives different results the second time.
sorted() also enables safe memoization
Functions that do not mutate their inputs are much safer to memoize with functools.lru_cache. If a function calls .sort() on its input, the input has changed before any cache hit could be evaluated — you either get a cache miss (wasteful) or a cached result that was built on a different version of the data (wrong). sorted() avoids both problems.
Performance: Is sorted() Actually Slower?
Yes, slightly — and the reason is straightforward. sorted() allocates a new list object and copies element pointers before sorting begins. That allocation has a cost. For small-to-medium lists, the cost is in the range of microseconds. For very large lists in tight loops, it becomes measurable. If you are working on broader performance work, this Python optimization guide covers profiling and measurement techniques.
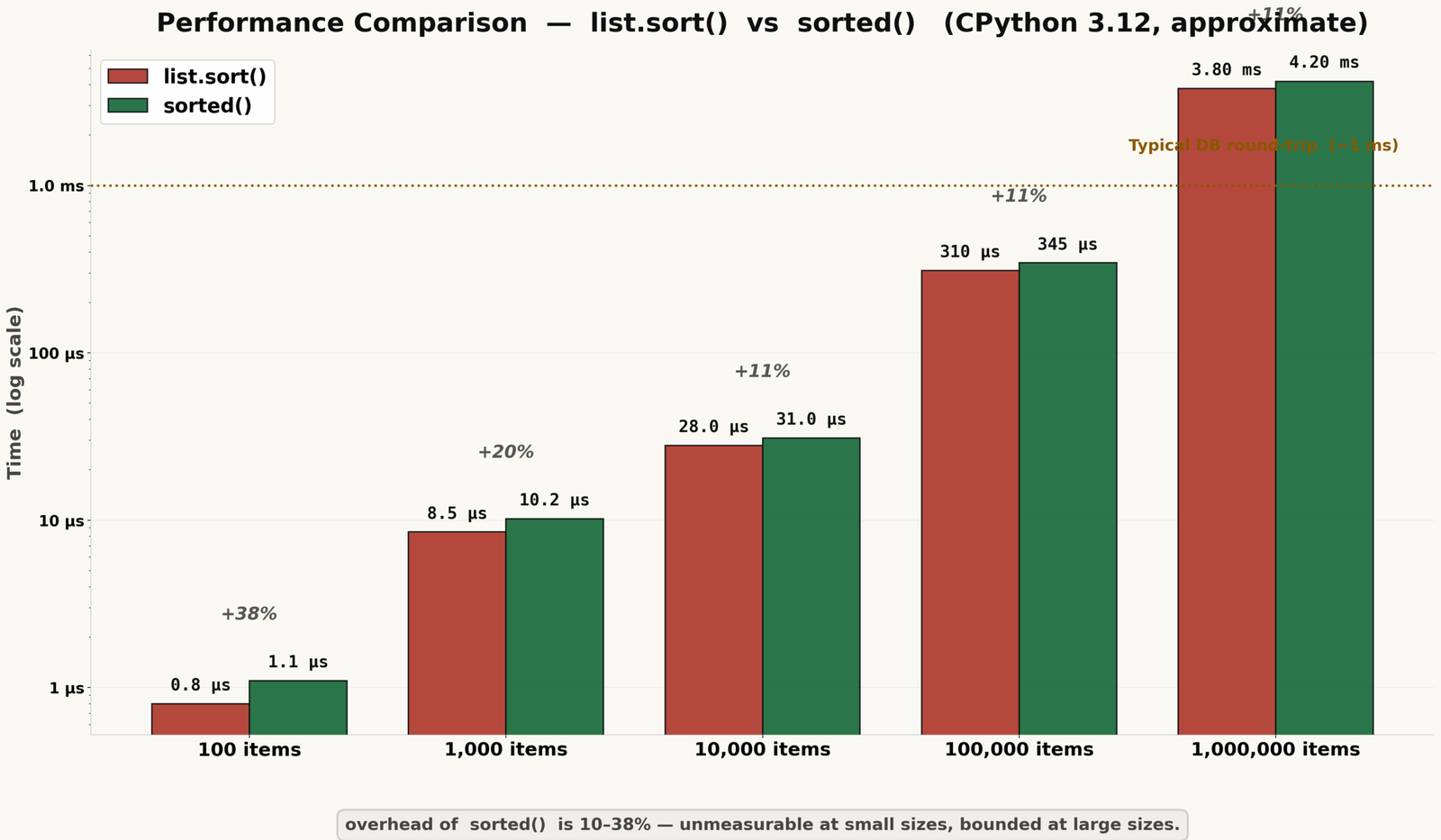
The overhead is roughly 10–15% regardless of list size, because the sorting itself — the O(n log n) comparison work — dominates in both cases. At one million elements, the gap is around 40 ms. If you are sorting a million-element list in a request handler, the sort is the least of your problems — that data should be sorted at the database level. You can read about how Python’s sorting algorithm works, including why Timsort performs well on partially sorted data.
The allocation cost of sorted() does not grow with the number of refactors you do. The mutation risk of .sort() does — every new function or handler that receives the list adds another place where the mutation can cause an unintended side effect.
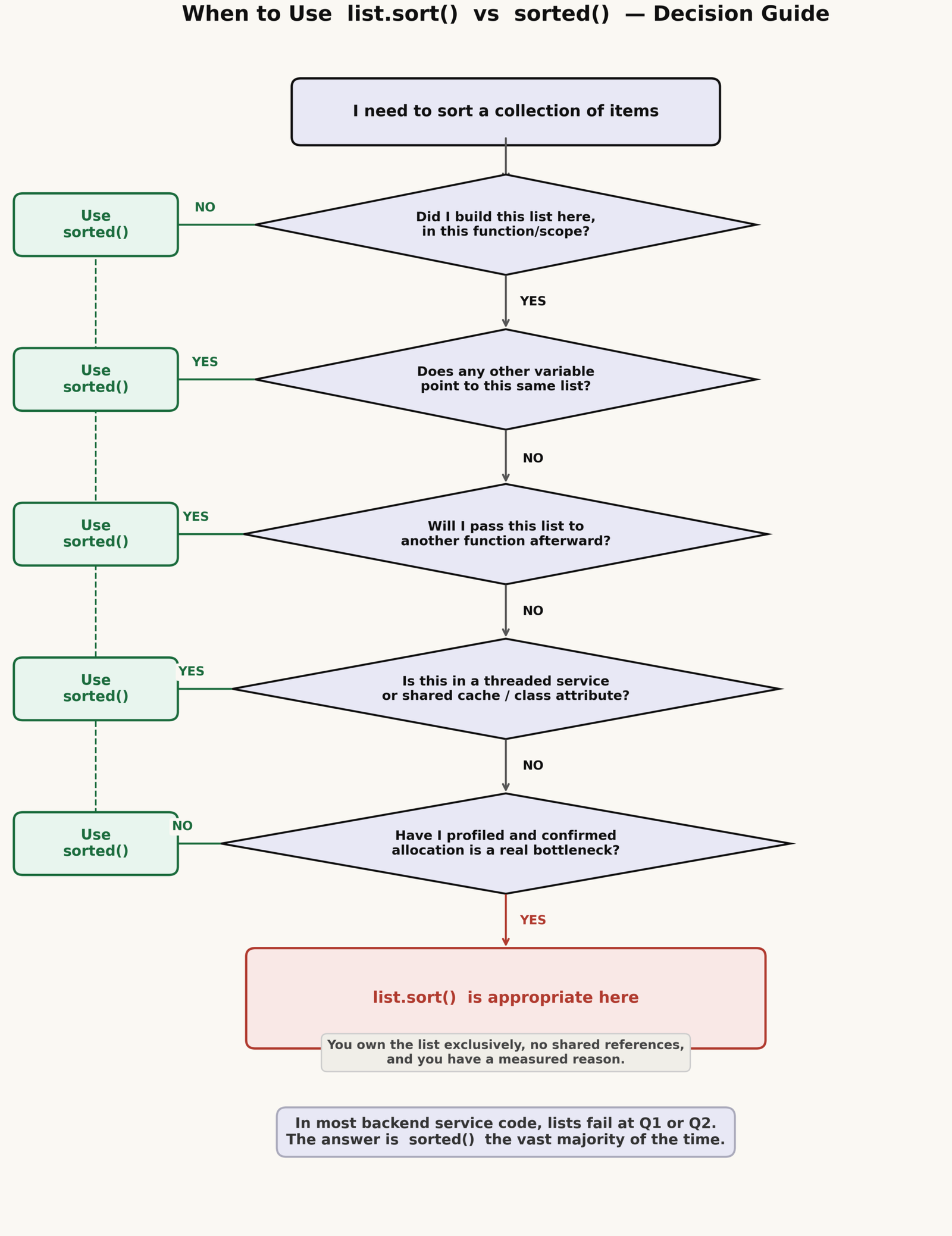
When list.sort() Is Actually the Right Call
There are cases where .sort() is genuinely appropriate. The criteria are narrow, but they exist.
Use list.sort() when all of the following are true:
sorted() shows up as a real bottleneck. Not assumed — measured. This is rare at typical API list sizes.Use sorted() in these situations:
- The list came in as a function parameter. You do not own it.
- The list lives in a cache, class attribute, or module-level variable.
- You need to sort the same list in two different ways for two different uses.
- You want to write a test that asserts the input is unchanged after the function runs.
- The data passes through multiple stages, each of which may filter, sort, or transform it.
- Multiple request handlers might access the same data concurrently.
# Avoid: sorting, then creating a copy anyway
def get_sorted(items):
items.sort() # mutates caller's list
return sorted(items) # then pays the allocation cost too
# You got the worst of both: mutation + allocation.
# Avoid: manual copy + sort when sorted() does the same thing
result = items[:]
result.sort()
# This is identical to sorted(items).
# Two lines instead of one, and less clear.
# Avoid: trusting sort()'s return value
result = items.sort() # result is None
print(result[0]) # TypeError — comes up more often than you'd expectsorted() Works on More Than Lists
One practical advantage that gets overlooked: sorted() accepts any iterable. In real service code, data does not always arrive as a list — it might come from a generator, a database cursor, a set, or a dict.keys() view. The Python lists guide covers the list type itself, but sorted() works across all of these without any changes to the calling code.
| Input type | sort() available? | sorted() works? | Output | Notes |
|---|---|---|---|---|
list | Yes | Yes | new list | Both work; sorted() is safer in shared contexts |
tuple | No — immutable | Yes | new list | Tuples have no .sort() method |
set | No | Yes | new list | sorted() gives deterministic output; sets have no order |
dict.keys() | No | Yes | new list | View objects do not have .sort() |
| Generator | No | Yes | new list | sorted() exhausts the generator and sorts the result |
| Custom iterable | No | Yes | new list | Any object with __iter__ works with sorted() |
If you write code that uses sorted() throughout, your sort calls will keep working when the data source changes type. Switch a list to a generator or a query result, and sorted() handles it. .sort() calls become AttributeErrors at runtime.
A Note on Sort Stability — Both Functions Guarantee It
Both list.sort() and sorted() use Timsort, which is a stable sort. That means equal elements maintain their original relative order after sorting. If you sort user records by department name, users with the same department appear in the same order relative to each other as they did in the original list.
This is guaranteed by the Python language specification — not just CPython’s implementation — and it applies to both functions equally. It has been guaranteed since Python 2.2. Neither function is more or less stable than the other.
Quick Quiz — 10 Questions on sorted() and sort()
result = my_list.sort(). What does result contain?.sort() on it. What does the caller’s original list look like after the function returns?sorted() but not with list.sort()?list.sort() with no key function on a shared list. What do other threads see during the sort?list.sort() release the GIL, allowing other threads to run between operations?sorted(items) using list.sort()?list.sort() and sorted() use internally?list.sort() a clearly appropriate choice?Summary
list.sort() — risks
- Mutates all aliased references without warning
- Permanently changes cached or shared list objects
- With a Python key function: allows GIL release between comparisons
- Cannot be used on generators, tuples, sets, or dict views
- Returns None — using the return value is a common error
- Makes functions harder to test in isolation
sorted() — what you get
- Original input is always untouched
- Works on any iterable, not just lists
- Functions that use it can be tested cleanly
- Safe to use on shared or cached objects
- Fits naturally into multi-step pipelines
- Return value is always the sorted list
Use sorted() by default. Switch to .sort() only when you own the list outright and have measured a real performance reason to do so. In most service code, neither condition holds often enough to justify the habit of reaching for .sort() first.
Frequently Asked Questions
sorted() is a little slower because it allocates a new list before sorting. For small and medium lists — up to a few thousand elements — the difference is measured in microseconds, which is below the noise floor of a typical database call or HTTP request. For very large lists in tight computational loops, the difference becomes measurable, roughly 10–15%. The right approach is to profile your specific workload rather than assume one is always faster. At normal API-layer list sizes, the choice rarely has a measurable effect on request latency.
Partially. When list.sort() runs without a Python key function, it holds the GIL throughout and other threads see the list as empty during the sort — not partially sorted. When a Python lambda or other key function is used, the GIL is released between each key call, which can allow another thread to read the list mid-sort. In either case, the GIL does not prevent the actual problem: after the sort finishes, the list is permanently reordered and every reference to it sees the new state. That mutation is visible to all threads immediately.
Python 3 removed the cmp parameter from both sorted() and list.sort(). The replacement is the key parameter, which takes a function that extracts a comparison value from each element. If you genuinely need a two-argument comparator — for example, when porting Python 2 code — functools.cmp_to_key wraps it into a key function that both sorted() and list.sort() accept. Note that using a Python-level key function (or a comparator via cmp_to_key) does allow GIL releases between comparisons in multi-threaded code.
Yes. sorted() accepts any object that implements the iterator protocol — generators, range objects, dict key views, sets, database cursor results, and custom classes with __iter__. It exhausts the iterable, collects all elements, and returns a sorted list. list.sort() is a method on list objects only. If you change a data source from a list to a generator or query result, sorted() keeps working while .sort() raises an AttributeError at runtime.
Yes, both are guaranteed stable by the Python language specification — not just CPython’s implementation. A stable sort preserves the original relative order of equal elements. For example, sorting a list of records by department leaves records within the same department in the same order they started. This guarantee applies equally to sorted() and list.sort(), across CPython, PyPy, and any other compliant Python implementation. It has been guaranteed since Python 2.2.
Further Reading
If you want to go deeper on any of the topics covered here, these are worth reading.
The official guide covering key functions, the reverse parameter, stability guarantees, and decorated sort patterns. The authoritative source on both functions.
The C implementation of PyListObject, list_sort_impl(), and the Timsort entry point. Useful for verifying GIL behavior and ob_item manipulation directly in source.
Tim Peters’ notes on the design of Timsort, including the adaptive merge strategy and why it performs well on real-world data that tends to be partially sorted.
The official FAQ section on which built-in operations are thread-safe, what the GIL covers, and what it does not. Worth reading before writing any multi-threaded Python service.
The accepted PEP for free-threaded CPython builds. Relevant to how thread-safety for list operations will change as no-GIL builds become more available.






Leave a Reply